Microsoft did not rest on the laurels of its partnership with OpenAI and released three new artificial intelligence systems belonging to the Phi family – language and multimodal models.

Image Source: VentureBeat/Midjourney
Three new projects in the Phi 3.5 line include a large language model of the base version Phi-3.5-mini-instruct with 3.82 billion parameters, a powerful Phi-3.5-MoE-instruct with 41.9 billion parameters, and Phi-3.5-vision-instruct with 4.15 billion parameters – it is designed for image and video analysis. All three models are available under the Microsoft brand on the Hugging Face platform under the MIT license – they can be downloaded, fine-tuned, modified and used commercially without restrictions. In tests they are not inferior to, and sometimes even superior to, such competing products as Google Gemini 1.5 Flash, Meta Llama 3.1 and even OpenAI GPT-4o.
Llama 3.1 and even OpenAI GPT-4o.
Here and below image source: VentureBeat / Midjourney
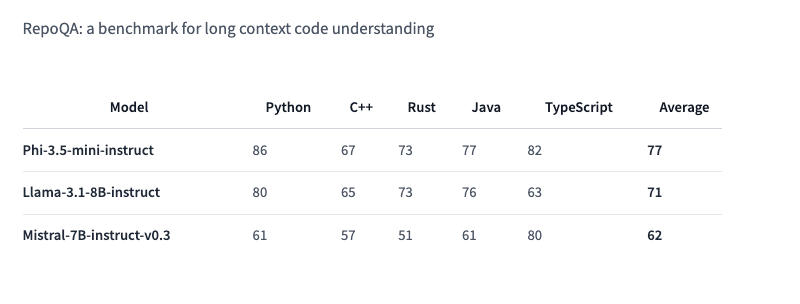
Phi-3.5 Mini Instruct is optimized for environments with limited computing resources. This is a lightweight model with 3.8 billion parameters. It is designed to execute instructions and supports a context length of 128 thousand tokens. The model copes with tasks such as code generation, solving mathematical problems and logical reasoning. Despite its compact size, the Phi-3.5 Mini Instruct is quite competitive in multilingual and multi-turn language tasks. In the RepoQA test, which is used to evaluate “understanding of long context code,” it outperforms, in particular, Llama-3.1-8B-instruct and Mistral-7B-instruct.
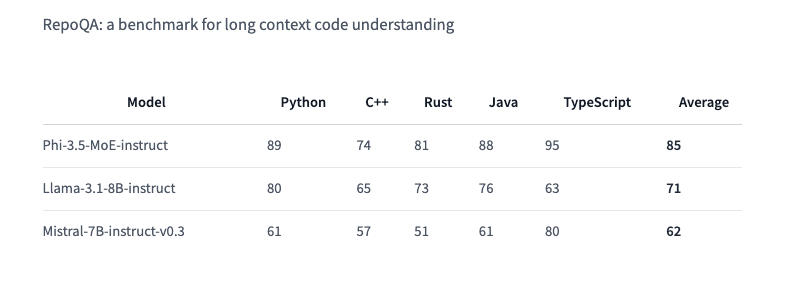
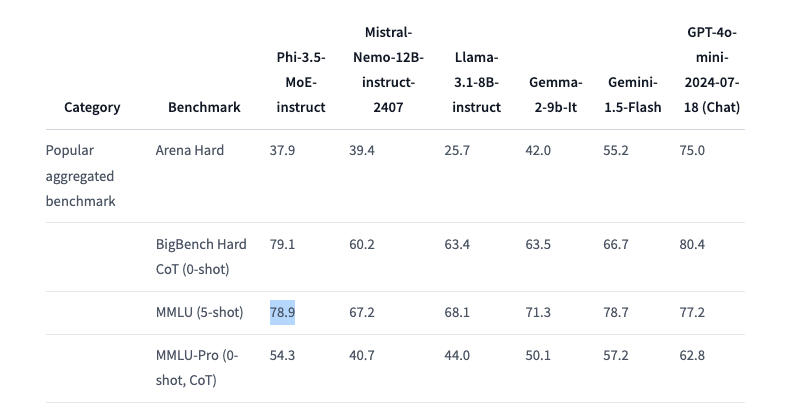
Phi-3.5 MoE (Mixture of Experts) combines several models of different types, each of which specializes in its own task. The architecture of the model is characterized by 42 billion active parameters and context support of 128 thousand, which allows it to be used in demanding applications – it is noteworthy that the Hugging Face documentation talks about only 6.6 billion active parameters. Phi-3.5 MoE performs respectably in math, code generation, and multilingual query understanding, often outperforming larger models in some benchmarks, including RepoQA; it also beat the GPT-4o mini in the MMLU (Massive Multitask Language Understanding) test in the natural and technical sciences, as well as the humanities and social sciences at various levels of knowledge.
Phi-3.5 Vision Instruct combines text and image processing capabilities. It is suitable for recognizing pictures and symbols, analyzing charts and tables, and compiling video summaries. Vision Instruct, like other Phi-3.5 models, supports a context length of 128 thousand tokens, which allows it to work with complex multi-frame visual tasks. The system was trained on synthetic and filtered public datasets, focusing on high-quality, high-density reasoning datasets.
Phi-3.5 Mini Instruct trained on 3.4 trillion tokens using 512 Nvidia H100-80G accelerators over 10 days; the Phi-3.5 MoE mixed architecture model was trained on 4.9 trillion tokens using 512 Nvidia H100-80G units in 23 days; it took 6 days to train Vision Instruct for 500 billion tokens using 256 Nvidia A100-80G AI accelerators. The entire Phi-3 trio is available under the MIT license, which allows developers to freely use, modify, merge, publish, distribute, sublicense, or sell copies of the products. The license contains a disclaimer: the models are provided “as is” without warranty of any kind – Microsoft and other copyright holders are not responsible for any claims, damages or other liabilities that may arise from the use of the models.