Panmnesia has been designing CXL DRAM pools for quite some time: in 2023, it demonstrated a system that leaves behind all RDMA-based solutions and provides access to 6 TB of RAM. But large amounts of memory today, in an era of increasingly complex AI models, are needed not only and not so much by processors, but by accelerators, which are a priori deprived of the ability to upgrade on-board RAM. At CES 2025, the company demonstrated a solution to this problem.
According to Panmnesia developers, performance when training large-scale AI models depends precisely on the volume of on-board memory of the accelerators: instead of tens of gigabytes, terabytes are required, and installing additional accelerators can be too expensive, given that the computing power will be redundant.

Source here and below: Panmnesia
The CXL system demonstrated at the exhibition is built on the latest Panmnesia controller with support for CXL 3.1. In bidirectional mode, access latency was less than 100 ns and is approximately 80 ns.
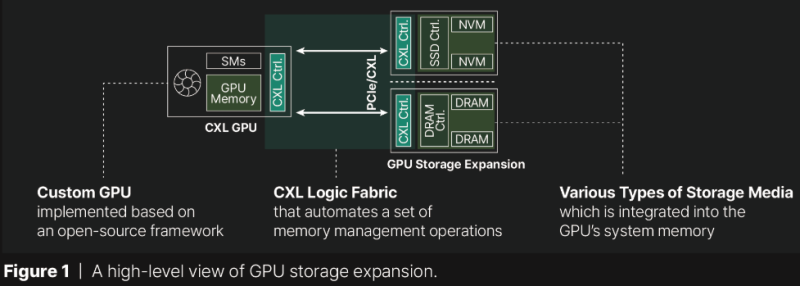
The key to success here lies in the proprietary implementation of CXL 3.1, including the software part, thanks to which GPUs can access a shared memory pool using the same load/store instructions as when accessing on-board HBM or GDDR.

However, the technology requires a proprietary CXL Root Complex controller on board the GPU, one of the most important parts of which is the HDM decoder, which is responsible for managing the memory address space (host physical address, HPA), so already released accelerators will not be able to work directly with the Panmnesia system.

However, the technology looks promising. It has already attracted attention from AI companies as a potential way to reduce the cost of data center infrastructure.