Startup d-Matrix has created a Corsair AI accelerator optimized for fast batch inference of large language models (LLMs). The accelerator architecture is based on modified SRAM cells for in-memory computing (DIMC), operating at speeds of about 150 TB/s. The new product, according to the company, is distinguished by performance and energy efficiency, writes EE Times. Mass production of Corsair will begin in the second quarter. Investors in d-Matrix include Microsoft, Nautilus Venture Partners, Entrada Ventures and SK hynix.
D-Matrix focuses on low latency packet inference. In the case of Llama3-8B, the d-Matrix server (16 four-chip accelerators consisting of eight cards) can produce 60 thousand tokens/s with a latency of 1 ms/token. For the Llama3-70B, a d-Matrix rack (128 chips) can produce 30K tokens per second with a latency of 2 ms/token. d-Matrix customers can expect to achieve these metrics for packet sizes on the order of 48-64 (depending on context length), d-Matrix product lead Sree Ganesan told EE Times.

Image source: d-Matrix
Performance is optimized to run models with up to 100 billion parameters per rack. According to Ganesan, this is a realistic use case for LLM. In such scenarios, the d-Matrix solution provides a 10x advantage in interactivity (time to token acquisition) compared to solutions based on traditional accelerators such as NVIDIA H100. Corsair is targeting models smaller than 70 billion parameters suitable for code generation, interactive video generation or agent AI that require high interactivity coupled with throughput, power efficiency and low cost.

Early versions of the d-Matrix architecture used MAC blocks based on SRAM cells, supplemented by a large number of transistors for multiplication operations. Addition was performed in analog form using bit lines, current measurement and analog-to-digital conversion. In 2020, the company released the Nighthawk chiplet platform based on this architecture. “[Nighthawk] has demonstrated that we can significantly improve accuracy over traditional analog solutions, but we are still a couple of percentage points behind traditional GPU-type solutions,” d-Matrix CEO Sid Sheth told EE Times. .
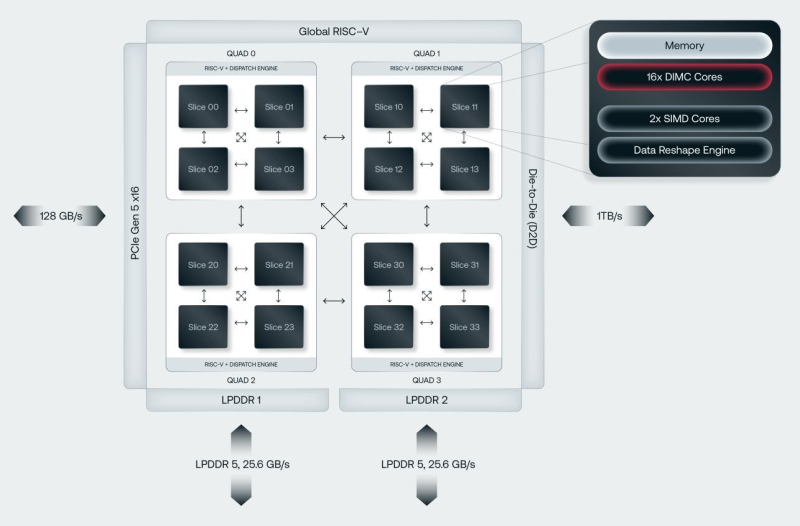
However, potential customers did not like the possible decrease in accuracy with this approach, so Corsair was forced to opt for an all-digital adder. ASIC d-Matrix includes four chiplets, each of which contains four computing units connected via DMX Link in a each-to-each scheme, and one scheduler and RISC-V core. Inside each computing unit there are 16 DIMC cores consisting of sets of SRAM cells (64×64), as well as two SIMD cores and a data conversion engine. A total of 1 GB of SRAM is available with a throughput of 150 TB/s.

The ASIC is integrated with 128 GB LPDDR5 (up to 400 GB/s) via an organic substrate (no expensive silicon interposer). Although the current generation of ASICs includes only four chiplets precisely due to substrate limitations, their number will increase in the future. External ASIC interfaces are represented by standard PCIe 5.0 x16 (128 GB/s) and proprietary DMX Link interconnect (1 TB/s) for combining chiplets.
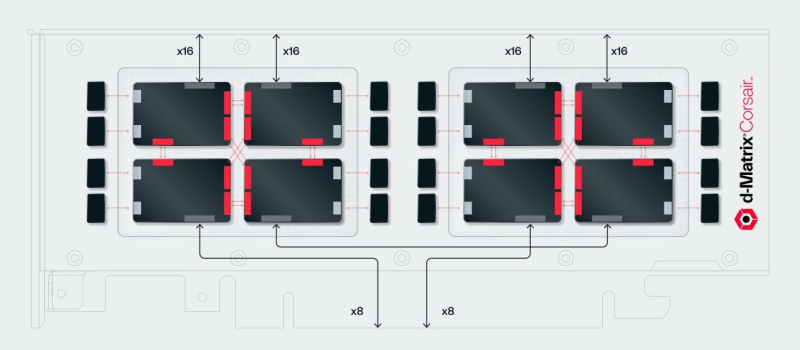
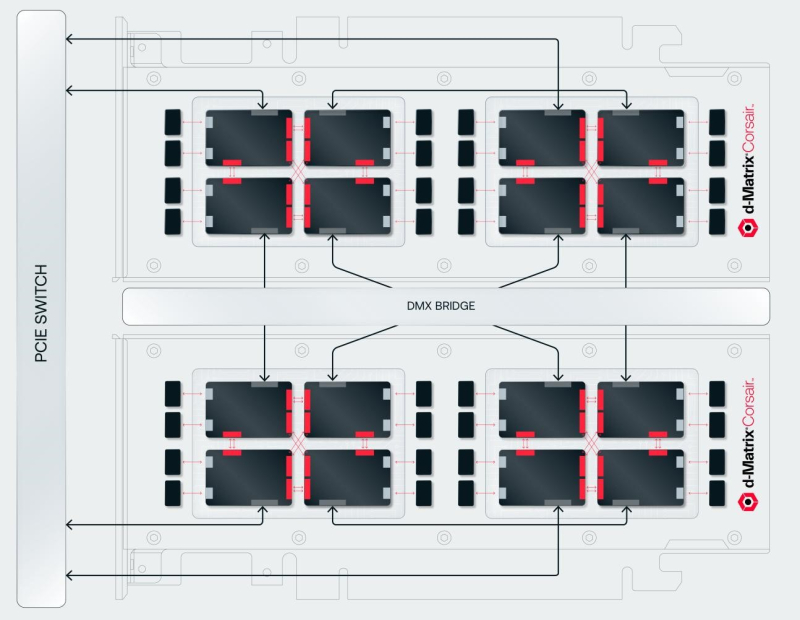
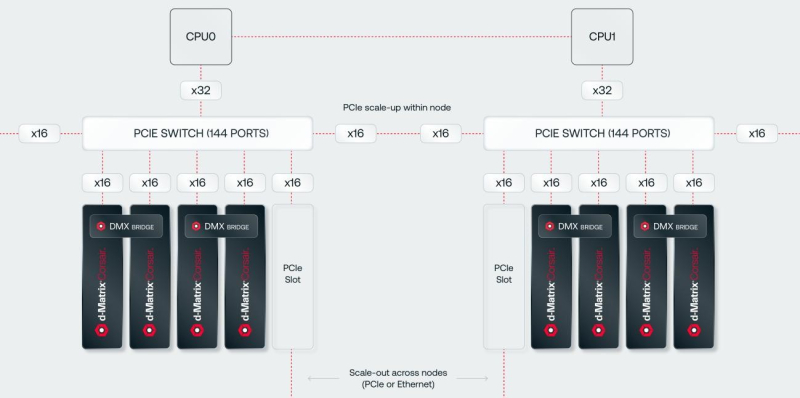
Corsair’s FHFL card includes two d-Matrix ASICs (eight chiplets in total) and has a TDP of 600 W. The accelerator works with OCP MX (Microscaling Formats) data formats and provides up to 2400 Tflops in MXINT8 calculations or 9600 Tflops in the case of MXINT4. Two Corsair cards can be connected via a 512GB/s DMX Bridge. These, according to the company, are sufficient to enable tensor parallelism. Further scaling is possible via PCIe switching. This is why d-Matrix works with GigaIO and Liqid. You can fit eight Corsair cards in one chassis, and 64 cards in a rack that will consume about 6-7 kW.
D-Matrix is already developing the next generation Raptor ASIC, due out in 2026. Raptor will be focused on “thinking” models and will receive even more memory by placing DRAM directly on top of the computing chiplets. Raptor SRAM chiplets will also move from TSMC’s 6nm process technology, which is used to make the Corsair, to 4nm without significant changes to the microarchitecture. The company says it spent two years working with TSMC to create a 3D packaging system for the next generation of ASICs.
As EETimes notes, the d-Matrix software development team is twice the size of the hardware development team (120 versus 60). The company’s software strategy is to make maximum use of the open source ecosystem, including PyTorch, OpenAI Triton, MLIR, OpenBMC, etc. Together they form the Aviator software stack, which is responsible for converting models into d-Matrix numeric formats, applying proprietary rarefaction methods to them, compiling them, distributing the load across cards and servers, and managing model execution, including servicing a large number of queries.