The essence of the physical process of distillation is the separation of a mixture of substances, each of which in its pure form is characterized by its own boiling point. Roughly speaking, when the distillation cube is heated to a certain limit, chemical compounds with a boiling point below this limit remain there, and those with a higher boiling point exit through the pipe in the form of steam and then condense in the receiving flask. The volatile substance being distilled in this way, freed from the low-boiling fractions of the mixture, becomes more concentrated – and acts (if it has some biochemical action) more effectively; see, for example, the classic film miniature by director Gaidai “Moonshiners”.
Distillation of AI models (model distillation, also called “knowledge distillation”) also comes down to reducing the volume of the original model by discarding everything unnecessary. In other words, how this procedure will be carried out depends on what exactly is not needed to solve a given problem — and what the distilled version of the original model will ultimately be capable of. Only a certain part of the knowledge that the model initially had and was encoded in the form of weights at the inputs of the perceptrons that form it is transferred from the source to the distillate. The result is most often (although it depends on the training data set, of course) a highly specialized, but extremely economical in terms of system requirements AI agent, and an effectively organized ensemble of such agents is capable of demonstrating results sometimes no worse than a cumbersome and resource-intensive source (it would seem, what does DeepSeek have to do with it, the developers of which were suspected of “data theft” – in fact, in the unauthorized distillation of OpenAI models through a public API). And, apparently, distillation in the foreseeable future will become an extremely popular direction for further improvement of generative models – simply because the usual methods of their operation, as they further increase in cumbersomeness, seem to be an excessively costly matter in all respects.
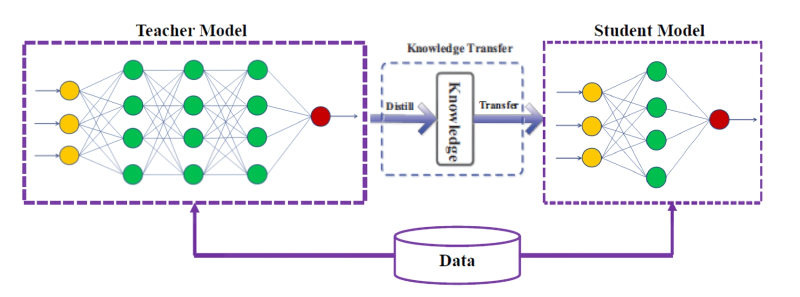
Distilling models is fundamentally not a tricky business (source: ResearchGate)
⇡#Study, student!
The history of AI distillation goes back to the work of researchers from Cornell University with the simple name “Model Compression”, which described how a huge language model at that time, formed by hundreds of base classifiers, was used to train another, “thousands of times more compact and faster” model, which ultimately demonstrated no worse results. The training procedure itself was a classic supervised learning, only the trained model was checked not against some set of reference data compiled by people, but against the answers that a large language model gave to the same questions. In this way, information was transferred from a large, complex model (the “teacher”) to a small and fast one (the “student”). This approach was then deepened and developed in another classic work for this field, Distilling the Knowledge in a Neural Network, created by employees of the Google lab in Mountain View, California.
Distillation can be performed in two fundamentally different variants: in the first, most straightforward one, training is performed until the student learns to reproduce with high accuracy the best (in the opinion of the people supervising the process) answers of the teacher to the questions asked. This, of course, allows almost completely replacing the large model with the small one when processing queries on a given topic – however, it greatly reduces the variability of answers, which may be unacceptable in many situations. Another variant of distillation is training the student to reproduce the entire or almost entire range of answer options available to the teacher to the question posed (teacher’s output distribution). In this case, the maximum similarity of the small and large language models is achieved (again, within the framework of the given topic), but the student trained in this way will generally consume more resources. Distilled models are most often used where either the computing power of the device, or time (answers must be obtained with minimal delay), or both are insufficient for the execution of full-fledged, original ones.
How is distillation carried out technically? The first stage involves the preparation of a large initial model; its classical training on an extensive and diverse array of data – with the achievement of a level of quality of the answers that is acceptable for practical use. Quality means both an extremely high probability of generating a correct answer to the queries being checked, and at the same time an extremely low percentage of hallucinations. Such a well-trained model – as the practice of the last three years of the active phase of the AI revolution clearly shows – requires more resources, both hardware and energy, the broader the area of competence of the generative AI created in the described way.

An illustration from the pioneering work “Model Compression” shows how much the choice of the algorithm for generating synthetic data (and they are used, there is no escape if the operators do not have enough real data to train the student model) affects the accuracy of the results produced by the distilled model: here True dist is the conditional distribution of the answers generated by the teacher model, and the other three images show the results of the student model after training on synthetic data generated randomly (Random) or using the NBE and MUNGE algorithms (source: Cornell University)
To understand how exactly the knowledge accumulated by a larger model is transferred to a smaller one, we will have to return to the basic concepts of machine learning, which we have already discussed earlier. Let us recall that modern DNNs are implemented mainly by dense multilayer neural networks, on each of whose perceptrons a procedure that is generally trivial from a mathematical point of view is performed – a weighted summation of the signals arriving at all its inputs. Whether the perceptron then generates its own output signal or not is determined by its activation function. There are many known variants of such functions, and for different layers of a deep network (and sometimes for different sections in a single layer), different activation functions are used – those that are most suitable for solving a given specific problem. In particular, when it is necessary to classify an object – that is, to give a certain probability of what exactly is depicted on the presented neural network from a fixed list of options (a cat, a dog, a wombat or a fire hydrant), the “soft maximum” function, softmax, is used.
In order not to write out here with lengthy explanations of frightening formulas with fractions and exponents, we will formulate in words: at the input, softmax accepts a set of parameters represented by real numbers – conventionally, these are just the output signals from the last hidden layer of a deep neural network – and at the output it assigns a certain probability to each of them: so that the sum of all probabilities is equal to one. It turns out that each object recognized by such a neural network will be assigned to one of the fixed categories with a certain probability (say, “cat” – 4.7%, “dog” – 0.3%, “wombat” – 74.2%, “fire hydrant” – 20.8%), on the basis of which the generative model will make its final judgment. And yes, there is no need to be offended by it if the picture presented for recognition had some kind of warbler that was absent from the working classifier – this is the problem of the people who compiled and marked the training array, and not at all the model itself.
So, the softmax function works as a convolution of the results of processing the input data by the neural network into a probability distribution that allows classifying an object by a discrete field of output parameters. The results of using softmax are usually called “hard labels”, and the input vector of unnormalized (i.e. those whose sum is not equal to one or 100%) values generated by the last hidden layer of the neural network is called a logit or “soft labels” (soft targets, soft labels). The two distillation options mentioned above boil down to the fact that the student model receives as training material either “hard labels” generated by the teacher model (roughly speaking, third-party trainers-operators feed a multitude of requests through the API of someone else’s BNM, and pass the received answers to their own – future distilled – small model), or logits of answers to each question asked. In the second case, obviously, the operators need access directly to the “insides” of the teacher model, but as a result, the student model learns the full (unnormalized!) probability distribution of the original model according to its working classifier, also known as the dictionary, those same “soft labels”.
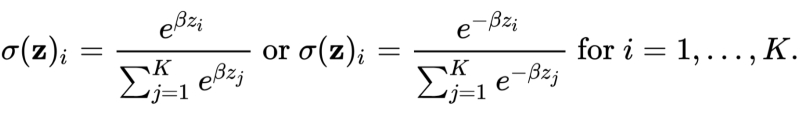
The formula for normalizing a vector of K real numbers using the softmax function is not that complicated (source: Wikimedia Commons)
⇡#Room for optimization
How are “soft labels” better than “hard” ones? Receiving “hard” ones, the student-model builds strictly one-to-one correspondences between the input data and the output: in this picture there is a wombat, the Volga flows into the Caspian Sea, the oak is a tree, etc. In many cases this is not bad at all (and sharply reduces the frequency of hallucinations when answering questions that imply some precise knowledge), but for solving creative problems it is most often categorically unacceptable: the visual diversity of the same wombats, depicted by a model distilled in a “hard” way, will inevitably be extremely meager. But access to “soft labels” forms in the student-model a more complete idea of how the teacher-model makes this or that decision, since probabilities are preserved: this picture, ultimately classified as a “wombat”, was 20% similar to a fire hydrant, and this one is as much as 35%. As a result, the distilled model solidifies, during the training process, more subtle relationships between the classification features of the objects being processed – and this allows it, in turn, to produce higher quality (in the opinion of a living operator) answers to the requests addressed to it.
Actually, this is where the description of distillation as such could be completed – from the point of view of theory. But then comes the most interesting part: practice. This technology of “compactification” of BNM was invented and is widely implemented (especially widely – today, after the incredible hype that was raised around DeepSeek) not out of a purely academic desire to master something new and interesting, but for quite mercantile reasons: distilled models are capable of producing obviously acceptable results with orders of magnitude higher efficiency than the original, full-size ones. It is clear that there is no escape from the costs of the initial training of the full-size BNMs themselves – but their implementation (inference) is also extremely resource-intensive, and on weak “hardware” like a smartphone it is almost impossible. With the exception of models that are extremely modest in terms of the number of parameters, of course, but these days, in essence, no one is interested in them anymore: what is the point of receiving unconvincing, tongue-tied answers from a small model that is running locally, if a large one is available from the same smartphone via the cloud – which will literally tell an entertaining fairy tale and sing a song that it has composed on the spot?
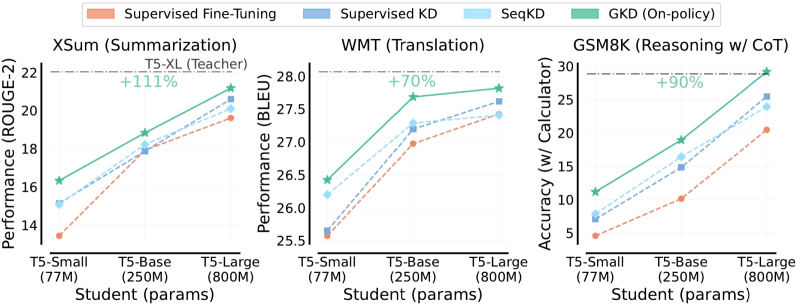
Comparison of different approaches to distilling AI models, listed at the top of the figure and marked with different colors in the graphs: Generalized Knowledge Distillation wins in this case (source: Google DeepMind)
Therefore, recently researchers have been increasingly striving to optimize the distillation process itself — and at once in two vectors: to make even more compact models as close as possible to full-size ones in terms of output quality. For this, different methods are used: for example, it is possible to transmit to the student model not the full logit of the teacher’s answer to each question, but only several maximum positions from it (i.e., only options with a probability that exceeds a certain threshold). And then — if we limit ourselves, for example, to only 5% of the length of each logit (represented, we recall, as a vector made up of real numbers) — the amount of memory required to train the student model will be reduced essentially twentyfold.
Another opportunity to optimize distillation costs comes down to a reasonable choice between the hard labels and soft targets approaches. The former is obviously more economical, since it implies the transfer of only binary question-answer pairs to the student model. In addition, developers not burdened with an excessive tendency to moralizing can use a competitor’s API as a teacher for their distilled model, without asking for formal permission (though still regularly paying for the very fact of access). In the end, the legislation concerning intellectual property rights in the field of AI is frankly raw even in the United States, which still remains the world leader in this field, and even if the fact of such borrowing of a training resource is revealed (especially if this borrowing was cross-border), it is unlikely that the developers of the BNM, which has involuntarily become a teacher, will have any legally formalized claims against the “illegally trained” student. Another thing is that in today’s rapidly deglobalizing world, such borrowing of machine ideas about this very world from generative AI from the camp of a geopolitical rival may backfire on overly agile operators, but this topic goes far beyond the scope of the issue under discussion.
Training with soft targets, in turn, is advantageous in that it is faster, since the student model simply requires less data (or, more precisely, fewer data transfers) — after all, in response to each request, it immediately receives the entire logit, “thought out” for it by the teacher. An additional and less obvious advantage of this approach is the erosion of the distilled model’s categorical confidence in its correctness, which sometimes shines through in dialogues with AI. Having learned from a wide sample that a whole range of answers can be given to each question, differing in probability, the student model will formulate its own conclusions more carefully and gently, allowing for different interpretations and even citing options that contradict each other if their probabilities are close. The obvious disadvantage of the soft targets approach is the need for computing resources during training, which is several times, or even tens of times, greater than in the case of hard labels.
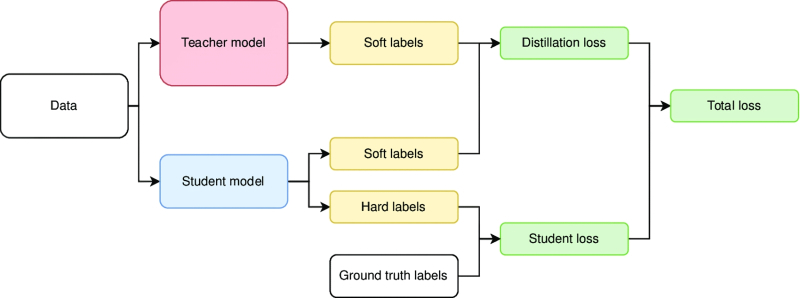
Different distillation approaches require different techniques (source: ResearchGate)
However, both of these approaches have a significant common disadvantage, which manifests itself already at the stage of execution of the trained distilled model. Let us recall that during classical training, the BNM compares its own answers with the sample proposed by the operators, adjusting the values of the weights at the inputs of its perceptrons. The distilled model is actually trained to select the most suitable foreign answer in response to the user’s hint – given by a much more cumbersome, but also superior neural network in capabilities. Once such training is completed, the distilled model is forced to deal not with specially selected questions, but with what its users enter into the dialog box – and there may be anything there, from words that are simply unfamiliar to the system (which were simply not assigned any tokens during the training process) to grammatical and stylistic errors/typos/sloppiness, sometimes simply making the input noisy, and sometimes capable of dramatically changing the meaning of the request (how should we consider the phrase “where to find wings for an old Muscovite” – as a proposal to sketch out a synopsis of a novel in the style of urban fantasy or as a request for help in choosing a car flea market?).
This discrepancy between training and real queries, which the distilled model simply has not been taught to handle on its own (since it was trained, let us emphasize once again, to match the responses of another AI to a limited sample of queries), is called “exposure bias” and is combated in a very obvious way – by establishing feedback between the student and the teacher. Within the framework of this approach, the student model gives answers to queries from the training array, but does not always compare them with the reference ones given by the teacher: sometimes this task is entrusted to the teacher model. The assessment of such independent answers is used to adjust the weights of the student neural network – so as to ultimately arrive at a certain obviously high assessment from the teacher, while maintaining a sufficient breadth of variability in its answers (the distillation method based on an externally determined policy; on-policy distillation).
Today, distillation seems to be an extremely promising direction in the field of generative AI, since the energy and hardware requirements of the most interesting models from the end user’s point of view have long since crossed all reasonable limits, including (and especially) at the stage of their direct use. The algorithms used in this case are constantly being improved – it is enough to mention adversarial distillation, multi-teacher distillation, graph-based distillation, cross-modal distillation, etc. And the longer the high intensity of passion for artificial intelligence lasts, the higher the probability that distilled models will be deployed in the coming years on local AI PCs, AI smartphones and even AI elements of a smart home, thereby reducing the load on the cloud infrastructure and actually allowing to make a robot vacuum cleaner, an autonomous warehouse forklift, or a coffee maker truly intelligent. But why exactly a truly smart coffee maker might be needed in a home, even with distilled AI on board, is a topic for a completely different conversation.
Related materials
- Researchers Train OpenAI’s O1 Competitor in Less Than Half an Hour and $50
- India should become a leader in creating small ‘reasoning’ AI models, says Sam Altman.
- The Register: DeepSeek’s success has shown the importance of smart investments in AI, but the need for infrastructure development will not go away.
- Microsoft suspects DeepSeek of training AI on data stolen from OpenAI.
- Google has introduced a compact language model, Gemma 2 2B, which outperforms GPT 3.5 Turbo.