Modern large AI models — those that are based in the cloud and accessible to users via web interfaces, smartphone applications or APIs — are mostly multimodal (A2A, anything to anything — which includes the usual T2T, text to text, mode for chatting with bots, and the conversion of a verbal prompt into an image, T2I, text to image, and image recognition with a detailed description — I2T, image to text, and much more). At the input, they accept text queries, and pictures or even videos, and are often able to give out not only text in response, but also an image, a video, a phrase or a melody spoken by a synthesized voice. Perhaps this is due to the extremely high power of the deep neural networks underlying such models, the number of parameters at the inputs of artificial neurons in which already amounts to trillions (GPT-4 has 1.76 trillion). It is clear that to ensure any adequate speed of signal transmission through such neural networks, their digital images must be entirely placed in ultra-fast RAM – which, in turn, requires hundreds and thousands of GB. This is why generative AI models that are truly interesting in terms of live communication cannot be launched on a home PC – the same DeepSeek R1 in the original (full-featured) version requires at least 1543 GB of video memory.

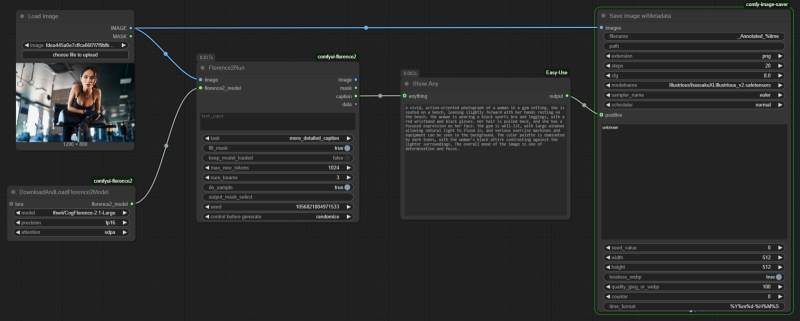
An example of fruitful artistic collaboration between the operator and the local PC: on the left is the original still life with cheese and honey from the free photo bank PXHere; in the center is its analogue, created by the FLUX.1 [dev] model based on a text prompt generated by another AI agent specialized in image recognition, Florence2; on the right is the result of manual masking of the central object and drawing a plush bee in its place by the FLUX.1 [fill] model.
Of course, there are “compressed” (distilled) versions of large models, and even specially “quantized” ones (when instead of 32- or 16-bit floating-point numbers, the weights at the perceptron inputs are presented in a more compact form, with 8 or 4 bits, and even this is not the limit), so that some DeepSeek-R1-Distill-Qwen-7B with 7 billion parameters will take up 4.5 GB of video memory, and DeepSeek-R1-Distill-Qwen-1.5B with one and a half billion parameters will take up about 1 GB. Correctly conducted distillation of models allows preserving the distinctive features of the original in a given area: thus, the mentioned DeepSeek-R1-Distill-Qwen-1.5B, which is a “compressed” version of Qwen2.5-Math-1.5B (moreover, during the compactification of this version of Qwen, originally created by the developers of Alibaba Group, the answers generated by DeepSeek R1 were used – that is why the name of both original models are present in the name of the distilled version), trained to solve mathematical and logical problems, surpasses the fully functional versions of GPT-4o-0513 and Claude-3.5-Sonnet-1022 in a number of relevant tests. At the same time, the “distillate” can be executed on a local PC that meets, for example, the specifications of Copilot+ PC – even in the absence of a discrete video card. But of course, one cannot expect true universality from such compactified and specialized AI agents: Turing forbids you from starting conversations with DeepSeek-R1-Distill-Qwen-1.5B about matters other than mathematics!
And yet, it makes sense to launch locally even obviously non-universal AI agents — to solve various applied problems that for one reason or another are irrational or simply inconvenient to perform in the cloud. In this Workshop, we will consider one of such practical applications of small generative models, namely, their feasible assistance to their colleagues (also, in essence, small language models with an initially narrow application area — SLAM), specialized in creating images. It turns out that by involving not one AI, but two or more, but with different specializations, in the task of transforming an artistic concept into an image, you can achieve more outstanding results in a relatively short time — than if you manually bring to condition in some graphic editor (especially in the absence of the appropriate skills and experience) an image that is not entirely satisfactory to the operator, generated by the same FLUX.1.
The reasoning process and the output of the final answer are demonstrated by a compact AI model of the Qwen 1.5B family, optimized for execution on a neural coprocessor (NPU in a system-on-a-chip; not even a discrete GPU!) on a Copilot+ PC with Windows Copilot Runtime (source: Microsoft)
⇡#Under control
In the series of “AI Drawing Workshops” that we have been publishing for almost two years, the main problem of machine generation of images based on text prompts has been mentioned more than once: the excessively high uncertainty of the results obtained. Uncertainty is literally in everything: from the quality of the image as a whole (it is precisely to counteract this scourge that prompts for Stable Diffusion are usually accompanied by obligatory sayings like “masterpiece, best quality, elaborate atmosphere”) to its composition and the level of execution of individual details (we look at the human hands in the original SD 1.5 image, without LoRA and text inversions, and weep – and with them too, in general, just a little less often). Yes, relatively quickly the community of AI drawing enthusiasts developed automated tools for generating images based on a certain template – OpenPose for ControlNet, for example: with their help, you can take the work of a living artist or just a photo from real life – and do “approximately the same, but with an AI flavor.” However, reproducing someone else’s picture directly or with minimal variations is not very interesting in itself, and in practice it is not always necessary. Much more often – say, in order to adequately illustrate another post on a social network or publication in an online publication, or even simply create a portrait of your own fantasy character for another tabletop role-playing game – you need to get an image from the machine based on a certain sample, and not a more or less slavish AI copy of it.
Before the FLUX.1 model with its highly developed (thanks to its reliance on the T5 “explanatory” AI submodel) “understanding” of natural speech, prompt engineering — that is, composing a text prompt that would ensure the generation of an image with a high degree of compliance with the composition and quality conceived by the operator — was almost akin to black magic. It was necessary to select keywords in a special way (specific for almost every checkpoint!), often completely intuitively, and arrange them in the right sequence. This is precisely why the ConrolNet family of tools were so enthusiastically received by the enthusiast community: they provided much more confident control over the generation — although the quality of it itself for both SD 1.5 and SDXL did not always meet the operator’s expectations. After receiving a more or less suitable picture, it was necessary to either repeatedly redraw the obviously unsuccessful parts of it using the same AI model (the inpainting procedure), or manually edit the picture in GIMP, Photoshop or another graphic editor – if the operator had the appropriate skills, of course.
It makes sense to use a combined cyclogram, in which nodes for automated text description of the original image (bottom left) and for converting the received AI hint into an image “based on” the original (everything else) work sequentially, on fast PCs – then it won’t be so offensive if image recognition in the next specific case turns out to be not very successful
Now that FLUX.1 has been available for over six months and has managed to acquire a fair amount of auxiliary tools in the form of various LoRA add-on models, the situation is much simpler. Some ControlNet varieties for FLUX.1 are also available — although, for now, in a smaller assortment than for the Stable Diffusion family — but if you create new images based on existing ones, you can do without them. Roughly speaking, since the new model is strikingly different from the previous ones in its increased meticulousness in terms of following the prompt, now the operator only needs to describe the desired image in detail and strictly in words (by the way, at this stage it is not so important whether it is real or appeared before his mind’s eye) — and launch FLUX.1 in a free search (with random enumeration of the seed) according to this description. If the words themselves are chosen correctly, the desired result will not take long to appear; the relative position of these words (assuming that they do form meaningful phrases and are not simply listed with commas) is no longer so important, as is the presence of additional, not always obvious modifiers – like the already mentioned “masterpiece, by Greg Rutkowsky, HDR, 8K UHD” and so on: the auxiliary neural network T5 will explain to the text-to-CLIP token converter exactly how to recode the received description in order to obtain a corresponding visual result.
But here’s the question: where to get a detailed and strict description of even a completely real, not imaginary picture – especially in English; especially with the understanding that this text will then be used to create a new image by a generative model, i.e. some specificity in the selection of words and the construction of phrases should still be present? The answer suggests itself: it would be logical to delegate this task to another AI, trained precisely to recognize images and to compose adequate verbal portraits of a wide variety of objects. One modern AI will definitely understand another (“other” here, they are inanimate); perhaps even better than the average Homo sapiens. And, strictly speaking, it is not at all necessary to make a garden of narrow-profile models on a local PC for this: online – cloud – tools for converting a picture into a text describing it are available in abundance, starting with the well-known multimodal ChatGPT, Claude or DeepSeek and ending with more modest, specialized ones.
But the beauty of it is that to form an effective text prompt that the FLUX.1 input circuit can process into a set of tokens suitable for generating the desired image, AI bots with half a billion or more operating parameters are simply not needed, as is access to free online MYAMs (they are free for the idle user, not for the one who supports their work in the cloud, and therefore have a natural limit on the number of requests from one IP address for a certain period). It is enough, for example, to have freely distributed and suitable for local launch models created to solve machine vision problems. An example is the Project Florence family, developed at Microsoft. For example, the Florence-2 variant, trained on 900 million “image – text description” pairs, offers a sufficiently spacious context window and high performance to both compose detailed long hints (which FLUX.1 perceives so well) and respond to each request even on a not very powerful PC in a time calculated at most in tens of seconds.
Searching for the necessary extensions for ComfyUI by keywords via Manager is organized very conveniently
⇡#What do you see in this picture?
The ComfyUI working environment, already familiar to readers of our “Workshops”, offers all the necessary tools for integrating such local image recognizers (cloud ones, by the way, too, via API with the input of an identification key, but they have their own specifics, and we will not consider them in this material). In detail about how to deploy and configure this working environment on a local PC running Windows with a discrete Nvidia graphics adapter specifically for working with models of the FLUX.1 family, was discussed in the 11th and 12th issues of the “AI Drawing Workshop”. Let us only emphasize that to access Florence-2, we will need an updated working version of ComfyUI with an active Manager extension. The tool of interest to us in this case is the “Florence2Run” node, the ability to add it to the working cyclogram appears after installing the corresponding extension. It is trivial to do this in the functional installation of ComfyUI – just call Manager from the main menu, click on the “Custom Nodes Manager” button in its interface, and then in the search line in the window that opens with a list of available extensions, start typing the word “caption” (“description”). Enthusiasts of the working environment we use have already offered quite a few tools for converting images into text, but the ComfyUI-Florence2 extension by kijai is one of the most popular and, perhaps, the easiest to use.
Another important reminder: after installing a new extension (the “Install” button in the corresponding line of the list), the system will prompt you to reboot the work environment server. Before doing this, it makes sense to return to the Manager menu and click the “Update all” button there – so that both ComfyUI itself and all other previously installed extensions are updated to the most current versions. Since the work environment is currently developing extremely actively (due to a sharp surge of interest from enthusiasts in the local implementation of several very good models with open scales for converting text and pictures into videos that appeared almost simultaneously), updates appear much more often than at the end of 2024, say.
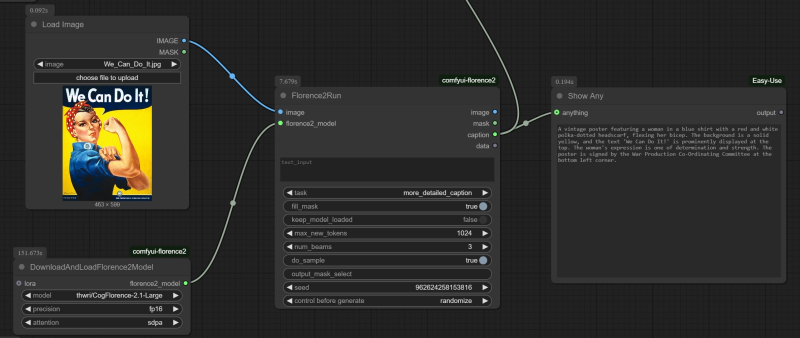
A fragment of a sequence diagram that generates a text description of the original image using the “Florence2Run” node, and then renders this text to the operator using the “Show Any” node.
After the reboot is complete — both the ComfyUI server and its web interface — we open a new window for creating a cyclogram, double-click the mouse in the empty field and in the search line of the node selection menu that appears, start entering “Florence2Run”. Select the desired one — and here it is, the main window of the image recognition tool, i.e. for converting an image (and, optionally, a hint clarifying the process — if the node is used in masking mode) into text (or into some service image, the same mask). Now we need to supplement the key node with a means of calling the model: to do this, from the “florence2_model” input on its left side, we will drag a connecting line with the mouse — and simply release it somewhere in the empty space of the working field. A menu will appear with node options suitable for organizing such a connection; among them, we will select the one called “DownloadAndLoadFlorence2Model”. There is no tautology in this name: after selecting a specific model in the drop-down menu of this node — for example, Florence-2.1-Large — there is no need to perform any additional actions, such as manually downloading the corresponding file and placing it in a specific directory. After the cyclogram is completed and launched for execution for the first time, the system itself will determine that the required model is missing — and will automatically pull it from the online repository into the subfolder “LLM” of the “models” folder in the root directory of ComfyUI that it created itself (“download”), and then load it into video memory for execution (“load”).
And to complete the cyclogram to a fully operational state, there is not much left: it is enough to drag a new connection with the mouse from the “image” input on the left side of the “Florence2Run” node, release the button in the same way, and select “Load Image” in the menu that opens. The result of the AI image recognizer’s work, for starters, will be a text with a description of the proposed image: to see this text, we will use the “ShowAny” node from the ComfyUI-Easy-Use extension package (which is probably already installed by those who did rapid prototyping with us with the FLUX.1 model, and if not, it is easy to install it via Manager). Since we will connect “ShowAny” to the “caption” output on the right side of the “Florence2Run” node, the text description will be displayed there. In this node itself, from the drop-down menu “task”, you need to select the task “more_detailed_caption” — the result of its execution will be a fairly lengthy and detailed description of the picture in natural language, suitable for transmission — in the form of a text hint — to the input of the FLUX.1 generative model.
The first execution of the cyclogram with the nodes “Florence2Run” and “DownloadAndLoadFlorence2Model” may take several minutes – it all depends on the width of the Internet channel that the operator has.
⇡#And we can do it!
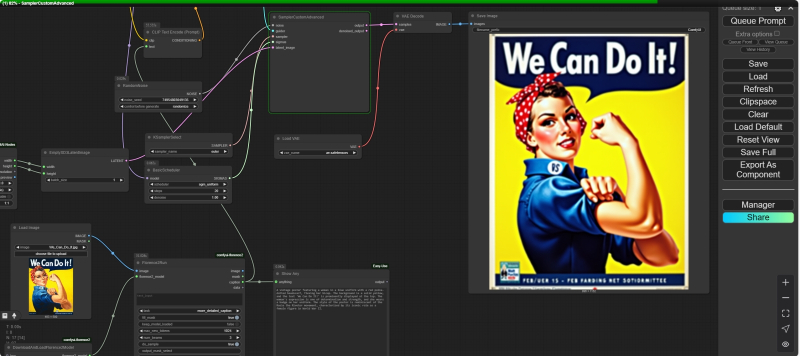
In fact, that’s it, in the first approximation: this text can then be used as a hint for generation with the FLUX.1 model: copy and paste into the adjacent browser window, where the corresponding cyclogram is open. The block with the “Florence2Run” node can be quite acceptable integrated into the generation process to save yourself the unnecessary “Ctrl+C”/”Ctrl+V” movements, but the thing is that the model generating the image description is also generative: its output will be slightly different each time. And therefore it makes sense – considering, in addition, that this mini-cyclogram is executed very quickly – to run it several times, copying the obtained results at least into “Notepad”, in order to then compile a more complete, comprehensive description from them. However, in this case – and we checked about a dozen random seeds – the images each time come out very, very similar, right down to the typography and text design, although its parameters are clearly not set by the hint. It must be assumed that this iconic poster was part of the training set for both the Florence and FLUX.1 family models, so that one “understands” the other even from such a brief description, as they say, at a glance.

Left – FLUX.1 [dev] generated image from Florence2 generated description of “Rosie the Riveter” poster without any additions; center – all parameters are the same, including seed, but LoRA Illustration V2 is added with 1.0 strength; right – same, but with 0.5 strength
Let’s check this by slightly changing the working parameters of the image-generating model — the weights at the inputs of its perceptrons — by applying LoRA to it. Since the poster is a drawing, albeit a quite realistic one, we will use the Illustration V2 version available on the Civitai portal: generally speaking, there are plenty of mini-models there to emphasize this particular artistic style, and we chose this one almost at random. We will take the same cyclogram for generation as in the previous “Workshop”, where the nodes “Unet Loader (GGUF)” for the quantized Q8.0 model FLUX.1 [dev] and “Power Lora Loader (rgthree)” for loading the LoRA models themselves were used. We will set the following generation parameters: canvas aspect ratio — 3:4, image size — 0.5 Mpix, sampler — dpmpp_2m, scheduler — sgm_uniform, steps — 20, and with a seed of 574671788216636, choosing the “strength of impact” (parameter “Strength”) LoRA equal to 1.00, we will get just like the original picture, and not an almost exact copy of it. This is still a recognizable poster with the same characteristic inscription, but its typography is different, and Rosie is turned in the other direction, and in general the style of the picture is closer to the American pin-up genre, and not to an agitational drawing. But if you reduce the impact strength of the Illustration V2 mini-model to 0.5, you get an interesting compromise – the image as a whole will be more attractive than without LoRA at all (and this is understandable; the FLUX.1 family generally copes better with displaying photorealistic images than drawings), especially in terms of hands and folds in the blouse fabric, but it will also be more faithful to the original.
⇡#Closer to reality
Now let’s digress from the iconic poster, which, due to its indisputable presence in training databases, is a priori “closely familiar” to all generative models dealing with visual images, and let’s see how good Florence2 is at describing images for which FLUX.1 has no clear reference. To do this, let’s download an image of a girl in a gym from the PXHere website, which offers free illustrations with open rights for commercial and non-commercial use — and let’s see how accurately our AI working in tandem will be able to reproduce it. First, let’s slightly modify the cyclogram with the “Florence2Run” node: to save both the annotated image and its generated description at the same time, let’s use another extension for ComfyUI with a self-explanatory name — Save image with generation metadata. It is installed again through Manager, where it is found by name (the author is giriss, just in case). The “Save Image w/Metadata” node from this extension initially includes fields for manual input of the positive and negative parts of the hint. You should convert one of these windows into an input “connector” for receiving data – by right-clicking on the node itself and selecting “Convert widget to input” – “Convert positive to input” from the menu, then connect the “output” of the “Show Any” node to the “positive” input that appears on the left side, in which the description of the proposed image appears, generated by the Florence2 model.
By adding another node, “Save Image w/Metadata,” to the four nodes we are already familiar with, we will be able to save the original image together with its text description in a single PNG file, and you will be able to see the text block at the very beginning of this file even without launching the ComfyUI working environment — just open it in any content viewer (hex viewer/editor); like the one that is called in the FAR file manager by pressing “F3”
What else can the Florence2Run node do? Since the generative model it relies on was developed for image recognition, the locally launched MYAM also copes well with this task. The task menu of the node in question contains the regions_caption and density_region_caption modes: the first is for recognizing well-spaced objects, the second is for densely grouped ones. If you attach the standard Preview image node to the image output on the right side of Florence2Run, then after processing one of the two specified options, the original image will appear in it with rectangles superimposed on it, which limit the areas occupied by the recognized objects.

On the left is the original photo of a girl in a gym from the free photo bank PXHere; on the right is a FLUX.1 visualization (without any LoRA) of the first attempt to describe it using Florence2.
But this method will work properly only for not very realistic images. A real apple, for example, will inevitably create reflections on the objects around it: albeit weak, but a decent generative model like FLUX.1, trained on a huge array of photographs, has an “idea” of them, so an orange lying on a white tablecloth, which casts a slightly greenish glow on this tablecloth (because an apple was lying there before), will look unnaturalistic. For this reason, working with masks usually involves removing from the image not only the object to be replaced, but also its immediate surroundings, so that the generative model can then draw something else in its place in the most natural way it can. The enlarged mask also allows you to redraw an object with a change in shape and size: for example, an AI mask generated using the “skirt” hint will not allow you to “change” a drawn girl’s clothes from a skirt to trousers – not all the necessary areas will be captured by it; but a manually created one will do just fine.
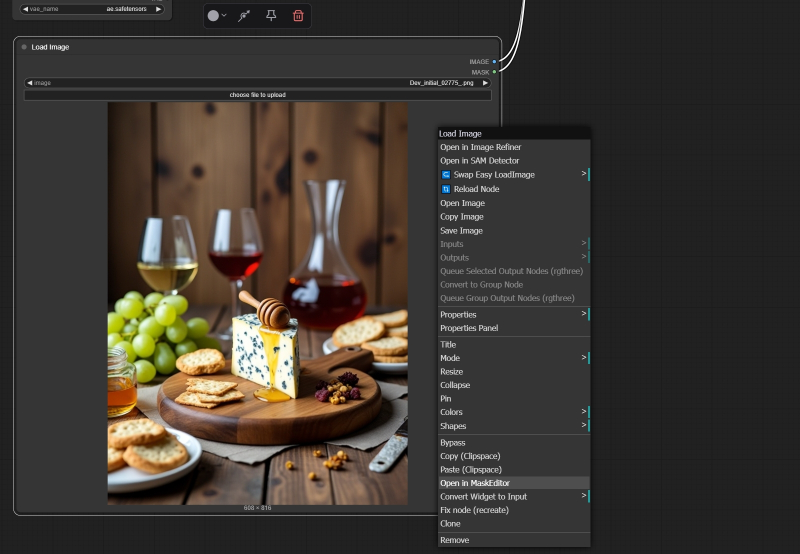
The unpretentious basic node “Load Image” in the current version of ComfyUI offers integrated functionality for creating masks – access to the corresponding editor is opened via the right-click menu
⇡#Manual control
Let’s demonstrate with an example how this is done in the case of FLUX.1 — especially since for intelligent re- and finishing drawing (inpainting and outpainting functionality, respectively), the Black Forest Labs company itself has already offered a specialized model FLUX.1-Fill-dev. This model, however, takes up almost 24 GB in its original form — but enthusiasts have created GGUF-quantized versions for it; in particular, flux1-dev-Q8_0.gguf; of a more forgiving size (about 13 GB) and is practically indistinguishable from the original in the quality of the images created. The file downloaded from the link above should be placed in the models/unet directory in the ComfyUI working directory structure, together with other GGUF models, and then, instead of our standard cyclogram for FLUX.1 [dev], use the flux-fill-inpaint-example.json file from the official guide to implementing AI redrawing in the ComfyUI environment. There is nothing extremely complicated there; moreover, instead of the usual key node “SamplerCustomAdvanced” for the actual generation, the classic node “KSampler”, which is remembered from the Stable Diffusion models, is used, which has separate inputs for the positive and negative parts of the hint – for the negative part in the case of FLUX.1, of course, you will have to enter an empty line. It is also important to note the unusual combination of parameters: for the “redraw” version of this model, it is suggested to set the guidance parameter to 30.0 (instead of the standard 3.5 for Flux.1 [dev]), sampler to “euler”, scheduler to “normal”, steps to 20, and “cfg” in the “KSampler” node to 1.0.
The masking itself is done using the tools built into the modest-looking “Load Image” node. After loading the image to be redrawn, right-click on it and select “Open in MaskEditor” from the menu that appears. The image will open in a laconic but effective mask editor, where you should select the right brush size, paint over the object to be redrawn (plus its immediate surroundings), and then click “Save”. As a result, a gray spot will appear on the original image – it is where the new generation will take place. But what exactly will be determined by the text field of the positive part of the hint: there you need to briefly and succinctly describe what exactly the operator wants to see in place of the spot that has just appeared. The FLUX.1 fill model used for re- and redrawing is trained to adopt the style and composition of the image being changed from the part of it that is not covered by the mask, and therefore what appears as a result instead of the initially removed object most often fits harmoniously and naturally into the final image. By the way, all the examples we have given here are traditionally available for downloading as an archive with PNG images containing the necessary cyclograms, at this link.
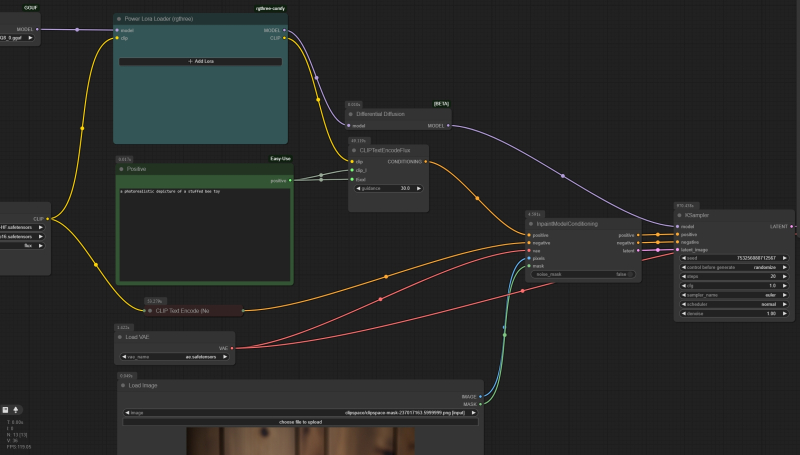
A fragment of the flux-fill-inpaint-example.json reference cyclogram, which shows nodes and parameters that are not typical for the FLUX.1 [dev]/[schnell] model, but are quite justified in the case of FLUX.1 [fill]
So, it turns out that locally executed MNMs have a very limited application in the case of image generation – for describing third-party images, segmentation, object detection and, it seems, that’s all? Perhaps, this is true – the capacities (expressed in the number of active parameters of a multilayer neural network) of generative models suitable for running on a gaming PC and on a hyperscale cloud server are too incomparable. And yet, enthusiasts continue to develop local T2T bots, and especially actively with the advent of distilled agent models specialized in solving fairly narrow problems. Which ones and for what purpose – we will try to find out in the next issues of our “Workshop”!
⇡#Related materials
- Mistral AI has unveiled a tool that will turn any PDF document into a text file for AI.
- Microsoft has busted a gang of hackers who tricked AI into drawing inappropriate fakes of celebrities.
- Abuse of AI makes people stupider, scientists have found.
- Christie’s has announced an exhibition of paintings created using AI.
- Google will start labeling user photos that have been “interfered” with by AI.