The GEFORCE 50 line of video cards takes place in the usual direction from the flagship, which is not only a game, but also a request solution, to devices for enthusiasts and, with a fair delay, medium -level products. For logistics reasons, we are forced to delay the testing of the GeForce RTX 5090 and start a series of reviews with RTX 5080, which is successful in our own way. The unique proximity of the second model to its predecessor, the RTX 4080 Super, according to formal characteristics will allow us to weigh the advantages of the new Blackwell architecture and understand why, along with GPU generations, not only the price of one FPS, but also, under certain conditions, is pure performance.

The GeForce RTX 5080 presents the Palit Gamerock video card.
⇡#GB20X graphic processors
In the new generation of graphic processors, NVIDIA again eliminated the formal division into two branches of architecture – accelerators for datas centers, on the one hand, and products for game PCs and workstations, on the other. HPC solutions still have a number of quantitative and functional differences from mass GPU, but those and others belong to the same Blackwell line, named after American mathematics David Blackwell.
The chips come out of the TSMC 4NP line, which is the second 5-nanometer process, adapted to NVIDIA’s requests, while Apple and Intel are already ordering large crystals made at 3 Nm norm. In fairness, we note that the discrete graphics of competitors were also not ready for migration by 3 Nm, but these companies have a large reserve for the growth of the specific performance of the GPU due to architectural changes (which have already been demonstrated by second -generation ARC accelerators). And in general, AMD and Intel are not yet intended to compete with “green” prices and performance in the highest echelon. But for NVIDIA, the delay on the old photopolyographic node was the solution that, ultimately, determined the appearance of the GEFORCE of the 50th series.
At the moment, the characteristics of the three consumer GPUs of the Blackwell family, which formed the basis of the new generation desktop models, starting with the GeForce RTX 5070 and ending with RTX 5090. As we will see later, the very logic of the NVIDIA graphic processors has not undergone structural changes, so the quantitative comparison of the block of block The formulas of old and new chips are quite appropriate and says a lot about their “raw” performance.
The flagship crystal GB202 set a new transistor budget record among consumer GPUs-92.2 billion-which brings it closer to the HPC-chip of the Blackwell, GB100 line. The latter consists of 104 billion transistors and, according to NVIDIA, is exhausted by the size of the TSMC photo chamber. In turn, the area of 750 mm2 sets the GB202 in second place after TU102 (754 mm2) of the Turn family.
Computing resources include 192 streaming multiprocessors, which, in conditions of unchanging distribution of ALU in separate SM, means 24 576 FP32-compatible CUDA nuclear. To saturate such an array of executive blocks with the data, GB202 endowed 128 MB of the last level and-attention-512-bit VRAM interface. We have not seen such a wide video memory in combination with GDDR SGRAM chips since the “red” chips Hawaii/Grenada (Radeon R 200/300 series).
Despite the impressive characteristics of the GB202, it is noticeable that the Blackwell silicon is closely within the boundaries of the TSMC 4NP technology. Previously, the transition from the AMPERE architecture to ADA LoveLace, which coincided with a full -fledged upgrade of the photolithographic norm, made it possible to increase the computing power of the senior GPU in the line of 72 % even without taking into account the clock frequencies. In turn, the GB202 surpasses the predecessor – AD102 – only by 33 % according to the shader ALU formula.
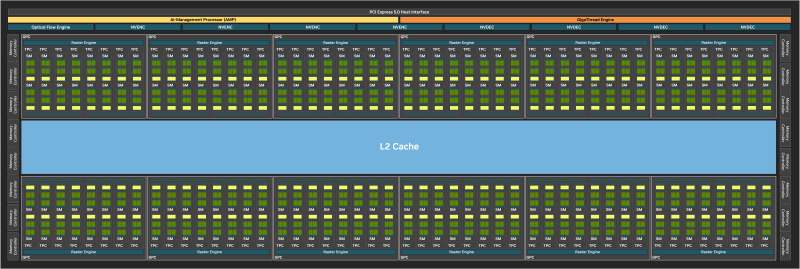
Block diagram of the graphics processor NVIDIA GB202
Be that as it may, the GB202 will raise the bar of playing speed to a new height and is no less designed for professional tasks, which will benefit even moderate progress. Unfortunately, the same cannot be said about the characteristics of the following seniority of the Blackwell crystal. The GB203 is half the flagship GPU – both in terms of the number of transistors and in the area of the crystal – and in the configuration of computing blocks (84 SM and 10 752 of materially dramatic ALU of standard accuracy) did not far from the corresponding ADA LoveLace, AD103 model. The gap between the graphic processors of the first and second echelon in the Blackwell series is more than ever and is 129 % programmable computing resources! The GB202 Following the AD103 received a 256-bit video memory tire and 64 MB Kesha L2.

NVIDIA GB203
Finally, Blackwell does not offer direct replacement of the AD104 chip, and the GB205 closest in terms of characteristics has the same configuration of the last tiers of memory stack (48 MB of Kesha L2 and 192-bit VRAM tire), but noticeably smaller number of SM and CUDA-polar fp32: 50 and 6 400, respectively.
A comparison of the old and new GPU shows that NVIDIA managed to place a little more than the shader ALU on a square millimeter of silicon, but the TSMC 4NP process did not bring the slightest increase in the average density of transistors (in each echelon it even decreased slightly), which directly affects the cost of production and,,,,,,,,,,,, by, Ultimately, the retail prices of video cards.
⇡#Energy -saving functions Blackwell
Another problem by Blackwell, which comes from TSMC 4NP photolithography, is energy consumption. The ADA LoveLace chips have a leading productivity of watt among the GPU of the past generation, but the absolute values of the power consumption in the 50th series increased sharply. Fortunately, NVIDIA engineers took a number of measures to curb the “zhor”.

The disconnection of unused blocks from the frequency generator (Clock Gating) occurs earlier and more selectively than in the ADA LoveLace chips. Blackwell also uses separate power supply lines of the GPU computing nuclei and memory systems, which makes it possible to individual voltage adjustment for certain load scenarios or complete de -energization of computing nuclei in order to prevent leakage. Unfortunately, NVIDIA does not specify which structures in this case are called nuclei (TPC, GPC or SM), but it is known that shutdown/inclusion can occur at the speed of shift change.
As a result of these innovations, silicon Blackwell is able to regulate the power consumption much faster in response to a change in the load, and a delay in the transition from the most economical active regime into deep sleep decreased by an order of magnitude. According to NVIDIA, Blackwell consumes 50 % less energy in certain short -term tasks compared to ADA LoveLace.
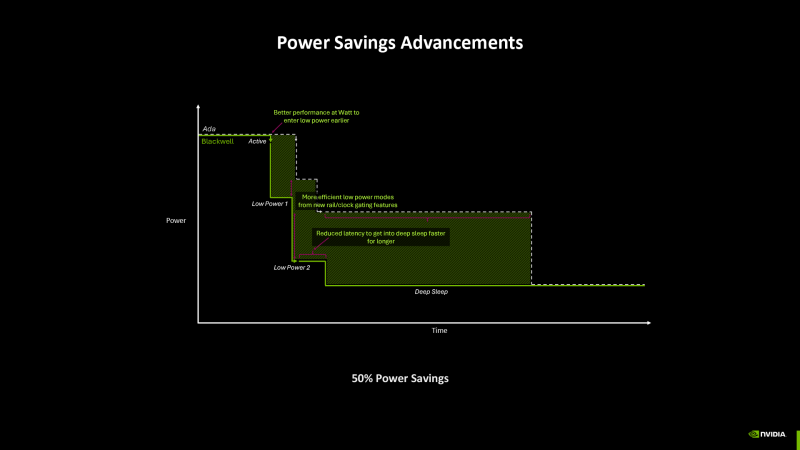
In addition, Blackwell chips are subordinate to the new clock control system. In the previous NVIDIA solutions, up to ADA LoveLace, the frequency changed dynamically, but was recorded during the rendering of one frame. Now the temporary resolution of the frequency adjustment is increased by 1000 times, which allows the GPU to effectively use the power reserve or, conversely, reduce energy consumption in the short period of relative inaction (for example, while receiving commands from the central processor).
⇡#GDDR7 video memory
One of the title innovations of the 50th GEFORCE series is support for the GDDR7 SGRAM video memory, which provides maximum 32 Gbit/s bandwidth with prospects up to 48 Gbit/s. The new VRAM standard differs at the physical level of both the widespread GDDR6 memory and GDDR6x, exclusive for NVIDIA products.
General purpose SDRAM memory interface and GDDR SGRAM up to the sixth version encode the signal using amplitude-moppulis modulation with two signal levels (PAM2), and the throughput from the time of the transition to the DDR has increased by increasing the symbolic velocity (in the Boda), which presents everything More stringent requirements for the length and wiring of transmitting lines. Other high -performance interfaces, such as PCI Express, USB and Ethernet, have also faced this problem, and the general solution is the introduction of additional PAM levels.
So, the GDDR6X video memory, developed by Micron in collaboration with NVIDIA, distinguishes four levels of signals and, therefore, transfers 2 battles of information per cycle, which, however, did not lead to a doubling in practical conditions. Coding PAM4 is especially sensitive to signal/noise, so GDDR6X cannot work at the same high symbolic speed as GDDR6. In the end, two standards came to the same data rate of 24 Gb/s data, but the GDDR6X is characterized by the complexity of the physical level circuits at both ends of the line and high energy consumption. Not to mention the fact that the only customer of such microcircuits is NVIDIA, and the supplier is Micron.

Unlike GDDR6x, the GDDR7 technology is standardized by Jedec, and Micron, Samsung and SK Hynix have already begun to release the chips. The GDDR7 physical interface as a compromise between the traditional coding PAM2 and PAM4 uses three levels of signals (-1, 0 and +1) and transfers 3 bits of data for two cycles. Thus, it was possible to slow down the increase in the frequency of the VRAM tire, but at the same time the requirements for the signal/noise ratio of the GDDR7 below compared to GDDR6x. In addition, the GDDR7 memory supports the intra -chip error correction (which has previously become a mandatory attribute of DDR5), has a reduced power voltage and a fast exit function of the sleeping mode. The maximum volume of the chip was increased from 32 to 64 Gbit (8 GB), although it is still far from the mass production of such dense chips. In the context of consumer graphics cards, it is more interesting that non -warranty volumes are permissible – such as 24 Gbit.
⇡#PCI Express 5.0, video codes and image output
In addition to VRAM, the NVIDIA graphic processors were ahead of the consumer chips of competitors in migration to the 5th generation PCI Express system bus, which has long been available in desktop PCs, but has been mastered only by solid-state drives. Three senior GPU Blackwell line -ups use the full width of the interface of 16 lines.
Finally, there were changes in the ASIC multimedia and display controllers. The GPU performs hardware coding and decoding of the H.264 and HEVC video with color subdiscrew YUV 4: 2: 2, which provides the best color resolution than the YuV 4: 2: 0 coding prevailing in these formats. Blackwell chips have two NVDec decoders, like ADA LoveLace, but, according to NVIDIA estimates, their speed when working with H.264, which in the previous generation was noticeably lower than when processing HEVC and AV1, doubled. As for the encoders, the GB202 crystal received an additional NVENC block in addition to the former two. And finally, the AV1 hardware coding is supplemented by the new Ultra High Quality mode. The latter will be available on the iron of the 40th series, but Blackwell provides high quality.
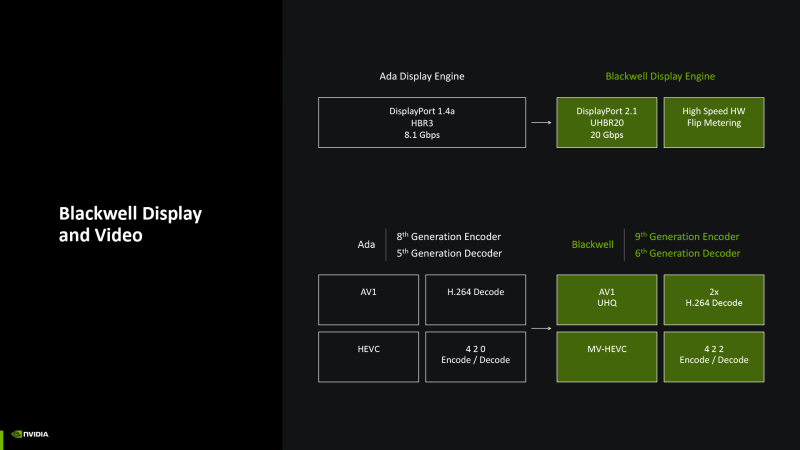
The display controller is compatible with the latest versions of the image output interfaces: HDMI 2.1B and DisplayPort 2.1b in the highest UHBR 20 mode (20 Gb/s on the line and 80 Gb/s when using all four lines).
Computing architecture SM
While the senior chip GB202 balances the protracted stop at a 5 -nm photolithographic node with huge dimensions and unprecedented power consumed, graphic processors of the following trains can only rely on architecture optimization. The Blackwell series brought more improvements to the logic of Green GPU than ADA LoveLace, and they are more of qualitative than quantitative.
The high -level hierarchy of the components of the graphic processor is not changed since the Ampere chips. The largest scalable unit on the block diagram is the GPC (Graphics Processing Cluster), which combines all stages of the rendering conveyor-from a rasterizer that performs the geometry in pixels, up to 16 blocks of rasterization operations (ROP). Between them is an array of streaming multiprocessors (SM), each of which is a formal analogue of the core of the central processor-just like Compute Unit in the AMD and XE-Core graphic architecture in Intel chips.
Sm pairs, tied to a common geometric engine, form the intermediate structure of TPC (Thread Processing Cluster). The TPC number inside the GPC varies from one chip to another and reaches 16 in the flagship GB202.
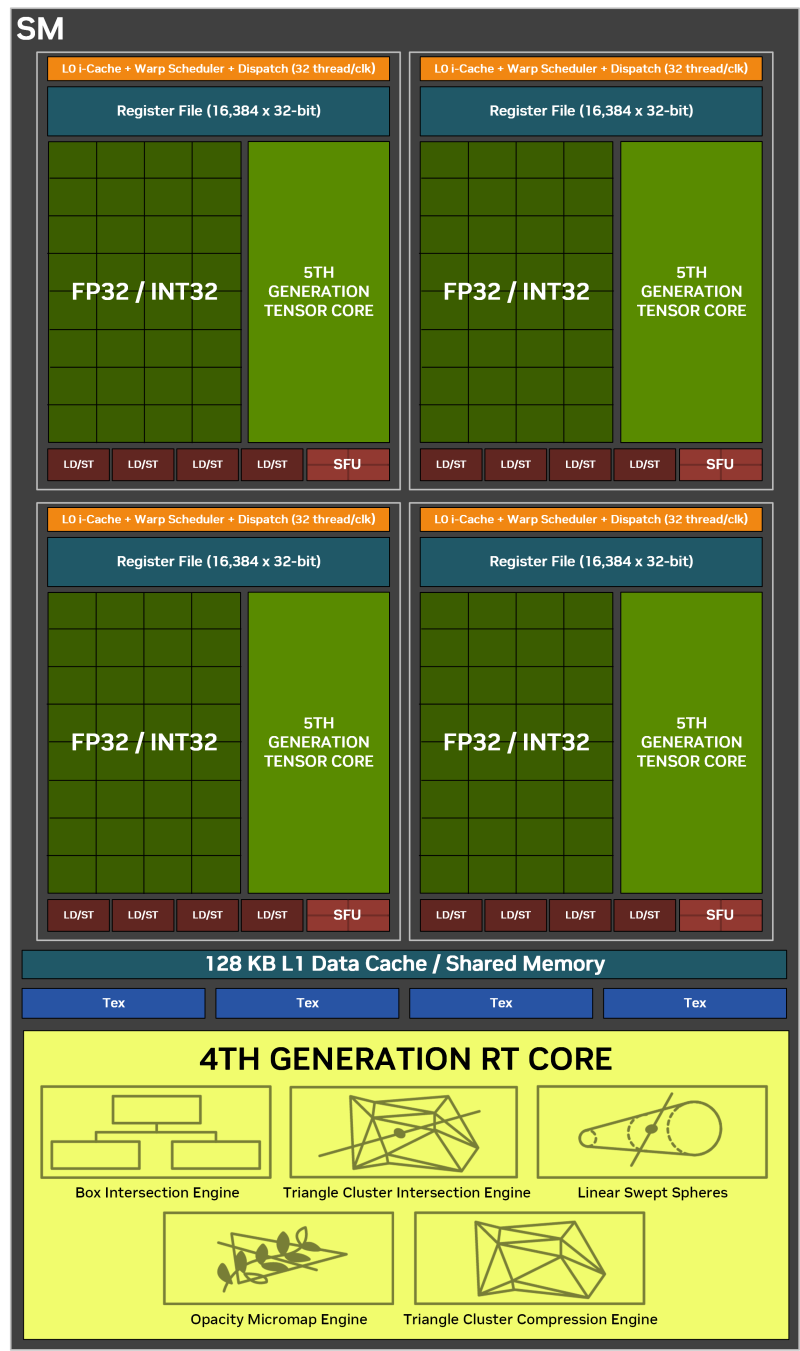
Finally, the streaming multiprocessor itself is divided into four subsection (SM Subpartition, SMSP). Each of the sections has its own register file (the most speedy part of the GPU memory stack), the team planner and dispatcher, to which a number of computing blocks are connected – including the tensor nucleus and two batteries from 16 shaders ALU (which can otherwise be called SIMD16 using the terminology of AMD and intel). We wrote in detail about how the NVIDIA graphic processors work at this low level, we wrote in the theoretical review of AMPERE architecture. The next silicon iteration, ADA LoveLace did not carry principal changes in the logic of SM.
The key innovation of Blackwell is that if earlier only one of the two SIMD16 could perform integer calculations instead of operations on swimming commas, now they are functionally equivalent, which means that the GPU’s performance in pure Int3 calculations has been involved. Instructions for operations on FP16 data (not matrix) are still performed by SIMD16 units without packaging, which means at the same pace as FP32.
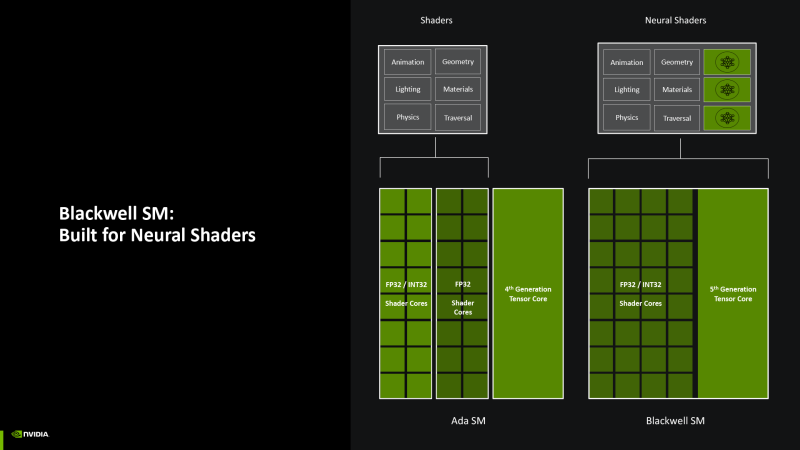
The total throughput of four tensor nuclei SM was delayed at 1,024 FMA instructions with FP16 data for one beat (which are laid out in 2,048 operations), but the GPU can now process materially data of an even lower discharge – FP4 – at a proportionally higher speed than FP16 or fp8.
In addition to the listed computing resources, SM SIMD4 blocks are designed to perform trigonometric operations, four scalar ALU and ALU of Double accuracy (FP64), which guarantee the consumer GPU basic compatibility with a similar code. NVIDIA does not report any changes associated with these secondary components. The volume of internal storage facilities remained the same: Kesha L1 and the register file.
But the blocking blocks, which are also part of SM, have learned to produce a point sample twice as quickly, which does not affect textual filtration (bilinear, trilneal, anisotropic), but it is important for such a function as compressing textures using the neural network (which we will touch on Later).
Thus, raw performance for the clock of SM operation compared to ADA LoveLace has increased only in relation to integer calculations of standard accuracy (Int32). The rules for the coexistence of heterogeneous loads inside a separate SM subsection remained in force. INT32 takes the throughput from FP32, and the dispatcher can give only one instruction for the beat of any of several types of computing units, but due to the latency of the performance of at least two tacts, parallelism is maintained.
2 × SIMD32 (FP32/INT32); 2 × SIMD32 (FP32);
2 × SIMD2 (FP64);
2 × SIMD8 (SFU);
2 × scalar alu
8 × SIMD16 (FP32);
8 × SIMD16 (INT32);
8 × SIMD2 (FP64);
8 × SIMD4 (SFU);
8 × xmx
4 × SIMD16 (FP32/INT32);
4 × SIMD16 (FP32);
2 × SISD? (FP64);
4 × SIMD4 (SFU);
4 × scalar ALUs;
4 × tensor nuclei
8 × SIMD16 (FP32/INT32);
2 × SISD? (FP64);
4 × SIMD4 (SFU);
4 × scalar ALUs;
4 × tensor nuclei
128 × FP32;
64 × INT32;
256 × FP16;
4 × FP64;
16 × Trans-e functions
128 × FP32;
128 × INT32; 256 × FP16;
16 × FP64;
32 × Transc-e functions
128 × FP32;
64 × INT32;
128 × FP16;
2 × FP64;
16 × Trans-e functions
128 × FP32;
128 × INT32;
128 × FP16;
2 × FP64;
16 × Trans-e functions
The graphic architecture of Intel XE2 has a number of formal advantages over Blackwell. Thus, integer and material calculations can occur in parallel at full speed, the corresponding ALU is initialized in one beat along with the XMX matrix array, and the FP16 instructions are packed in pairs and executed at a doubled pace. As for the “red” accelerators, the logic of the RDNA3 in theory develops the same capacity of the FP32 as Blackwell and works twice as fast as half the accuracy. However, a set of RDNA instructions sharply narrows the possibilities for extracting maximum parallelism, not to mention the four -fold lag behind competitors in matrix computing and the absence of ALU dense massifs allocated for this purpose – such as the tensor nucleus or XMX.
⇡#Ray tracing and Mega Geometry
NVIDIA steadily increases the speed of hardware tracing of rays. This time, the speed of a single RT block increased from two to four tests of the ray with a triangle by the beat. The number of intersections with BVH boxes, which occur in parallel, still remains secret, but the nvidia chips at least in one aspect ahead of the closest competitor-the architecture of Intel XE2-which performs 2 tests of the beam with a triangle and 18 intersections with BVH boxes For one tact of the RT block. In turn, the RT-block in the composition of the RDNA3 can determine only one intersection of a beam with a triangle for a beat or four intersections with a boxing, and the passage of the BVH structure is carried out by software, on shader ALU.
In addition, NVIDIA introduced a set of software tools called Mega Geometry, designed to facilitate the task of tracing rays in conditions of complex and dynamic geometry. Modern Lod algorithms (Level of Detail) – such as Nanite in Unreal Engine 5 – smoothly vary polygonal grids by replacing small landfills (about 128) in order to eliminate visible leaps for detailing when changing the distance from the viewing point to the object. However, each step LOD sharply complicates the BVH generation, so honest trace of rays in combination with Nanite and similar systems does not have practical meaning, and BVH is based on a simplified proxy-geometry.
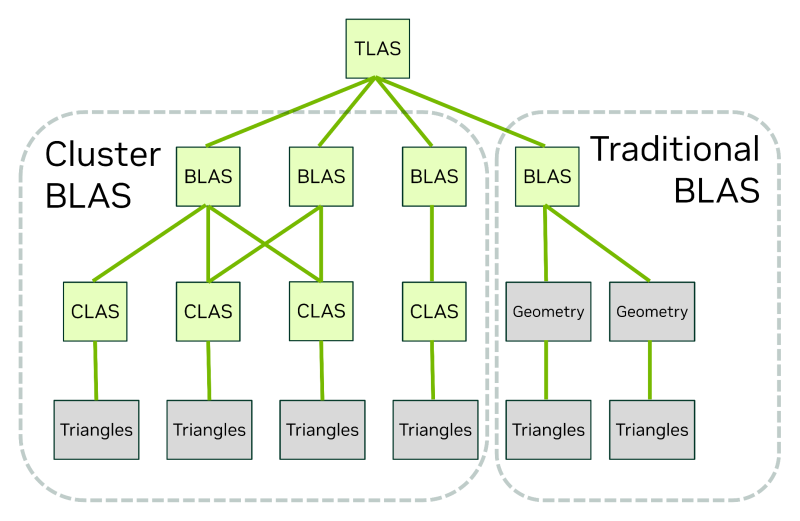
The MEGA Geometry approach is that the Lod algorithm operates with entities that are natively reflected in BVH. For this purpose, a new type of primitive BVH is introduced-Cluster-Level Acceleration Structures. CLAS is a collection of localized groups of triangles, which is generated on demand (for example, when the scene object is loaded from the disk) and can be chatted for use in new frames. The level of detailing of the polygonal grid is changed by replacing Clas, and due to the fact that Clas contains about a hundred triangles, the speed of each BVH restructuring can be increased by two orders of magnitude.
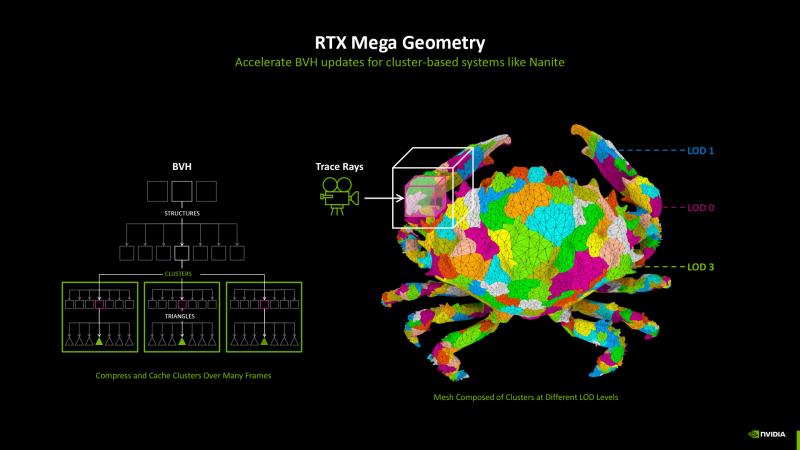
CLAS primitives will find use not only in games. The professional 3D animation uses the Subdivision Surface algorithm, which allows you to form curvilinear surfaces by recursive complication of polygonal mesh and is traditionally performed on CPU. For the Subdivision Surface Subdivision Surface, the graphic processor is necessary to carry out a tesselia of curves into triangles, which entails the construction of volumetric BVH each frame. This process, again, can operate with celled polygon clusters.
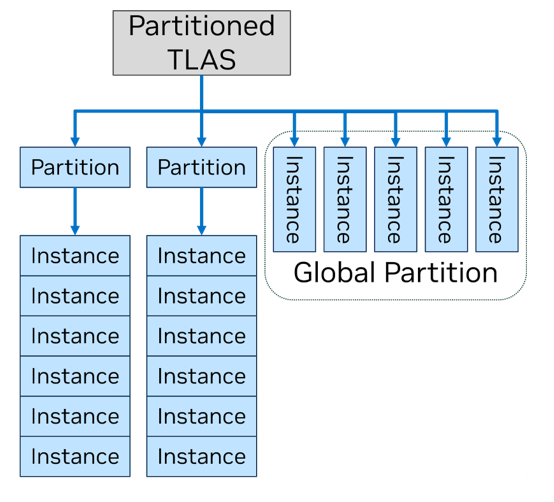
Another innovation of Mega Geometry allows you to simplify the BVH generation thanks to the new type of higher level structure-Partitioned Top-Level Acceleration Structure (PTLAS)-and rests on the same idea: to open a 3D application of direct access to BVH so that the GPU fulfills a certain part of the work once and He used the results in the future. So, if the game engine knows that certain objects of the game scene will remain static for some time relative to the view point, they can be taken to the BVH of their own sections, which will not be rebuilt without the need for each next frame.
Calls of Mega Geometry are designed for package processing, which allows you to completely unload CPU from tasks such as LOD selection, and access is carried out through NVAPI, OPTIX and Vulkan branded extensions. This is proprietary API, and support at the standard functionality level Direct3D and Vulkan is not discussed yet. As for the hardware requirements, the Mega Geometry is compatible with any RTX-video cards, but, of course, works best on Blackwell chips, which have specialized logic (Cluster Engines) for hardware compression of geometry and BVH. According to NVIDIA, the consumption of video memory in tasks such as reiterating with Nanite, it was possible to reduce by hundreds of megabytes.
Finally, the Blackwell RT-Yaro is able to check the intersection of a ray with a geometric primitive Linear Swept Spheres (LSS) designed for realistic hair modeling, fur, herbs and similar objects. The LSS figure is formed by moving the sphere along the trajectory of several linear segments while changing the radius and allows you to get rid of artifacts characteristic of the predominant method of approximation of threaded structures – using the landfill chain (Dots, Disjoint Orthogonal Triangle Strips).
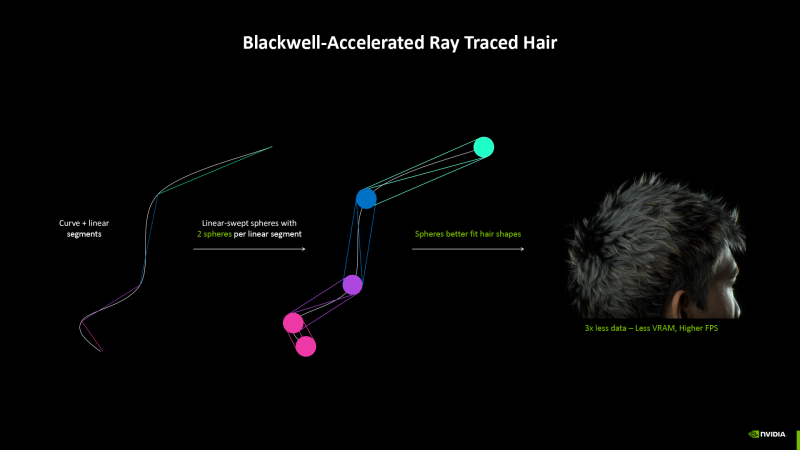
In addition, the spheres can be used without moving (for example, for rendering of particles). The new primitive not only allows you to create better models, but, according to NVIDIA, LSS rendering occurs twice as fast, and video memory is required five times less than when using Dots.
⇡#Shader Execution Reordering 2.0 и AI Management Processor (AMP)
One of the few innovations of the ADA LoveLace architecture was the ability to dynamically regroup instructions (Shader Execution ReORDering) to increase coherence of memory access – for example, under circumstances as the execution of pixel shaaders at the stage of secondary, reflected rays.
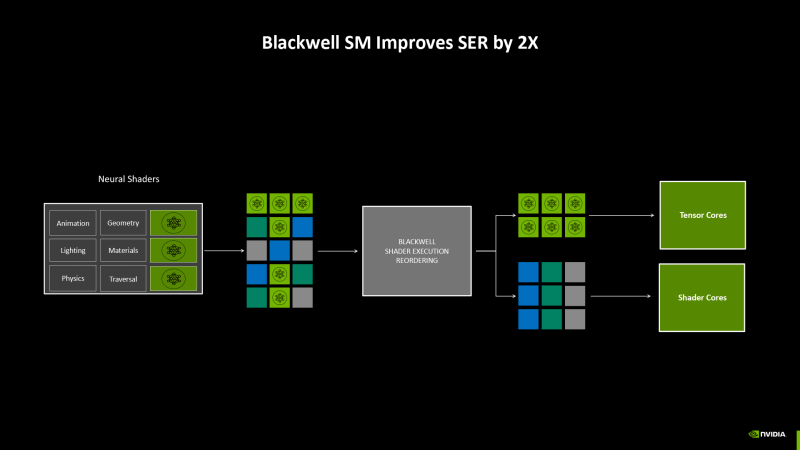
The effectiveness of the logic of SER in the Blackwell chips, according to NVIDIA, has doubled in terms of estimates of the accuracy of regrouping and performance costs for this operation. Ser also helps to load the tensor nuclei, which is important for the performance of new neural shaders. Access to the Seru functions is explicitly through a special API, which has already been mastered by some games with tracing of ways and packages of professional 3D-rendering.
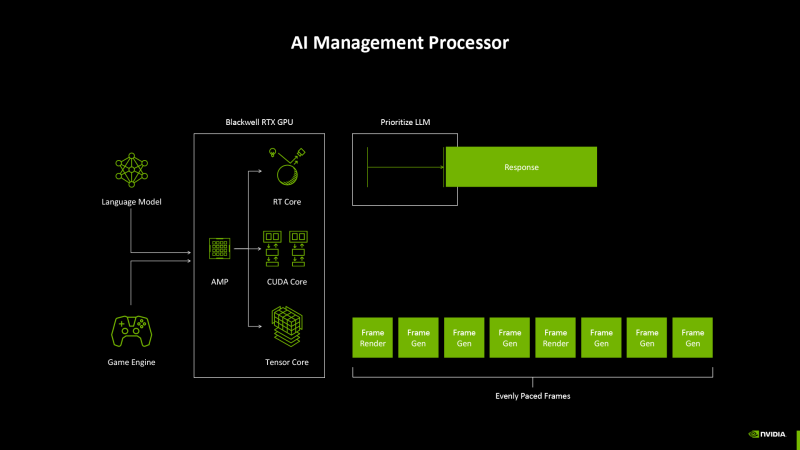
The GPU frontnd is supplemented by a fully programmable context planner based on a separate RISC-V architecture processor-AI Management Processor (AMP). Previous iterations of the “green” chips, starting with Turing, have already had a hardware planner, but AMP is more flexible and, therefore, effectively, distribute the GPU time in a multitasking environment. During the game, AMP is designed to reduce the input delay by highlighting the priority type of load – for example, DLSS neural networks.
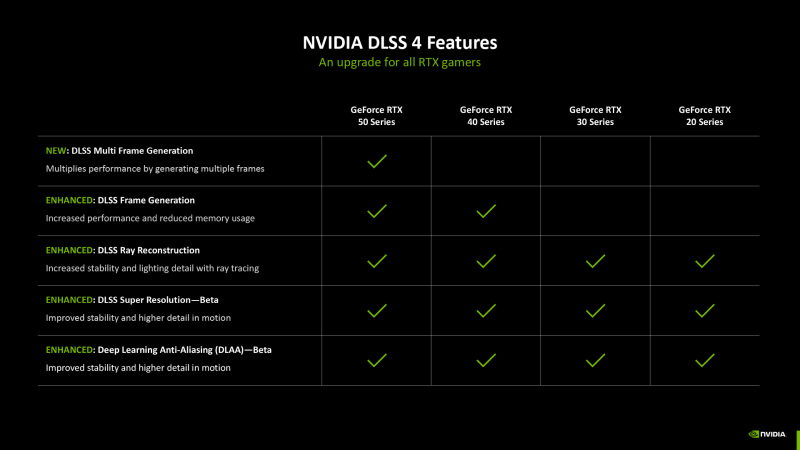
⇡#DLSS 4
In the same way as the DLSS APSCALING with the feature of the GEFORCE 40 gaming video cards, the new generation’s business card was generated using a neural network of several frames in a row – up to three – which is based on the features of the Blackwell chips and, of course, is not compatible with the previous ones Iterations of architecture. The generation algorithm, according to NVIDIA estimates, is 40 % faster and consumes 30 % smaller video memory. It is curious that at the same time the hardware calculation of the optical stream is no longer used by the ASIC multimididine, which has become (at least formal) obstacle to open the frame generation of ampeere accelerators – now this function is performed by a separate neural network.
The frame rate is controlled by hardware, on the side of the display controller, and not the central processor. In turn, the AI Management Processor planner is designed to regulate the priority of certain stages of rendering in order to reduce delay and minimize the stochastic drawdown of personnel frequency.
It is important to note that the generation of personnel (especially multiple, MFG), no matter how high -quality the image is not a full replacement of “honest” rendering in another aspect. The fact is that the time of the input reaction depends on the distance between the personnel that passed the entire logic of the game engine – in other words, such a framework that GPU can develop without generating personnel with a neural network (but, optionally, with scaling). So MFG will make movements more smooth, but the game will not become responsive if the initial personnel frequency lies below a comfortable value (for example, 60 FPS).
The generation of personnel, on the contrary, takes away from the GPU some share of computing resources and, ceteris paribus, increases the reaction time. Therefore, MFG is designed to jointly work with the new version of Reflex technology. The latter uses the technique of Frame Warp, borrowed from the VR environment: before sending to the monitor, the frame changes depending on the last movement of the mouse.
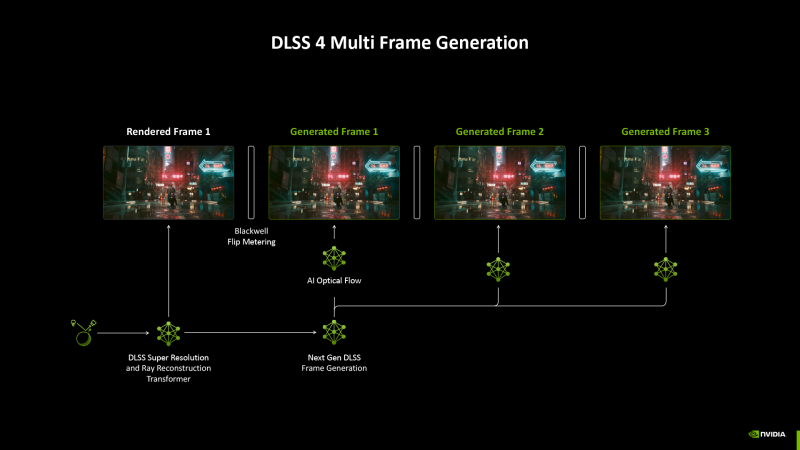
Machine training of the fourth version of DLSS is based on transformer model instead of adhesive neural networks (CNN, Convolution Neural NetWorks), which NVIDIA used previously due to their relatively low computational complexity. CNN is a hierarchical structure, which (in relation to image processing) is carried out by layer -laying visual patterns in the direction from the bottom up – from localized pixel groups to large objects. At the same time, the spacing operation itself is local, that is, it is applied to the isolated area of the image, and the general algorithm always works the same on certain data.
On the contrary, the key property of the transformer is the so -called attention (or self -awareness), which allows you to integrate the processed material and direct calculations to the most important data. Thanks to this, transformers have found wide application in tasks with a pronounced sequential component – such as analysis of speech. In the context of DLSS, transformers are more efficient than CNN, they are recognized by large patterns and are easier to scale, allowing you to master twice as many initial data and more strongly load the GPU tensor nuclei.
As a result, the work of all DLSS functions changes qualitatively, including not only APCCILing, but also reconstruction of rays and smoothing the DLAA in native resolution. DLSS 4 allows you to use transformers on the old gland, starting with the Toring generation.
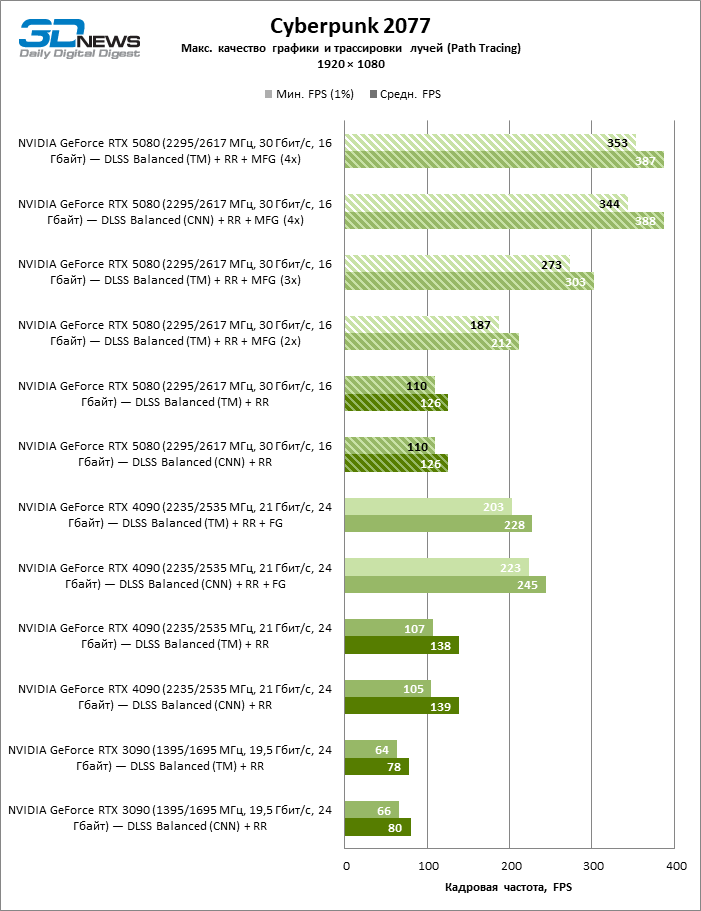
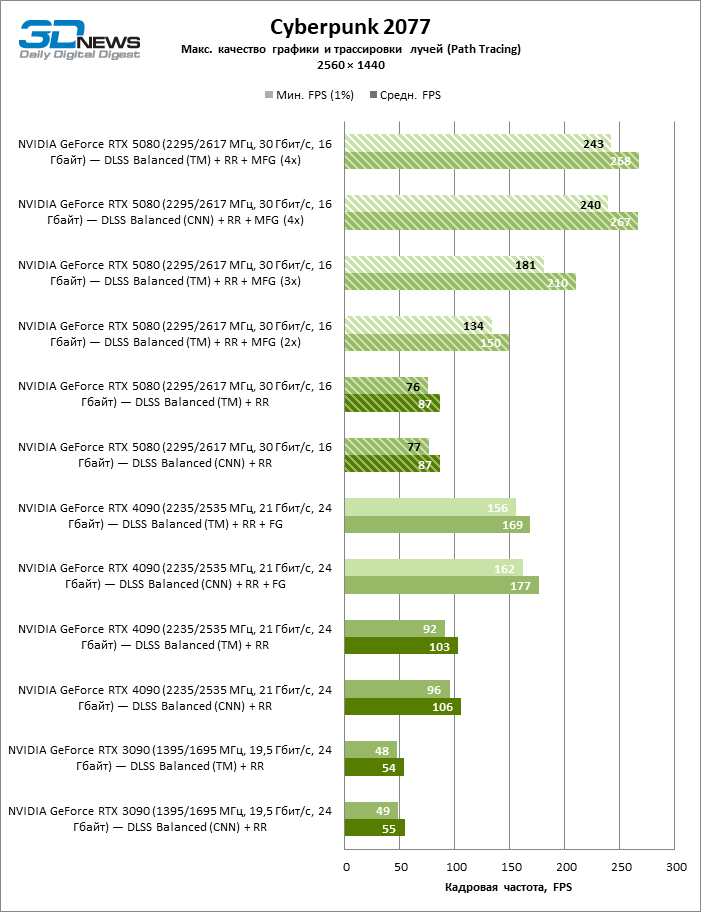
The NVIDIA desktop application can force MFG (as well as other parameters, including the neural network model) in several dozen titles that support DLSS, but have not yet been updated to the last version. In anticipation of the start of sales of the 50th series, we had the opportunity to test the new Apxeyler functions only in the Cyberpunk 2077, which has already received a native compatibility with DLSS 4. As you can see, the generation of multiple personnel and really ensures multiple growth of the framework of the usual scale. As for the neural network model, but, to our surprise, transformers do not cause almost a significant loss of performance compared to bundal networks even on the Green GPU of a year -long generation.
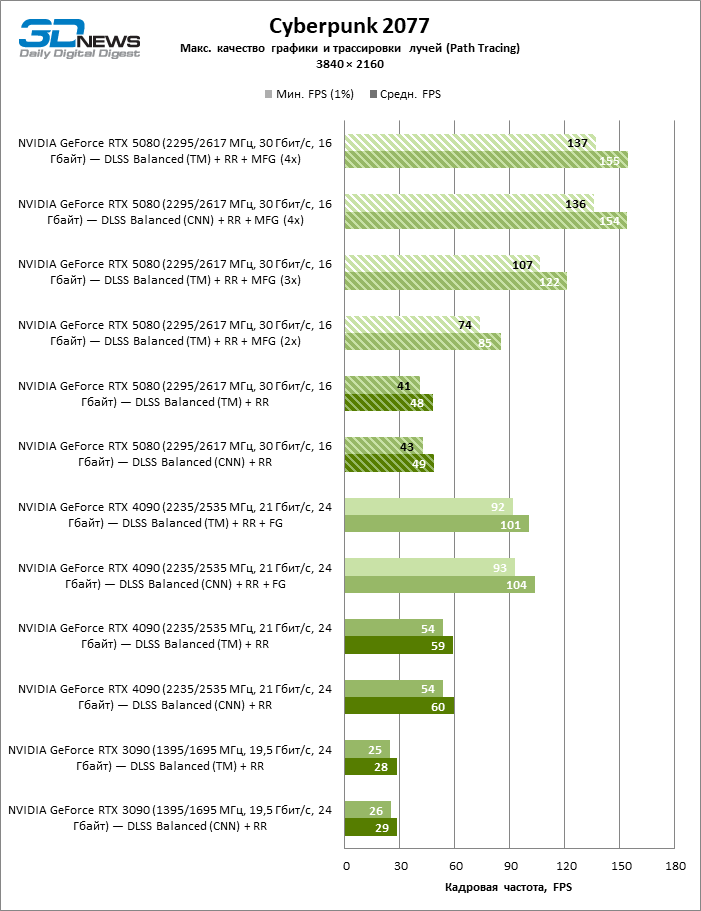
⇡#Neural shaders
Finally, one more – definitely, not as provocative as MFG, but promising – the initiative is that the neural networks working on the tensor nuclei can directly participate in the performance of shaders, approximizing the result of the general purpose of the general purpose. At the same time, neural network training is performed locally, at the GPU itself, sometimes even in real time. Microsoft is already working on the Cooperative Vectors programming interface, which allows you to multiply matrices with arbitrary size of vectors in any shader code, which is required by neuralates. The new API is not tied to the NVIDIA iron and in the near future it should become part of Direct3D.
The scenarios of the use of neural shaders are diverse, but NVIDIA cited an example of a number of tasks that will receive maximum speed growth. So, neural shaders are able to partially replace the mathematical model of complex multilayer materials with neural networks. A related task is to simulate underground light scattering in a translucent environment – such as the skin of living creatures. In games for this, they still do not use the trace of rays in connection with high computational complexity, which, again, are designed to fix neural shaders.

Nvidia proposes to attract full generative AI to rendering human persons. A simple rasterized portrait and spatial coordinates are taken as a basis, and the neural network, previously trained on a large array of images, makes the face natural.
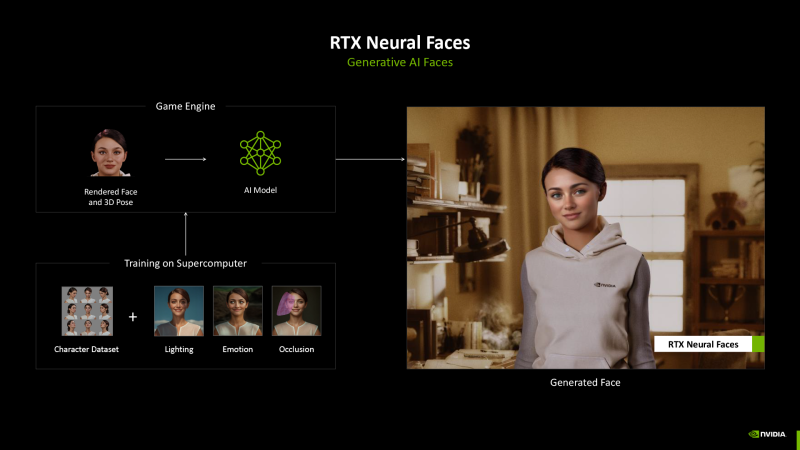
Another type of neural shader is the Neural Radiance Cache (NRC), which simplifies global lighting rendering using rays trace. The NRC neural network continuously trains in real time to form an approximated model of secondary reflection of rays. As a result, tracing is limited to primary rays, and the paths of the following orders are sent to Kesh.

Finally, with the help of neural shaders, a more efficient and high -quality compression of textures is possible than using traditional methods: NVIDIA demonstrated a three -time saving of VRAM volume. It is curious that in this case, the texture imposition occurs without hardware filtration (trilneine or anisotropic). Instead, stochastic filtration is used based on a random point sample in order to eliminate artifacts (ladders, Muar, etc.).
⇡#Specifications, prices
The GeForce RTX 5080 is based on a completely functional GB203 crystal, which is atypical for NVIDIA, but is justified in the light of minor changes in the formula of computing blocks compared to AD103. If you take the GeForce RTX 4080 and RTX 4080 Super at the reference point, the GPU clock frequency has received a symbolic increase in 67–112 MHz, which means that the intercoral growth of raw productivity in FP32-calculations is reduced to miserable graphic processors of 8–15 % TFLOPS .
GeForce RTX 5080 is equipped with 16 GB of video memory of the GDDR7 standard with a bandwidth of 30 Gbit/s, which provides the total PSP of 960 GB/s – 30–34 % higher compared to two varieties of RTX 4080. The reference power of the new product is also noticeably larger than the RTX 4080 and RTX 4080 Super, designed for energy consumption of 320 watts.
With such characteristics, the GeForce RTX 5080 is nothing more than a soft upgrade of the previous 80s of models, but this did not prevent NVIDIA from maintaining the recommended cost of $ 999. So, even if some of the Blackwell architecture innovations contribute to the traditional rendering method, the consumer value of RTX 5080 is completely based on the next version of the DLSS, now with the function of generating multiple frames.
As for the GeForce RTX 5090, in this case, a huge array of GB202 computing blocks was cut by 22 SM (or 2,816 fp32-compatible shader ALU), and the GPU clock frequency was reduced by 113 MHz compared to RTX 4090. Nevertheless, the difference in Theoretical speed between the flagship models is 27 %. If we take into account that the GB202 crystal is approaching the maximum area of the TSMC photo show, NVIDIA squeezed almost everything from the 5-nanometer technology process and cannot be counted on the best results. The GEFORCE RTX 5090 has 32 GB of the GDDR7 memory, and the 28 Gbit/s capacity on a 512-bit tire means a huge PSP 1,792 GB/s (78 % higher than that of RTX 4090).
The bad news is that the GeForce RTX 5090 consumes up to 575 W, and most importantly, it costs $ 1,999. Thus, the two senior models of the 50th ruler shares an unprecedented distance of 86 % of theoretical speed and 100 % of the recommended cost-or even More in the conditions of the expected deficiency. Both devices go on sale today, so readers can already look at the real prices of new products.
⇡#Palit GeForce RTX 5080 Gamerock: Construction
GEFORCE RTX 5080 in the modification of the Palit Gamerock operates at reference clock frequencies and is a huge video card with exactly the same dimensions (331.9 × 150 × 70.4 mm), as in the same version of the RTX 5090, which allows you to count on the light of the smaller TBP increased cooling of components and low noise. The device occupies almost four expansion slots in the PC case.

The front panel of the casing has a mirror surface with corrugated areas, which shimmers with bright LED lighting patterns. The LED pattern and color can be adjusted separately or synchronized with the motherboard through the standard Argb-connector, which is located next to the 12V-2X6 power entrance.

The perimeter of the video card covers a cast aluminum frame with ventilation slots on the long sides. In the backplane, also a metal one, there is already a familiar window that opens a significant part of the radiator for the through air passage.

The cooling system is served by three fans with a 92 mm impeller diameter. At low temperature and load on the GPU, the device is cooled passively.
The radiator is based on the evaporative chamber of complex shape – large enough to cover the crystal of the graphics processor and VRAM chips. As a thermal interface between the GPU and the evaporative chamber, ordinary thermal paste is used. For power cascades and VRM throttle, separate lamellar heaters are provided, one of which is directly in contact with thermal tubes. The latter here, by the way, is nine pieces.

Although the backplate is made of metal, there is not a single heat laying under it, which means that the plate does not participate in PCB cooling.

The Palit Gamerock delivery kit includes an adapter from three eight-pin power connectors to the 12V-2X6 plug, the ARGB synchronization cable, the prefabricated controlled support for the hard installation of the video card in a horizontal position, and a small fabric mouse coat.

⇡#Palit GeForce RTX 5080 Gamerock: Printing
The video card is assembled on a compact PCB, which, however, boasts an extremely powerful power system. The voltage regulation on both the GPU and the video memory microcircuits will be managed by the Monolith Power Systems MP29816 and MP2988 SWM controls. VRM includes a total of 19 phases, which are equipped with power cascades MPS87993. Their rated current is not known to us exactly, but, presumably, is 90 A.
Marking the GDDR7 chips production Samsung (K4VAF325ZC-SC32) reflects 32 Gbit/s capacity-2 Gb/s higher than the specifications of the GeForce RTX 5080.


Palit Gamerock has a BIOS version switch. One firmware is “quiet”, the other is “productive”. As the choice of firmware acts at GPU frequencies and the operation of the cooling system, we will find out in the next, empirical part of the review.
⇡#Test stand, testing methodology
In most games, the average and minimum (we indicate the 1st percentile of the distribution) frame rates are derived from the array of rendering times of individual frames or the instantaneous frame rate obtained using the built-in benchmark. The exceptions are games that do not have a built-in benchmark, and tests using frame generation: in these cases, we use the OCAT program to capture inter-frame intervals.
The power of video cards is recorded separately from the CPU and other PC components using the NVIDIA PCAT device. The load for testing power and noise levels is Cyberpunk 2077 at a resolution of 3840 × 2160 and maximum graphics quality settings (without ray tracing), as well as the FurMark stress test with the most aggressive settings (resolution 3840 × 2160, MSAA 8x). All parameters are measured after the video card has warmed up, when the GPU temperature and clock frequencies stabilize.
⇡#Test participants
The following video cards took part in performance testing:
- NVIDIA GeForce RTX 5080 (2295/2617 MHz, 30 Gbit/s, 16 GB);
- NVIDIA GeForce RTX 4090 (2235/2535 MHz, 21 Gbps, 24 GB);
- NVIDIA GeForce RTX 4080 Super (2295/2580 MHz, 23 Gbit/s, 16 GB);
- NVIDIA GeForce RTX 4080 (2205/2505 MHz, 22.4 Gbps, 16 GB);
- NVIDIA GeForce RTX 3090 (1395/1695 MHz, 19.5 Gb / s, 24 GB);
- AMD Radeon RX 7900 XTX (1720/2499 MHz, 20 Gbit/s, 24 GB).
Approx. The basic and Boost-frequency GPUs are indicated in the brackets.
⇡#Clock speeds, power consumption, temperature, noise and overclocking
The GB203 graphic processor on the GEFORCE RTX 5080 board supports a clock frequency of about 2.8 GHz under the game load – almost the same as the AD103 in the GeForce RTX 4080 or RTX 4080 Super. GPU supply voltage has not changed much.
But the energy consumption of the 80th model increased from 303–311 to 365–372 W at the Cyberpunk 2077 without tracing rays. The full power reserve Palit Gamerock is completely approaching 400 watts.
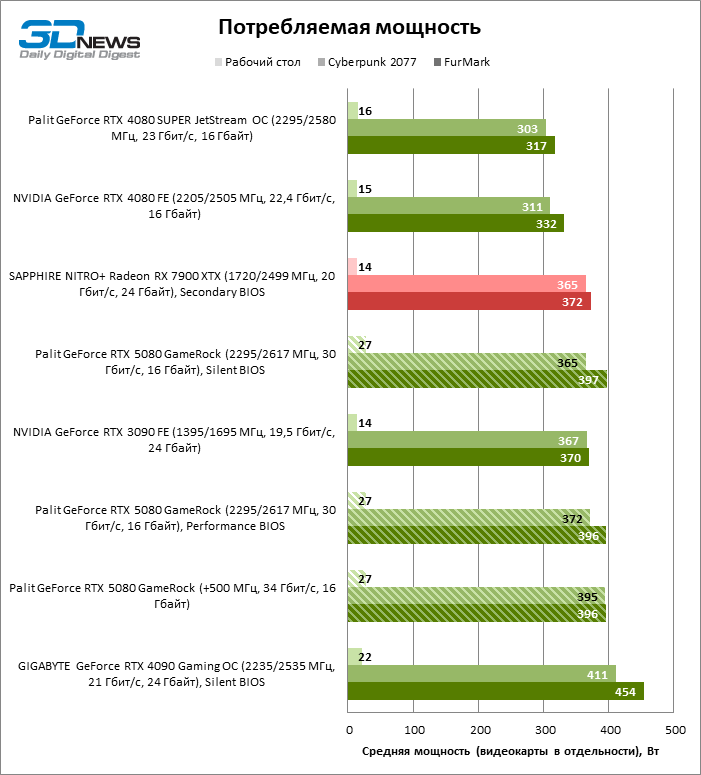
Switching between “quiet” and “productive” copies of BIOS does not regulate the clock frequencies and a power budget, but affects the speed of rotation of the fans. However, the difference in the temperature of the components when using different firmware does not exceed 3 ° C. Under the stress load, the GPU heats up from force to 70, and the GDDR7 memory chips are 74 ° C, which is a very typical result for a modern video card. Note that the Blackwell chips driver does not issue information about the temperature of the hottest crystal zone. Whether this function will return in the upcoming versions of the software is still unknown.
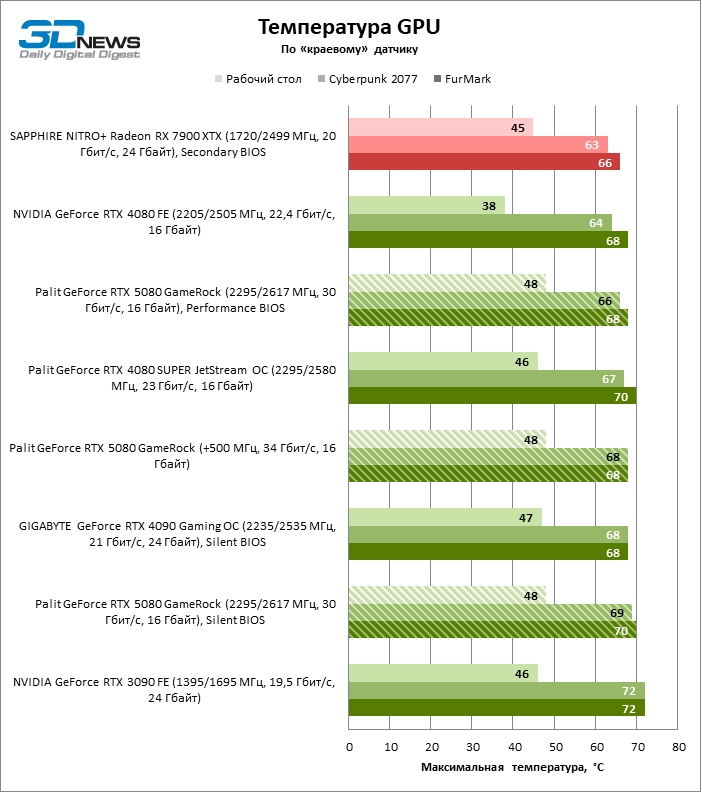
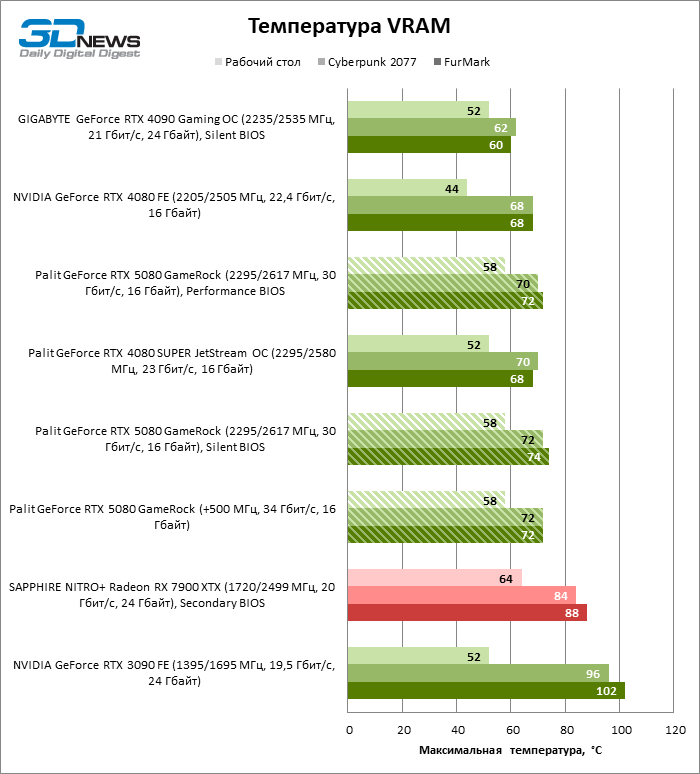
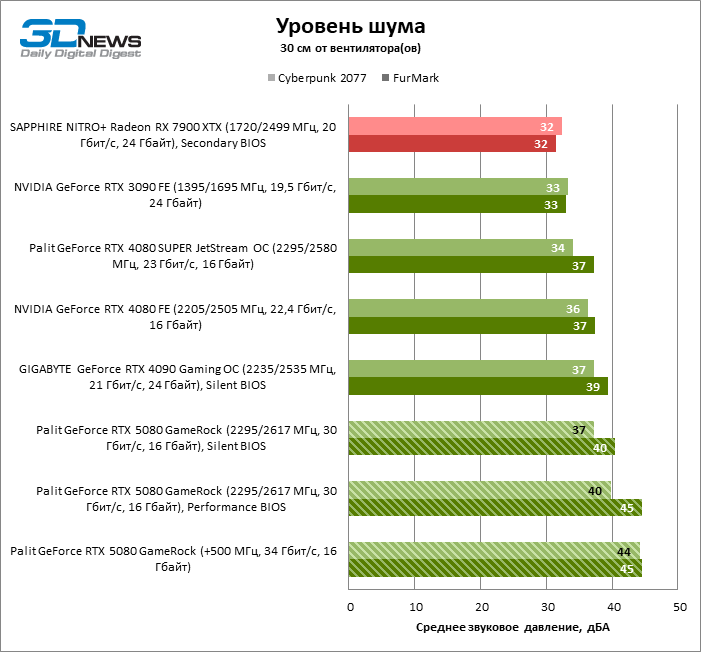
Despite the high energy consumption of the accelerator, the Palit Gamerock cooling system develops a completely acceptable noise level up to 37 dBA (at a distance of 30 cm from the fans) under the game load – but provided that the “quiet” firmware is active. ” The “productive” BIOS increases the sound pressure to 40 dBA at standard clock frequencies and is good only for user overclocking.
The GeForce RTX 5080 in the modification of the Palit Gamerock (at least without a mark of OC) does not allow to increase TBP, which, however, was not an obstacle to surprisingly productive dispersal. The GB203 retains stability at a frequency of 3.25 GHz (457 MHz above the standard value) under load without tracing rays, and the GPU supply voltage has automatically decreased by 0.02 V. Such impressive results are probably associated with the updated dynamic frequency adjustment system. However, constant fluctuations within the rendering of one frame, behind which the monitoring program does not have time, also means that for some time the GPU does not work at a given frequency. In turn, we managed to disperse the video memory chips with the initial throughput of 30 to 34 Gb/s, and at the same time there is no loss of speed due to error correction.
The dispersed video card Palit Gamerock almost entirely consumes a power supply of about 400 watts even in a game test without ray trace. The cooling system has mastered the increased heat generation without harm to the temperature of the components, but the noise level jumped to 44 DBA.
⇡#Game tests (1920 × 1080)
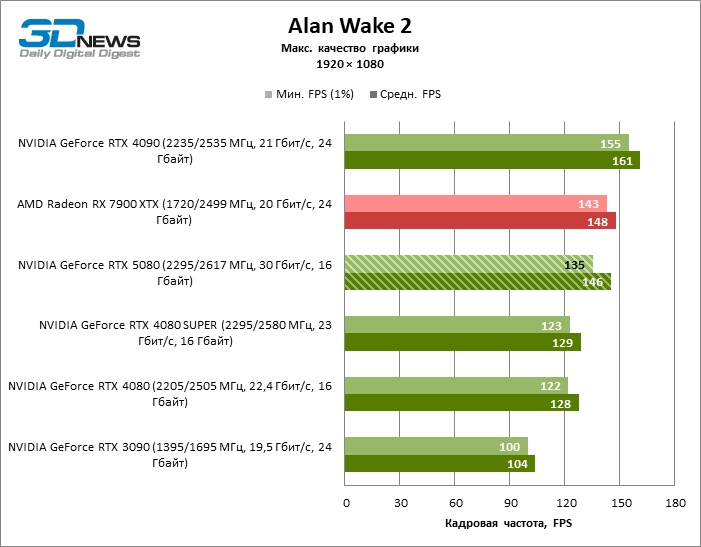
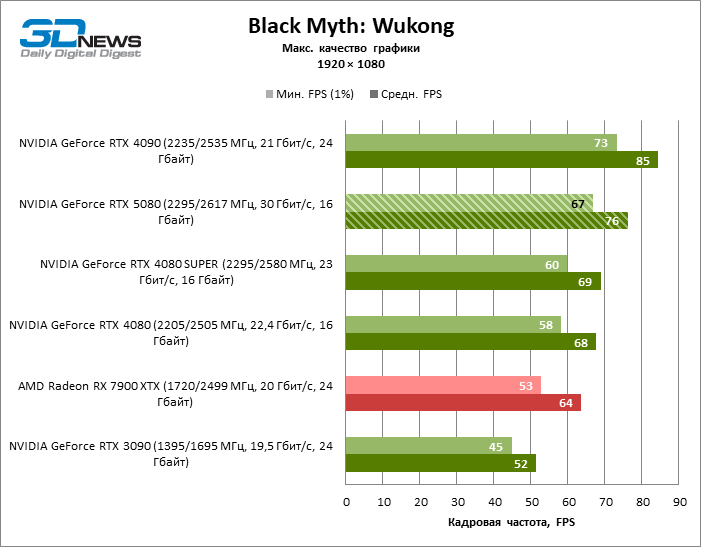
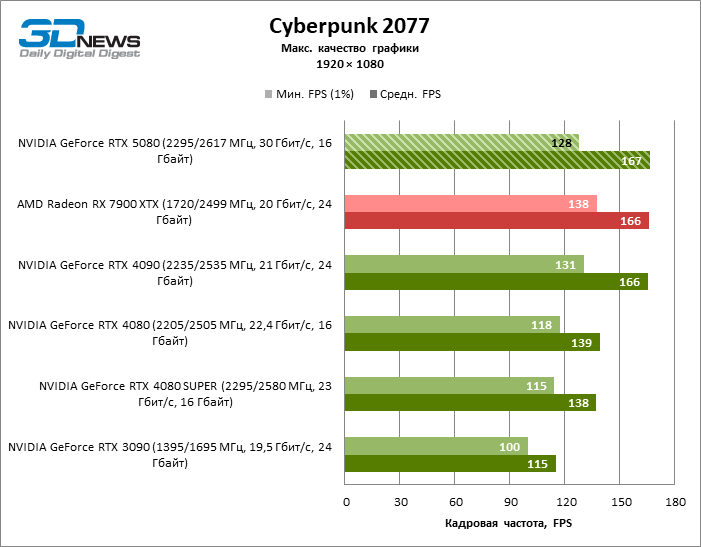
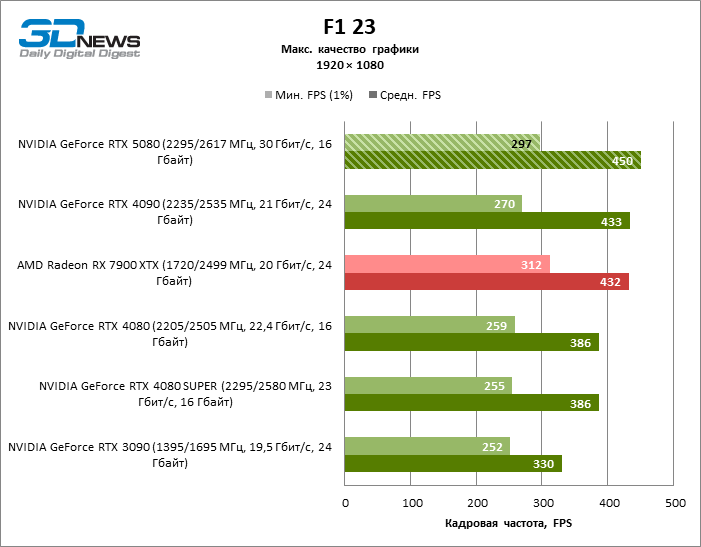
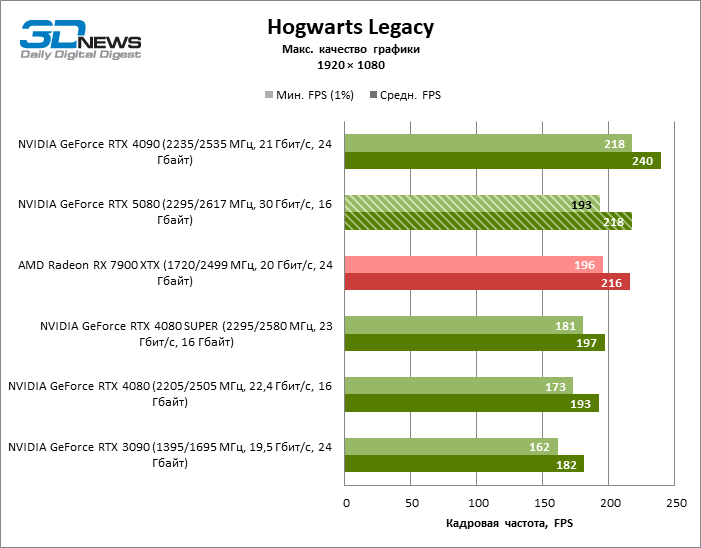
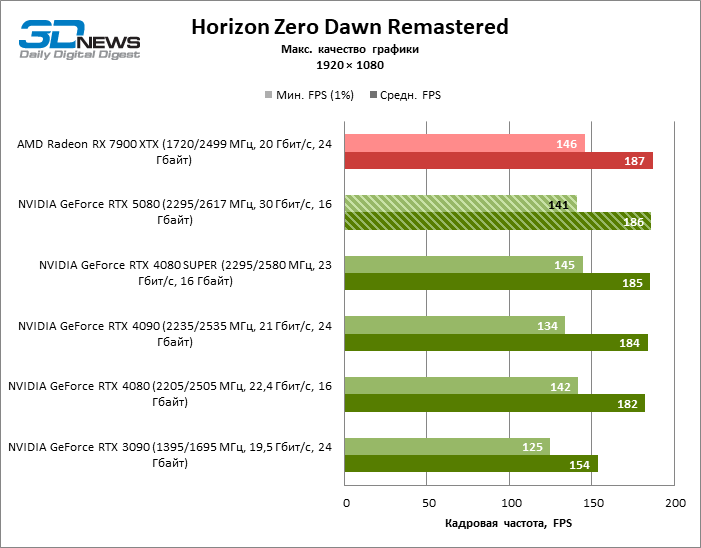
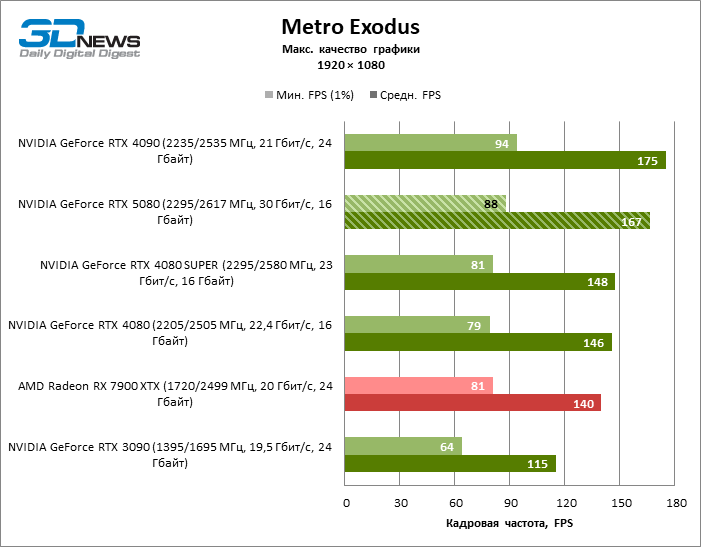
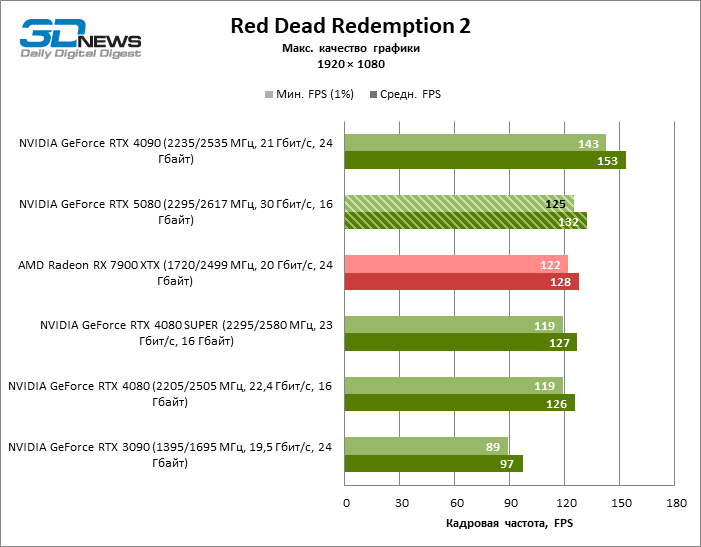
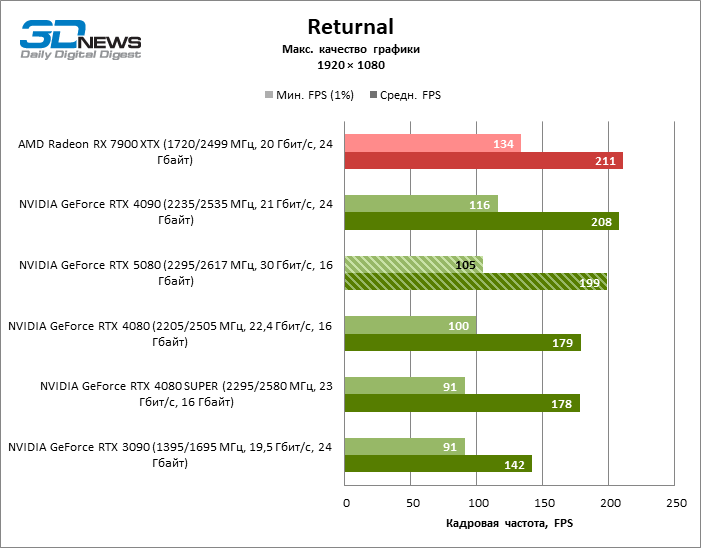
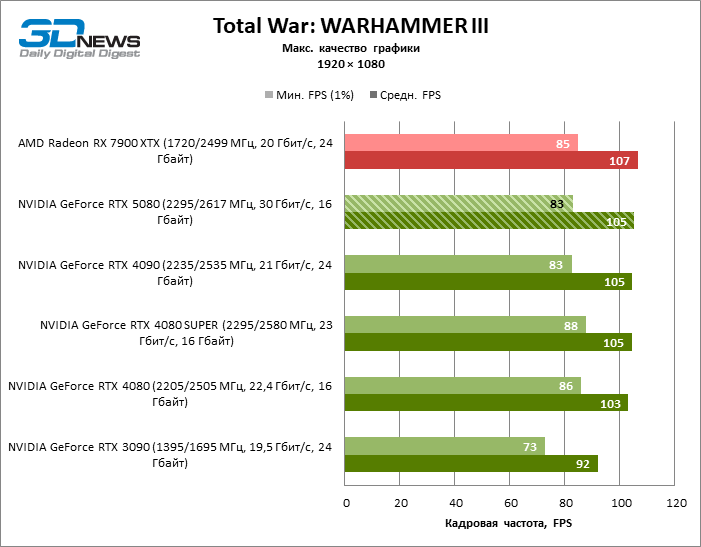
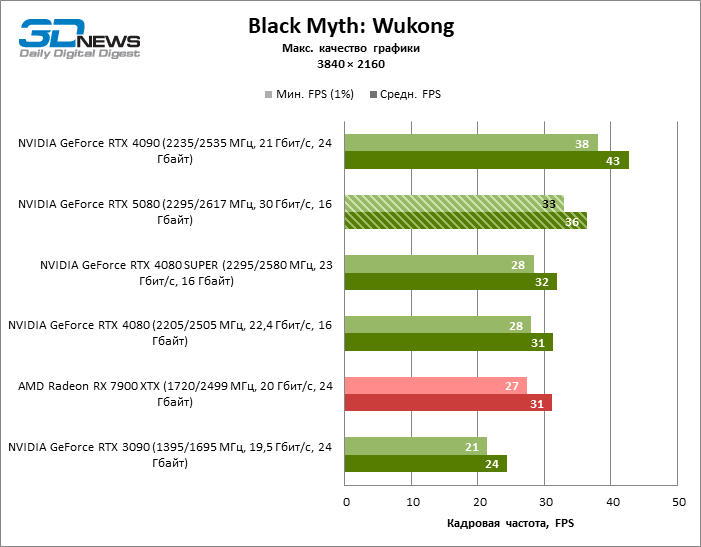
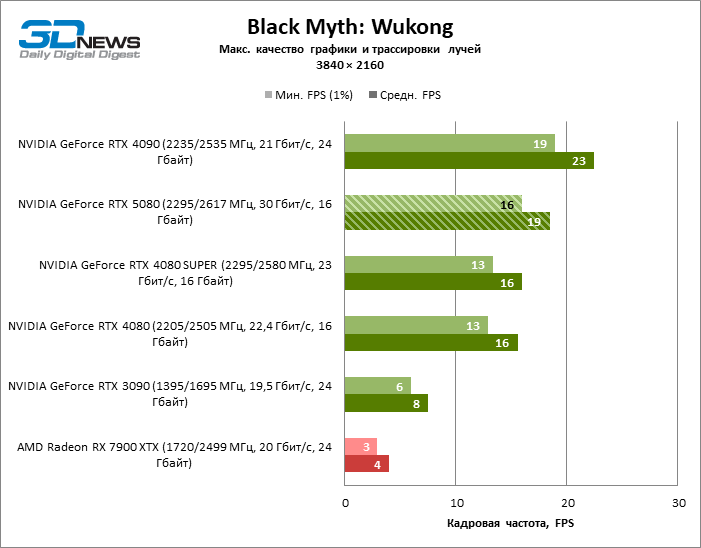
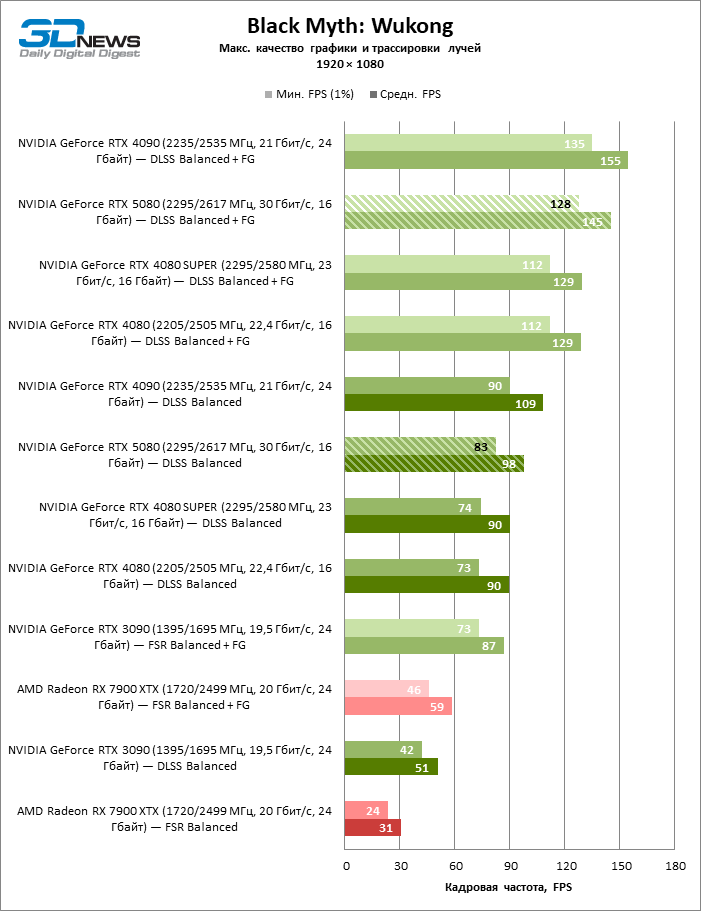
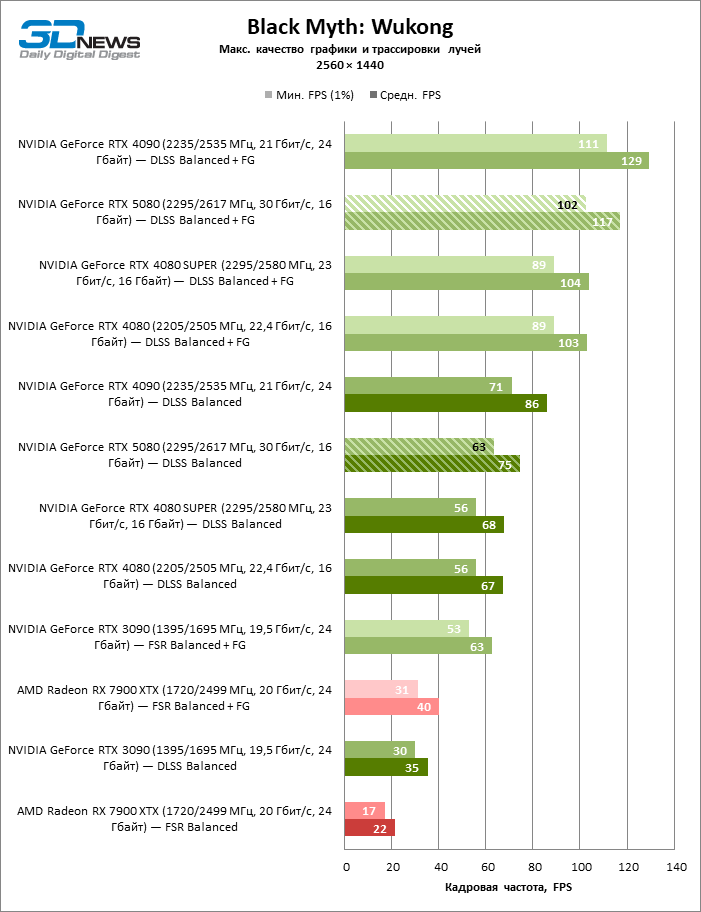
GEFORCE RTX 5080 graphics cards have excessive performance for rasterized games in 1080P mode and at the same time cannot work at full force with low screen resolution even on platforms with advanced central processors. Be that as it may, the RTX 5080 develops the personnel frequency is much higher than 100 FPS in the vast majority of test games. Only Black Myth: Wukong, where Framretic above 60 FPS, is hardly given even the most powerful GPU, was a noticeable exception.
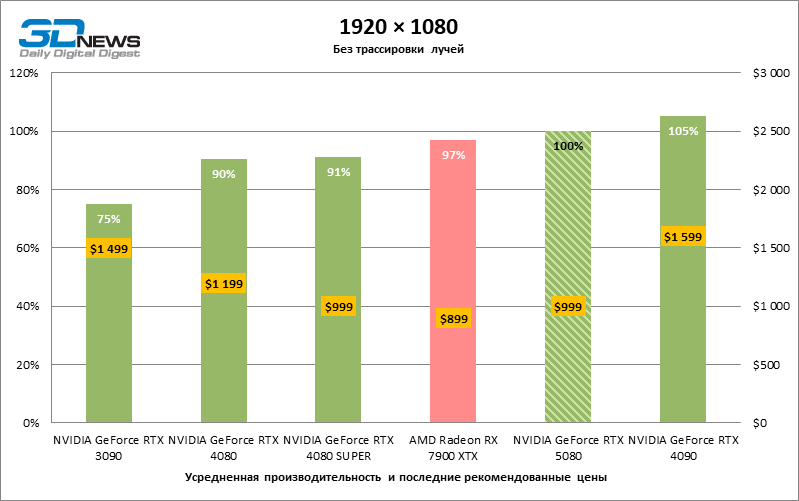
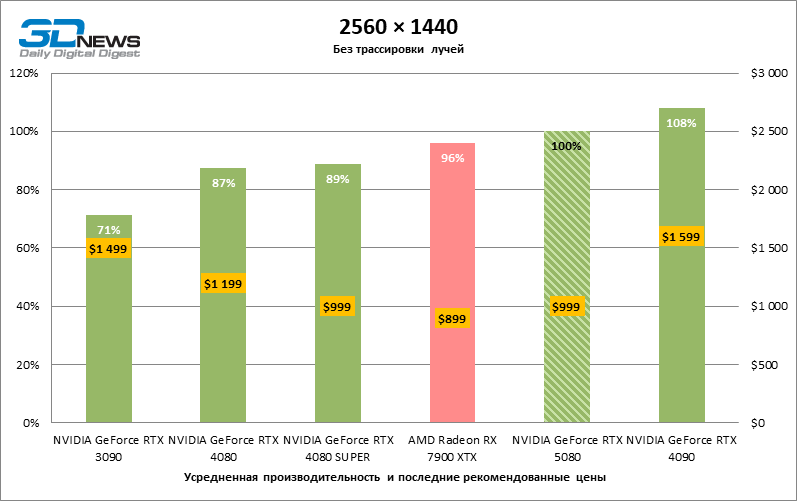
Due to the non -optimal test conditions, the average results of testing participants are distributed in a very narrow range. However, we can already talk about some trends. So, compared with the GeForce RTX 4080 or RTX 4080 Super, the speed of the 80th model increased by only 10-11 %. The Radeon RX 7900 XTX is almost inferior to the novelty, and the GeForce RTX 5090 has an equally insignificant advantage. The GeForce RTX 5080 looks like a noticeable upgrade only against the background of the GeForce RTX 3090, providing an increase in the average frame of 33 %.
⇡#Game tests (2560 × 1440)
General conclusions about the results of the GeForce RTX 5080 in 1080P mode can also be extended to games without reiterating with a resolution of 1440p. None of the test titles are able to load the new NVIDIA accelerator so that the average framework drops below 60, and, more often, and 100 FPS. However, there is less and less doubts that breakthrough speed from RTX 5080 should not be expected.
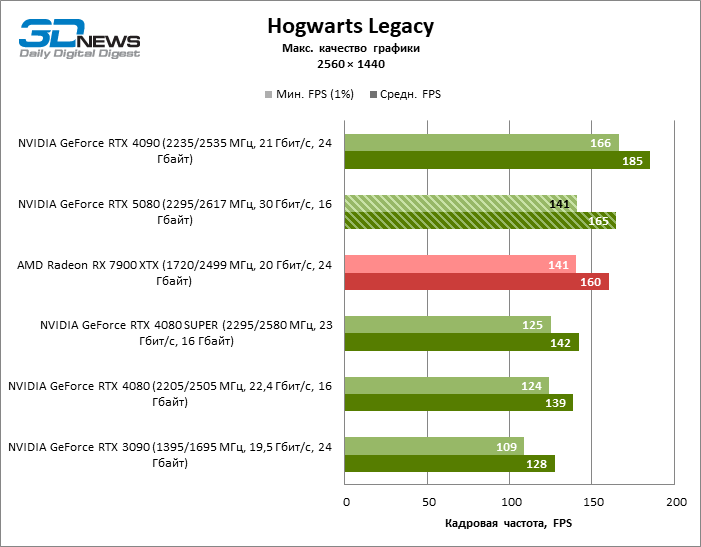
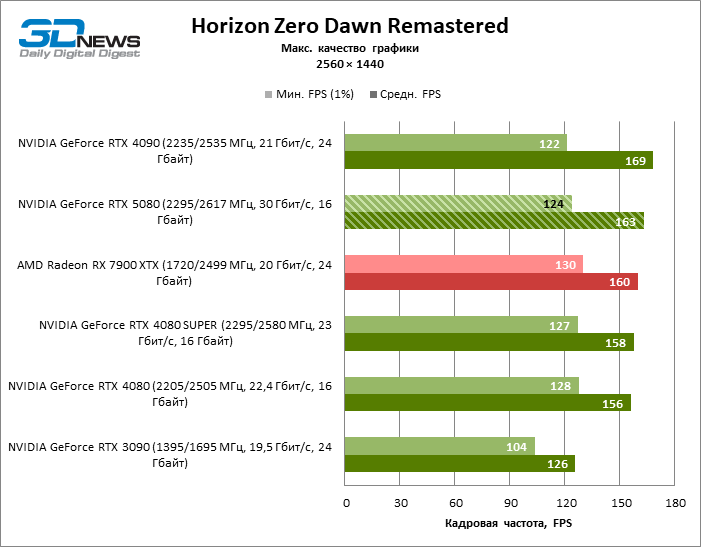
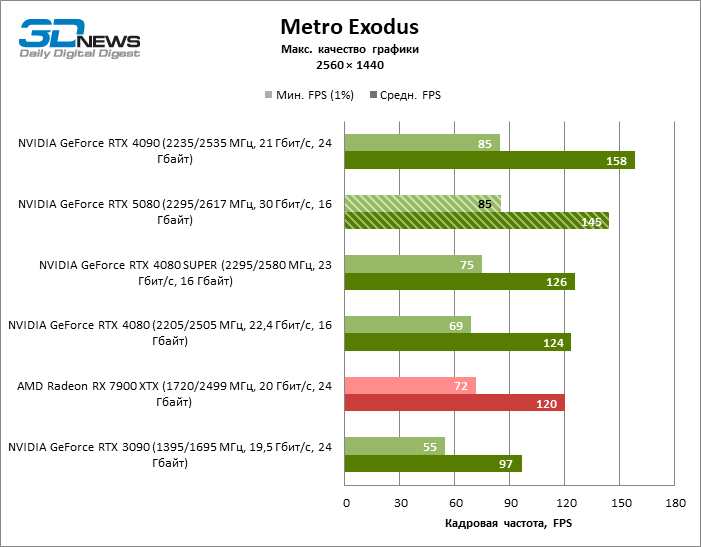
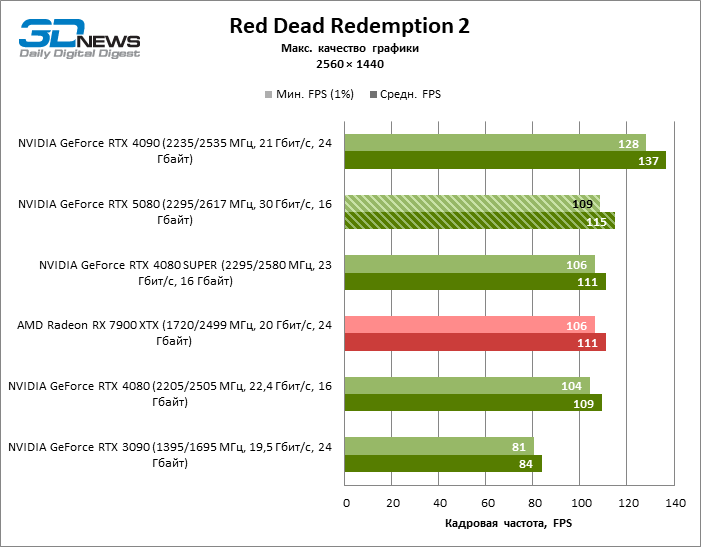
The hero of the review was 40 % faster than the Vice-Flagmark model of the year before last, but the distance between the 80s of the 50th and 40th line is reduced to 12-14 % of the personnel frequency. Radeon RX 7900 XTX lags RTX 5080 by 4 % FPS, and the GeForce RTX 4090 went forward at a distance of 8 %.
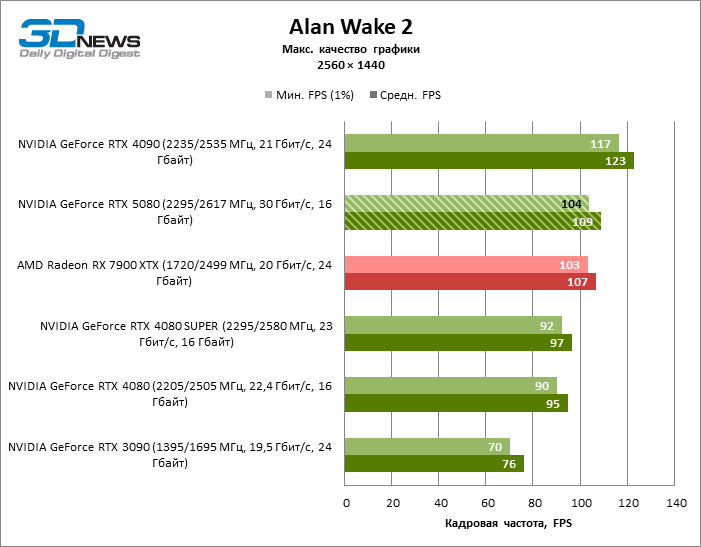
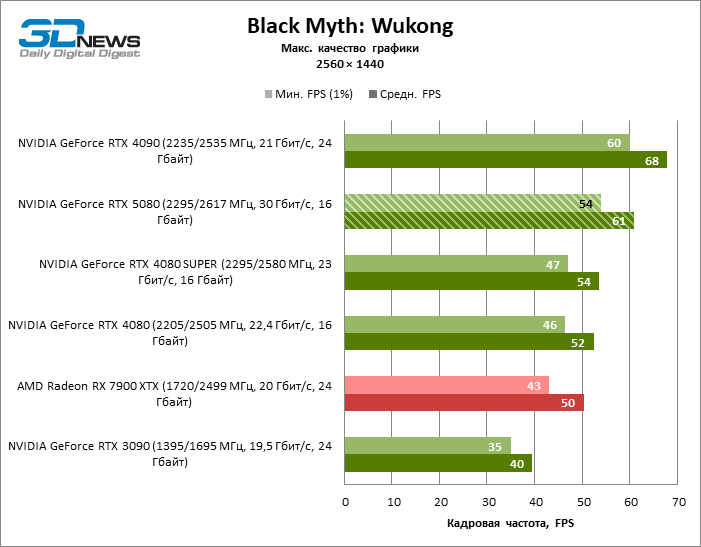
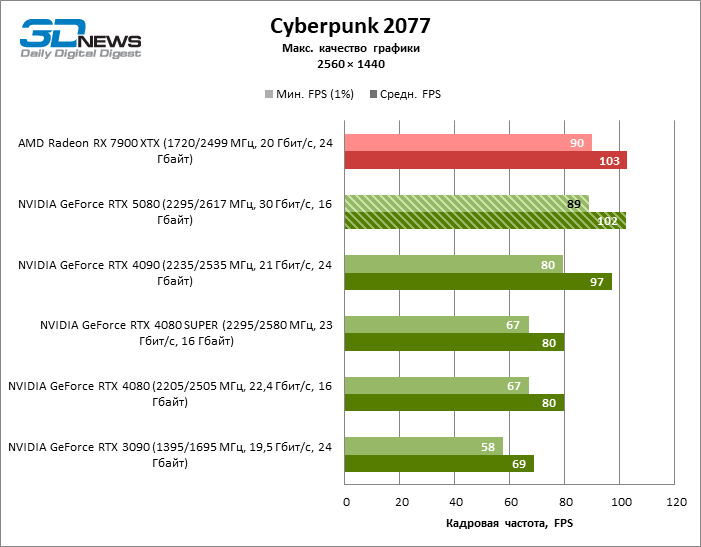
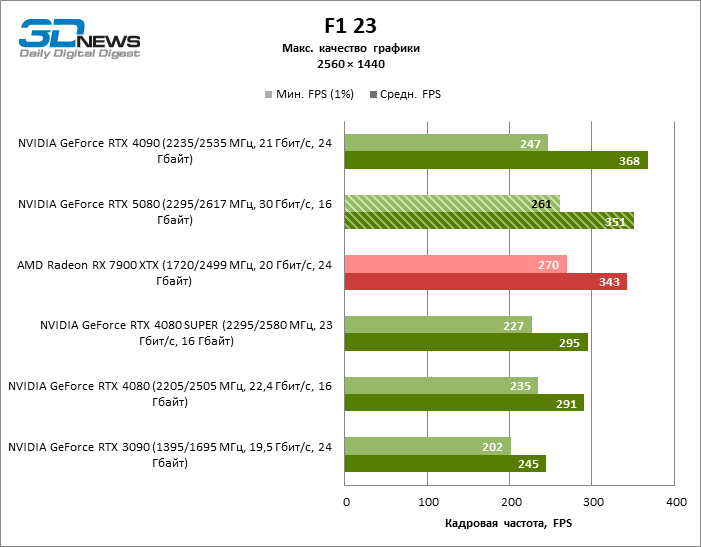
⇡#Game tests (3840 × 2160)
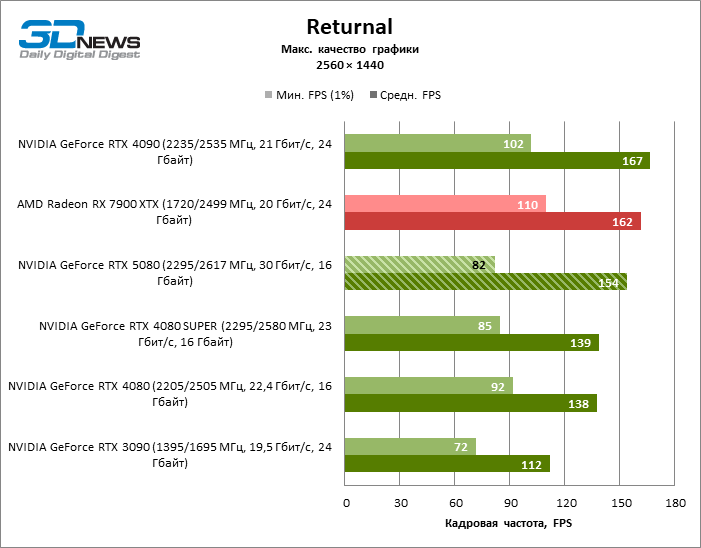
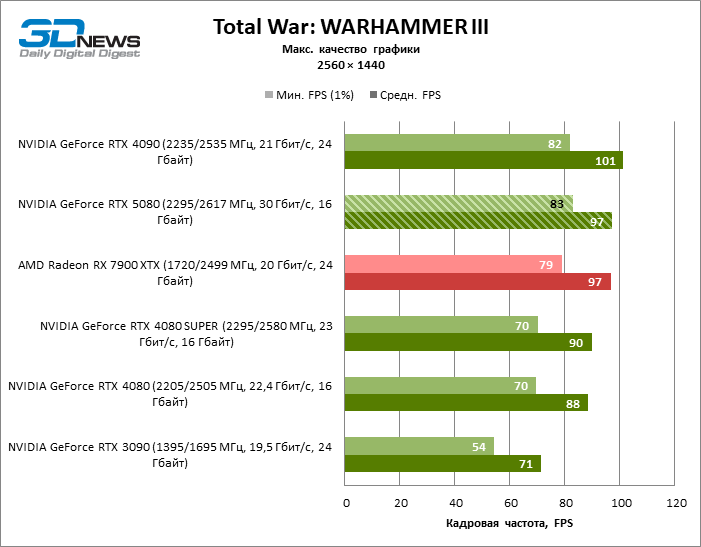
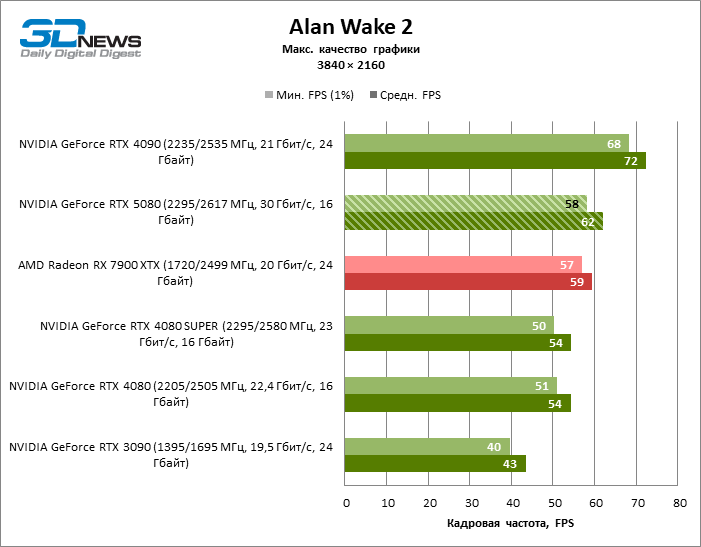
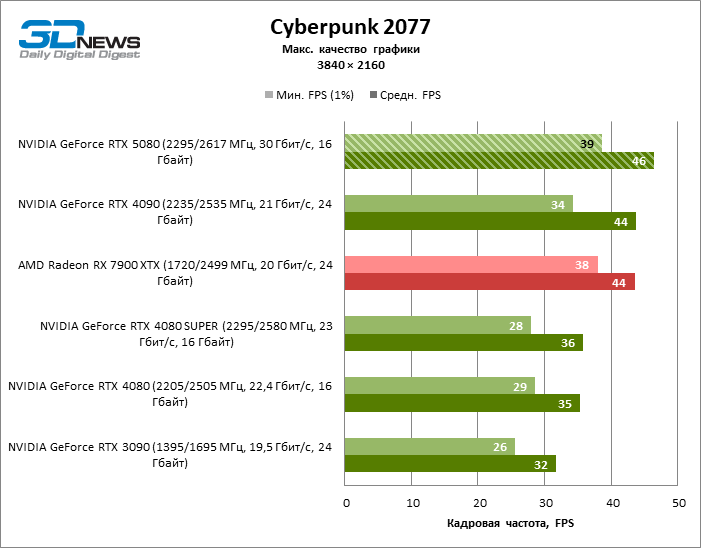
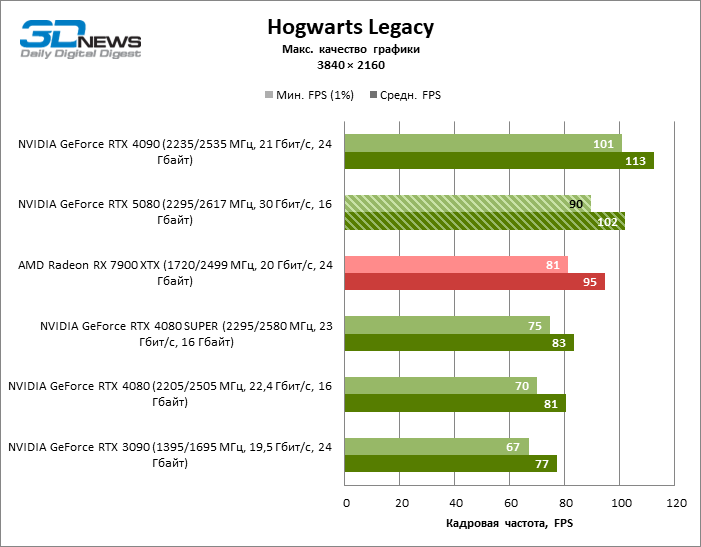
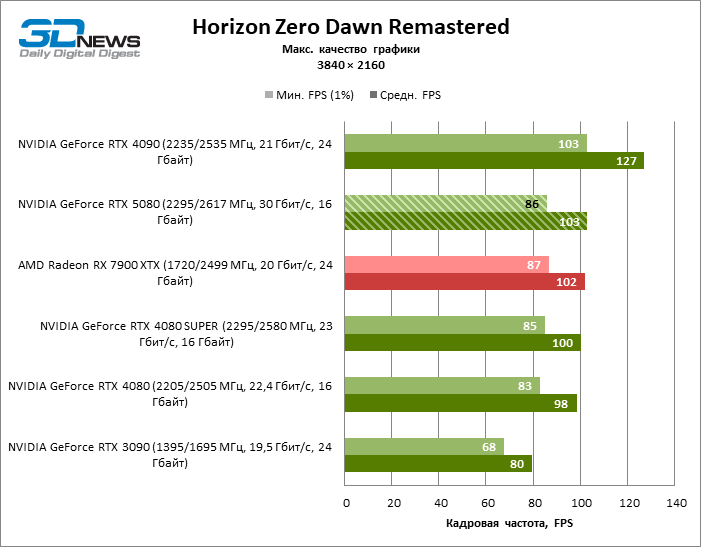
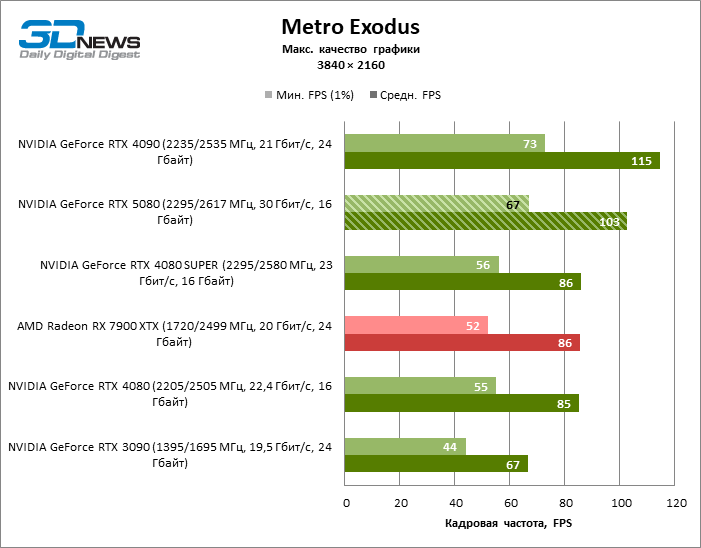
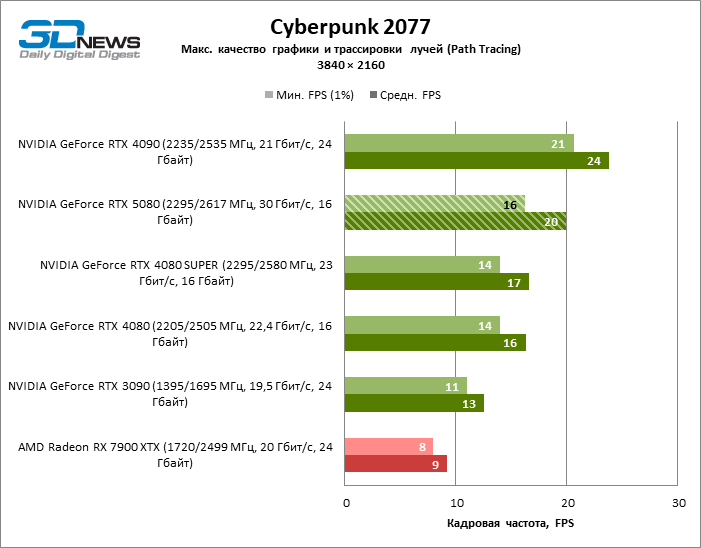
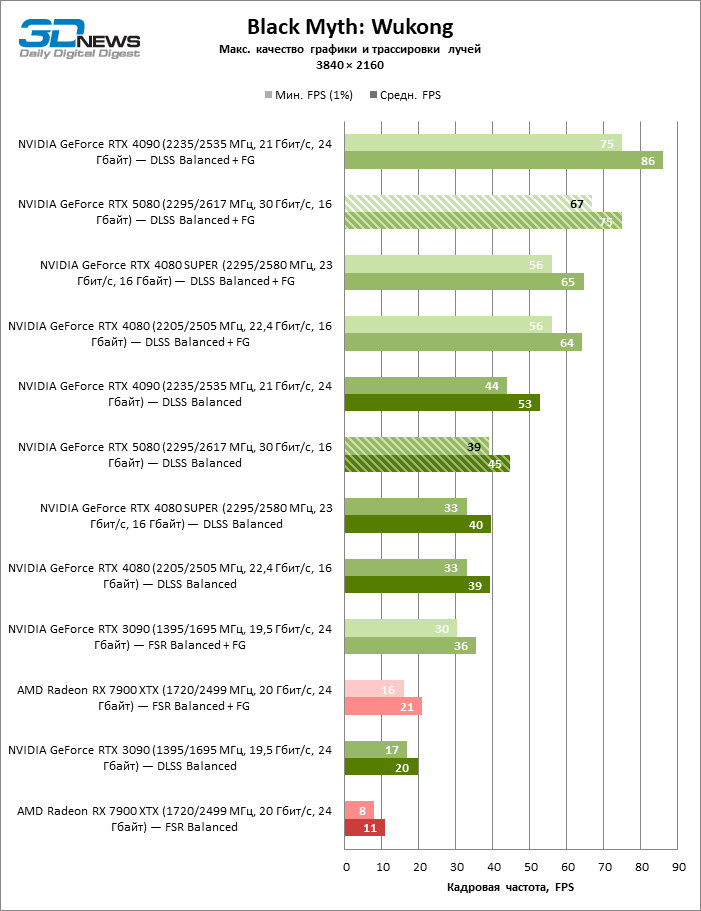
The GeForce RTX 5080 is positioned as an accelerator for games on a 4K screen. And he, indeed, develops a Freimrat from 60 FPS in most titles (and in some it is still a hundred). The expected exceptions were Black Myth: Wukong and Cyberpunk 2077.
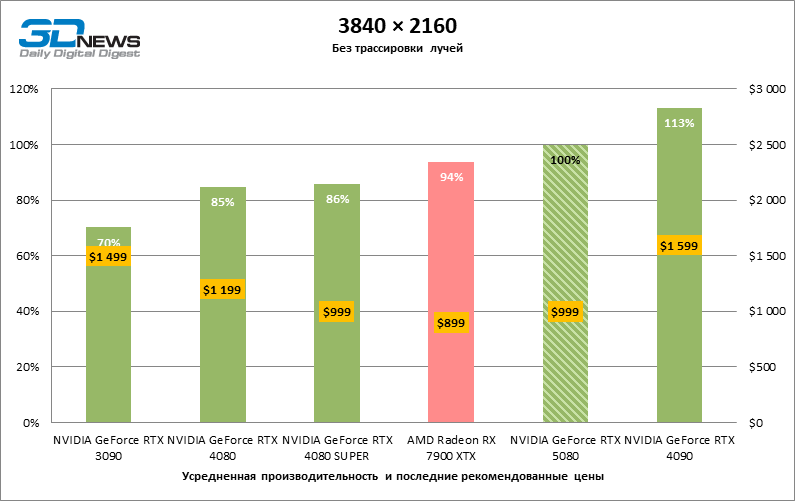
The difference between the compared devices has reached the maximum values possible without involving tracing rays, but the GeForce RTX 5080 still does not look like the next generation device. Compared to the GeForce RTX 3090, the RTX 5080 speed was 43 % higher, but if you take the GeForce RTX 4080 and RTX 4080 Super, the growth is reduced to 16-18 % FPS. In turn, the advantage of the GeForce RTX 4090 increased to 13% of the average framework. Finally, the main spoiler of the GeForce RTX 5080 in rasterization remains the Radeon RX 7900 XTX, which lost only 6 % FPS.

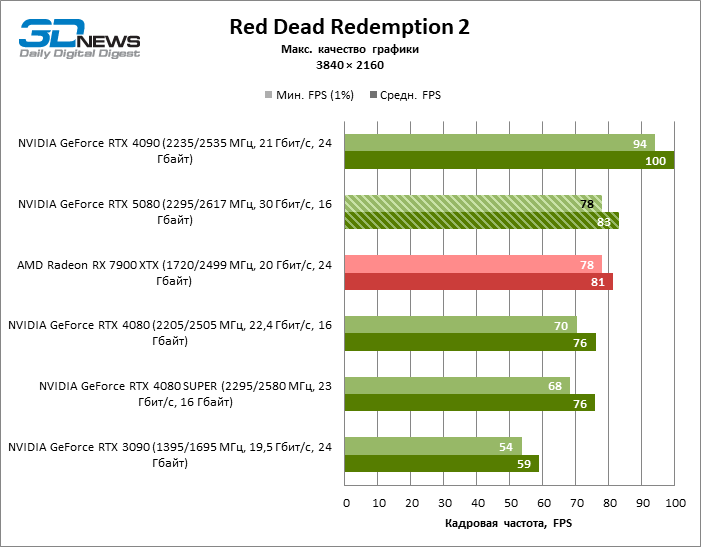
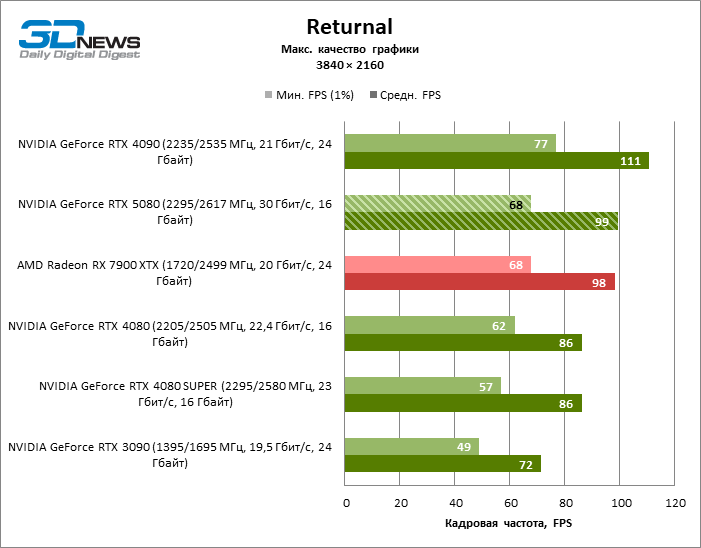
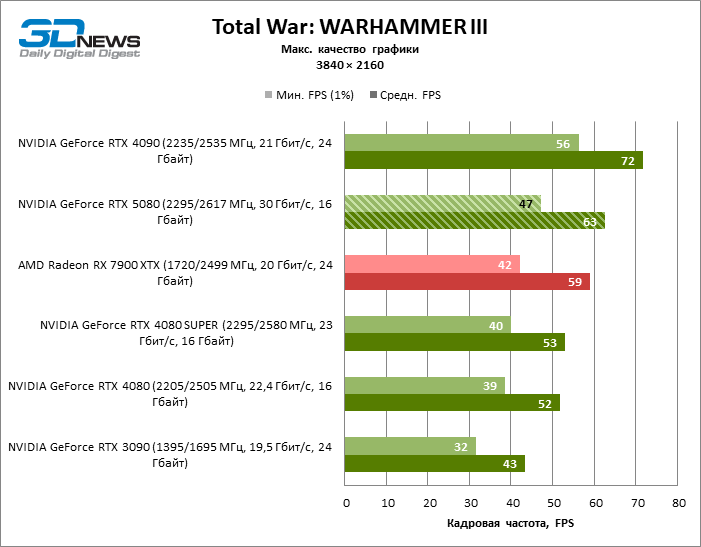
⇡#Ray-traced gaming tests
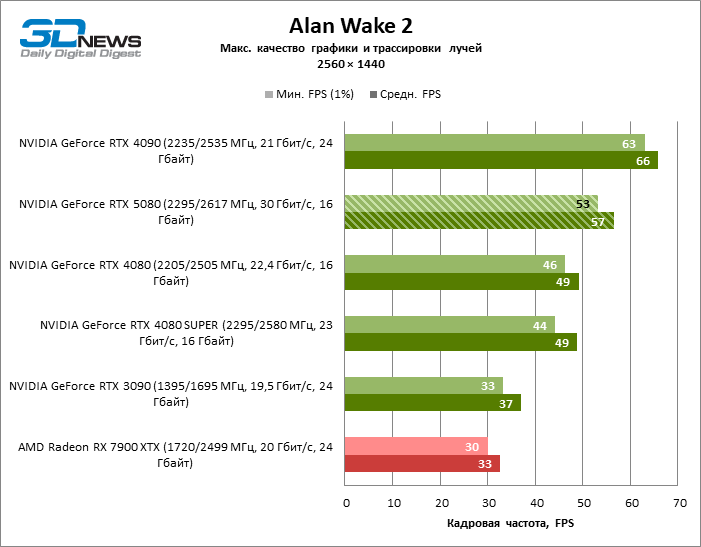
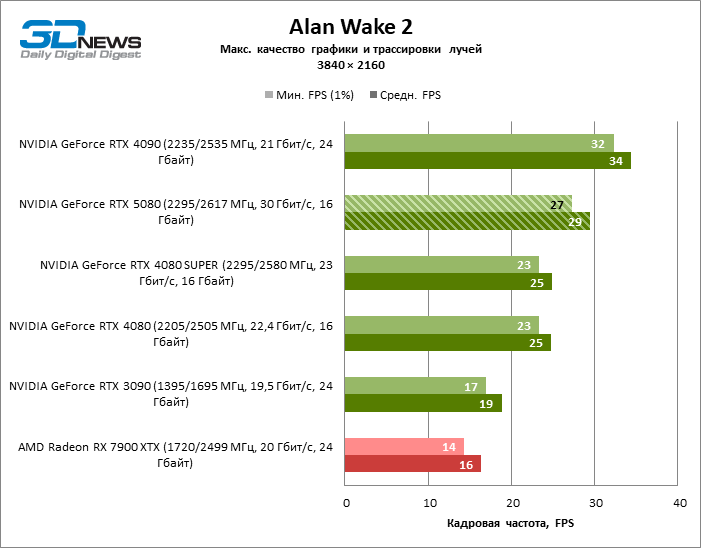
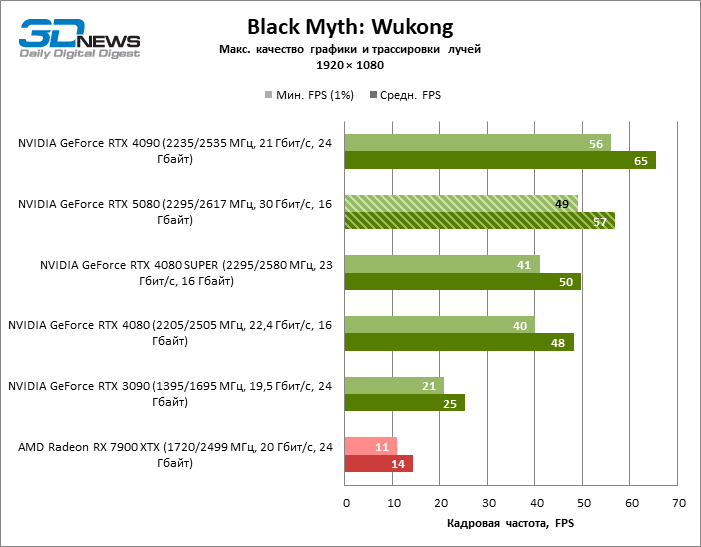
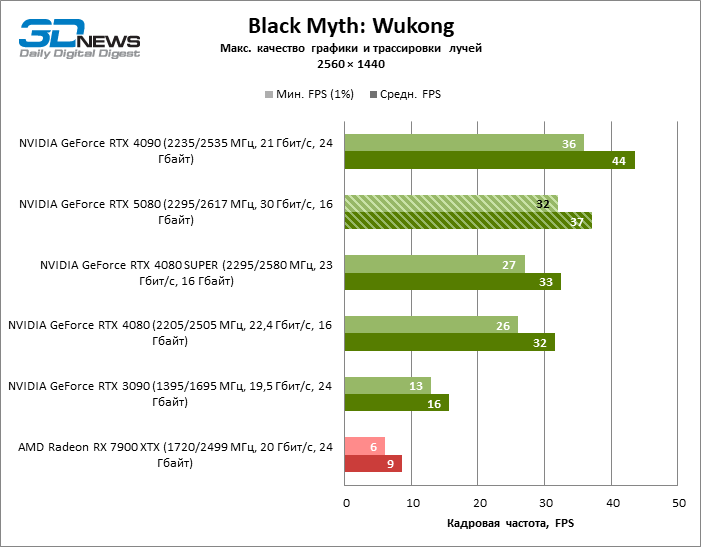
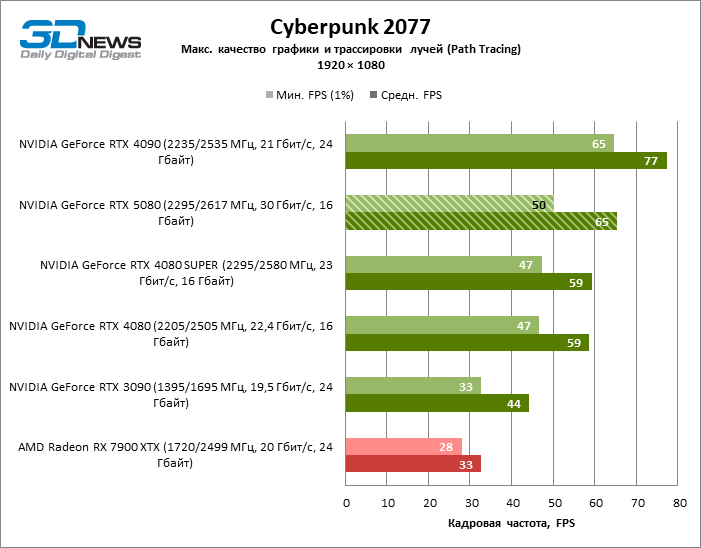
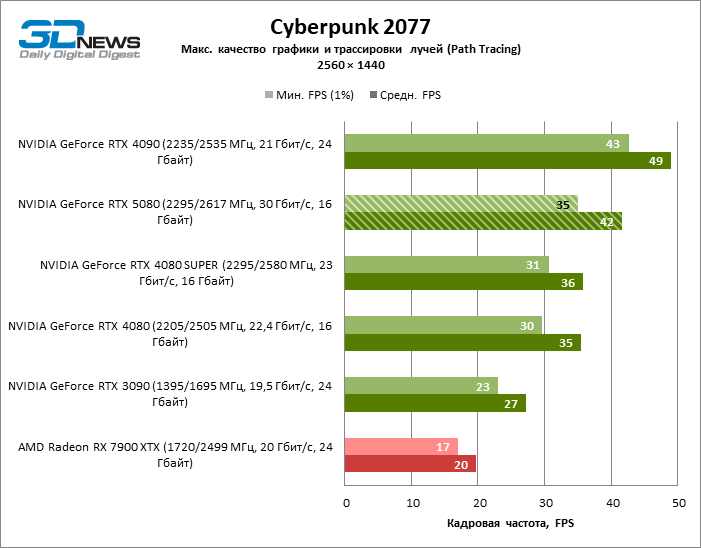
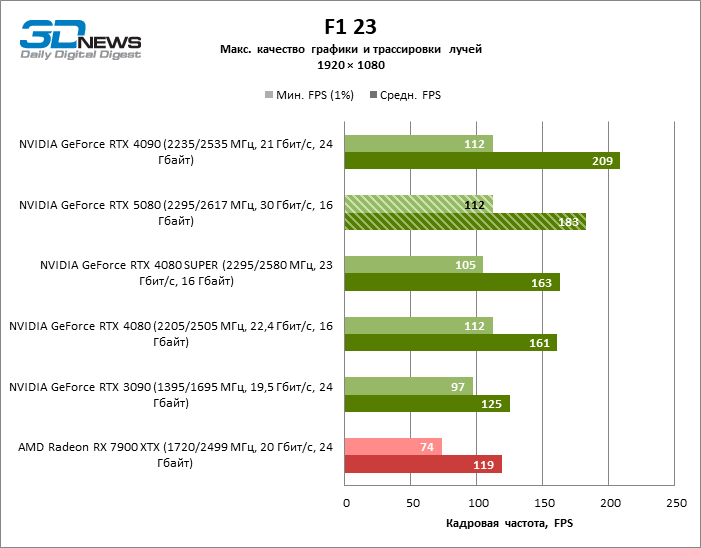
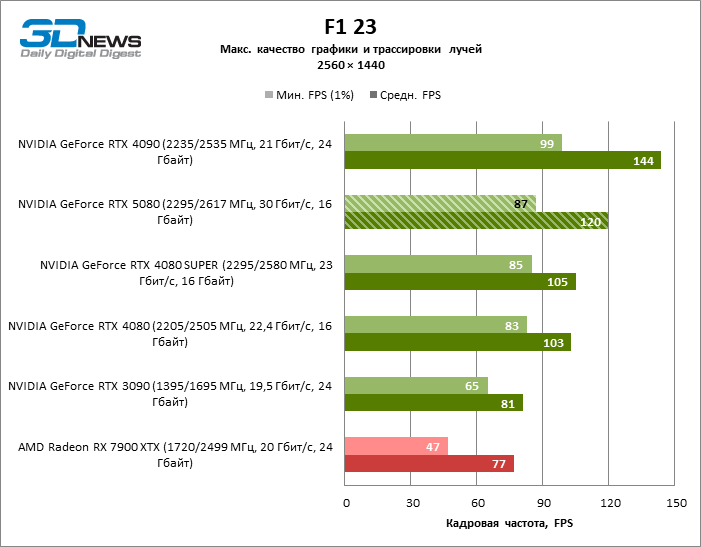
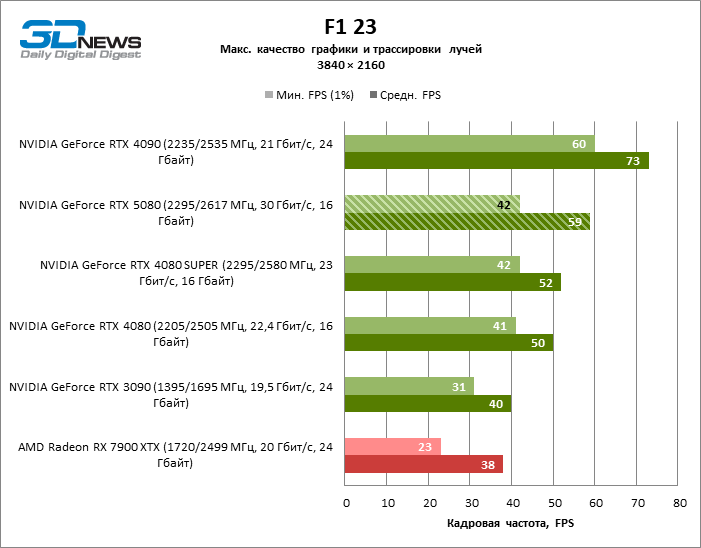
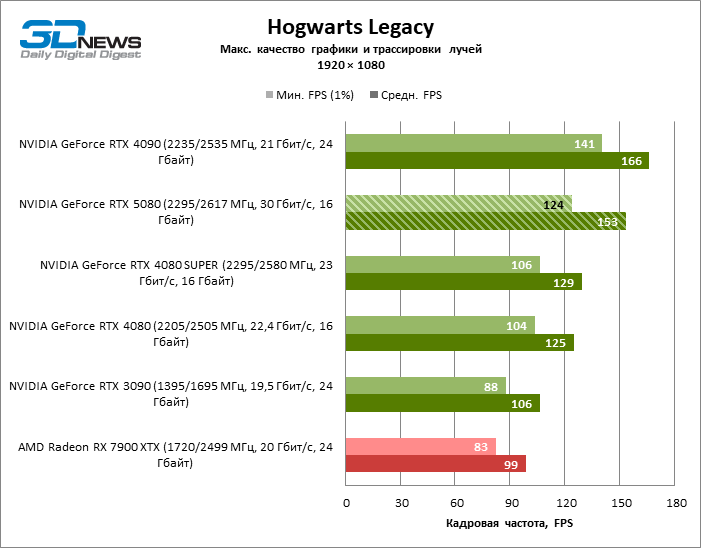
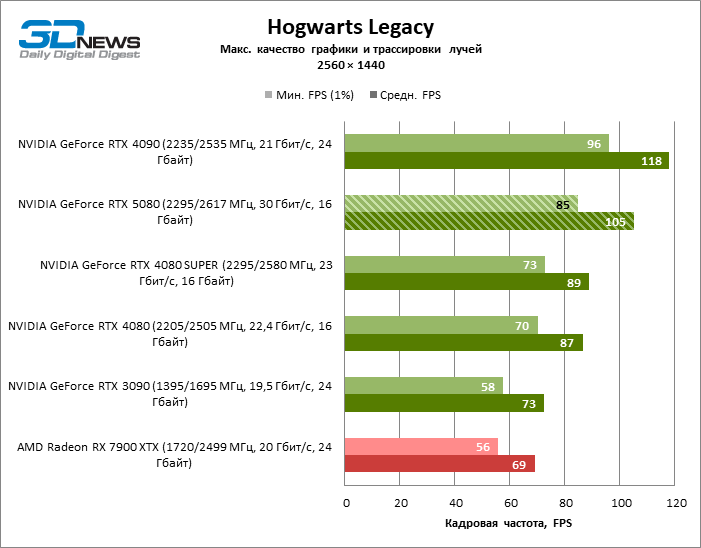
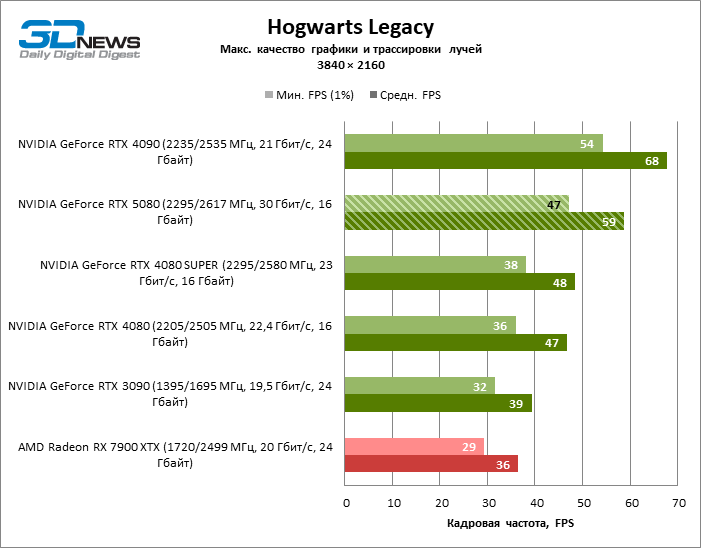
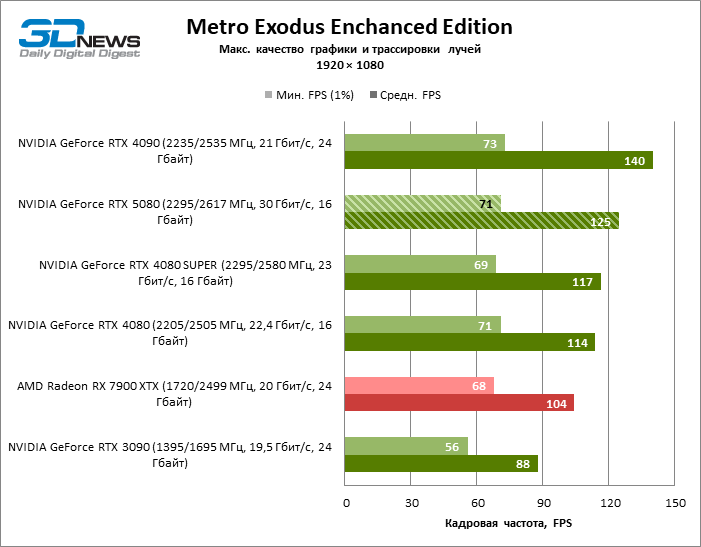
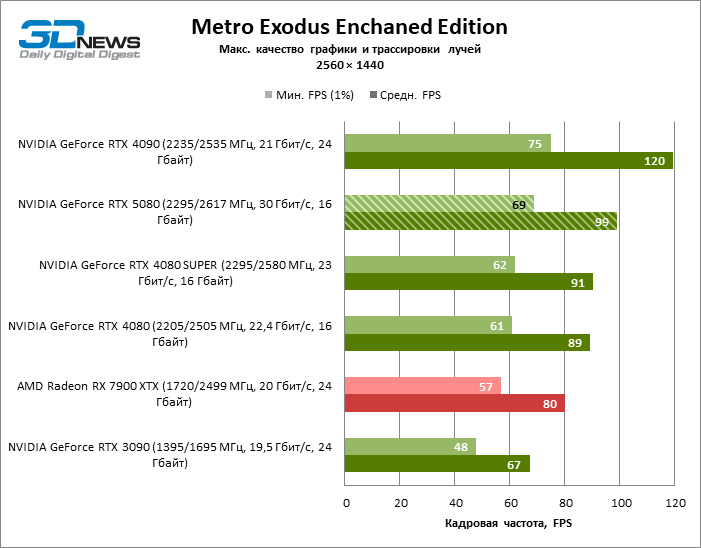
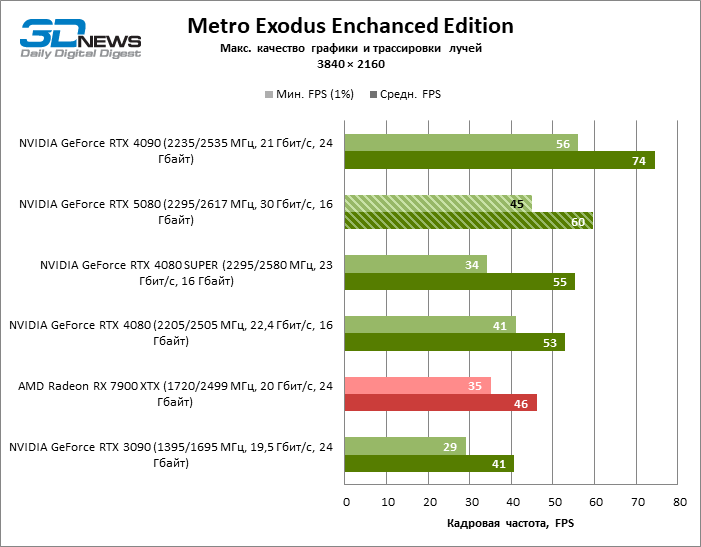
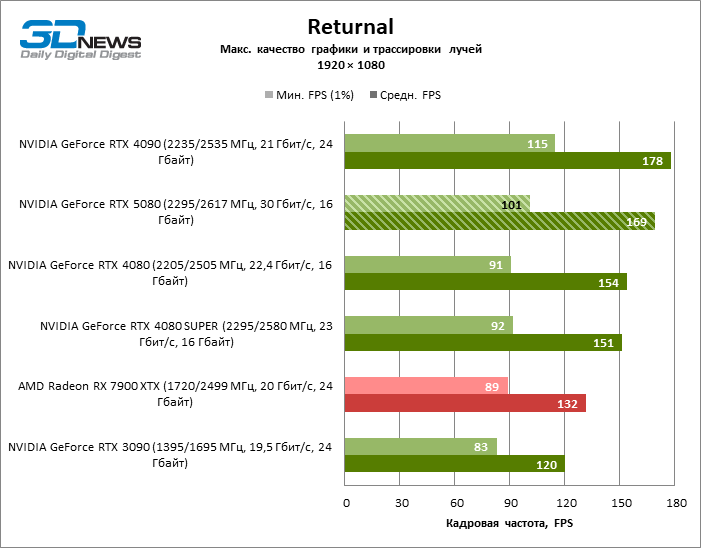
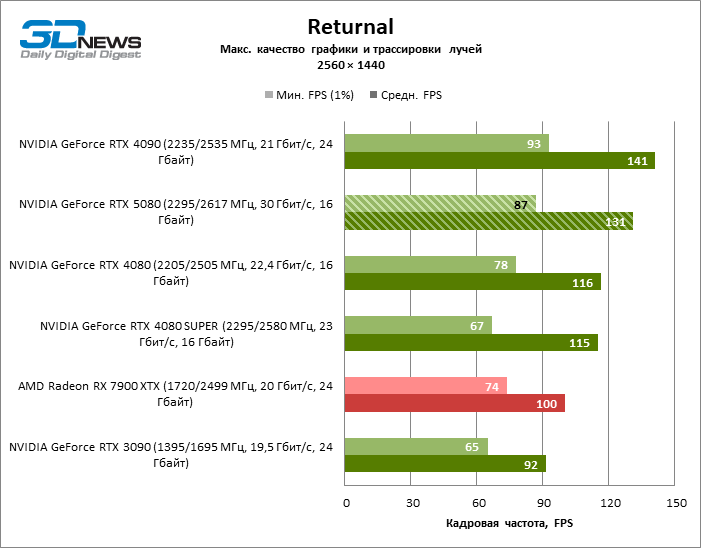
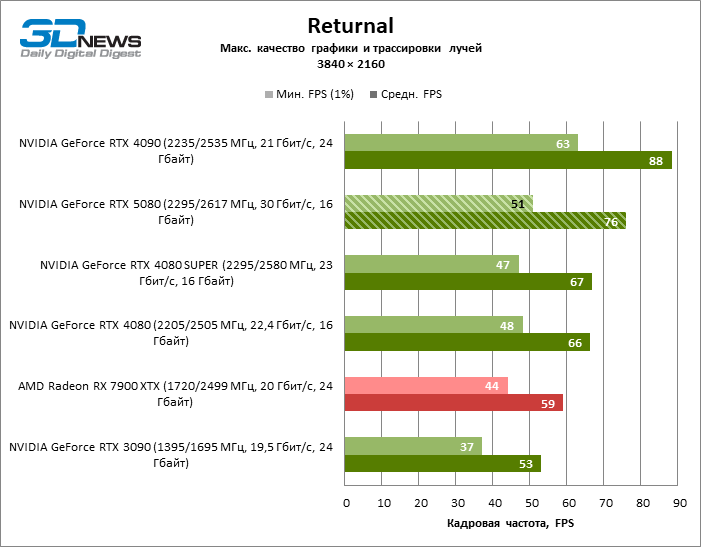
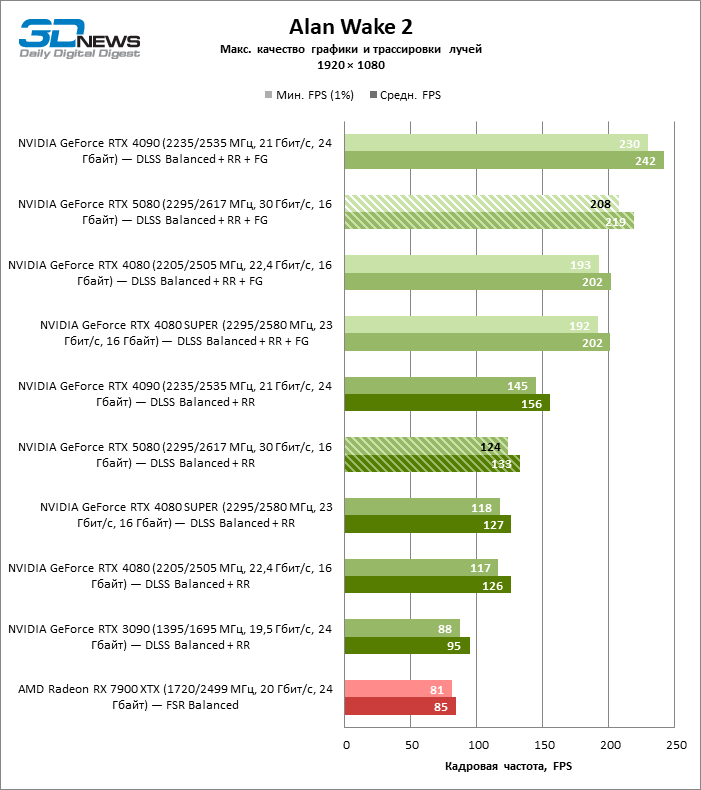
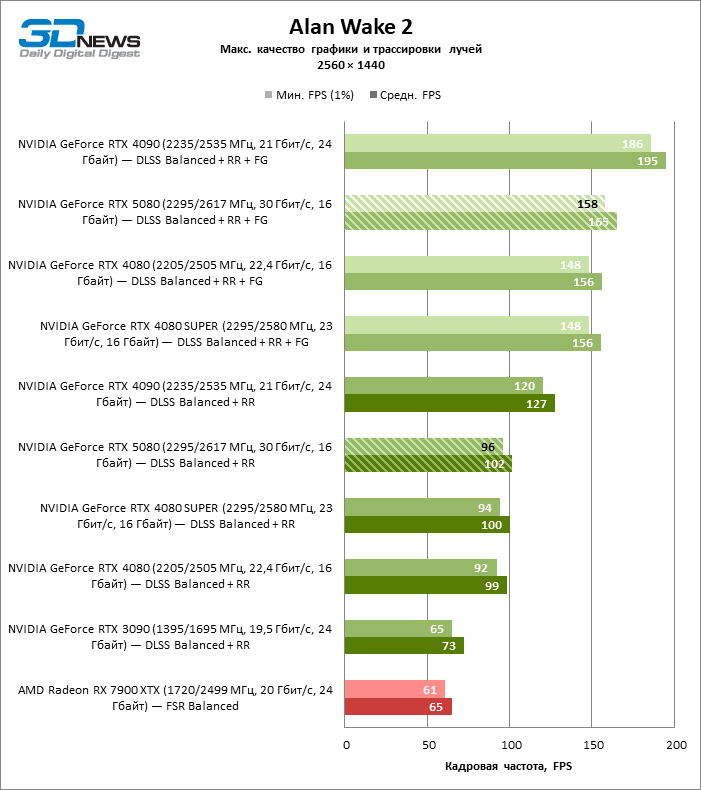
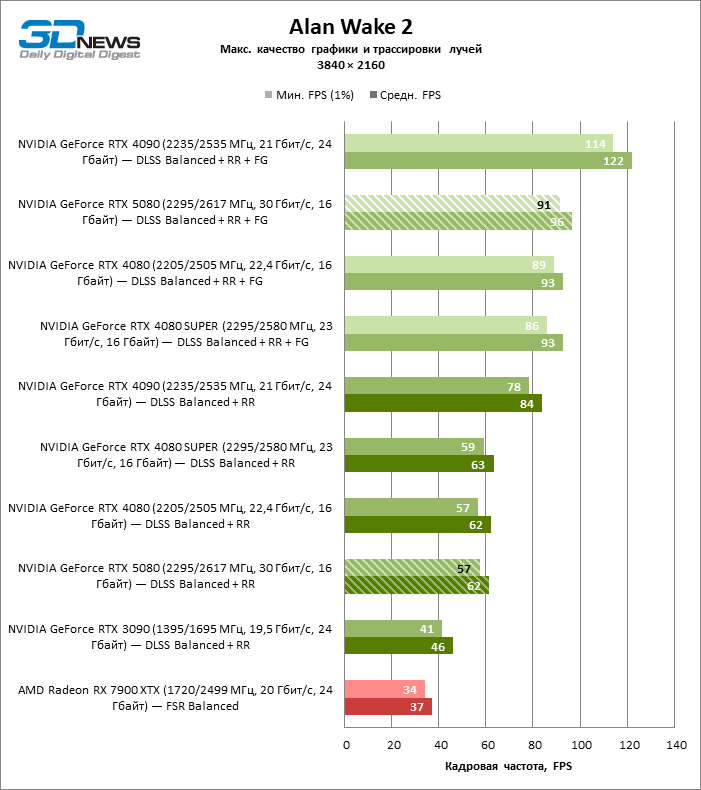
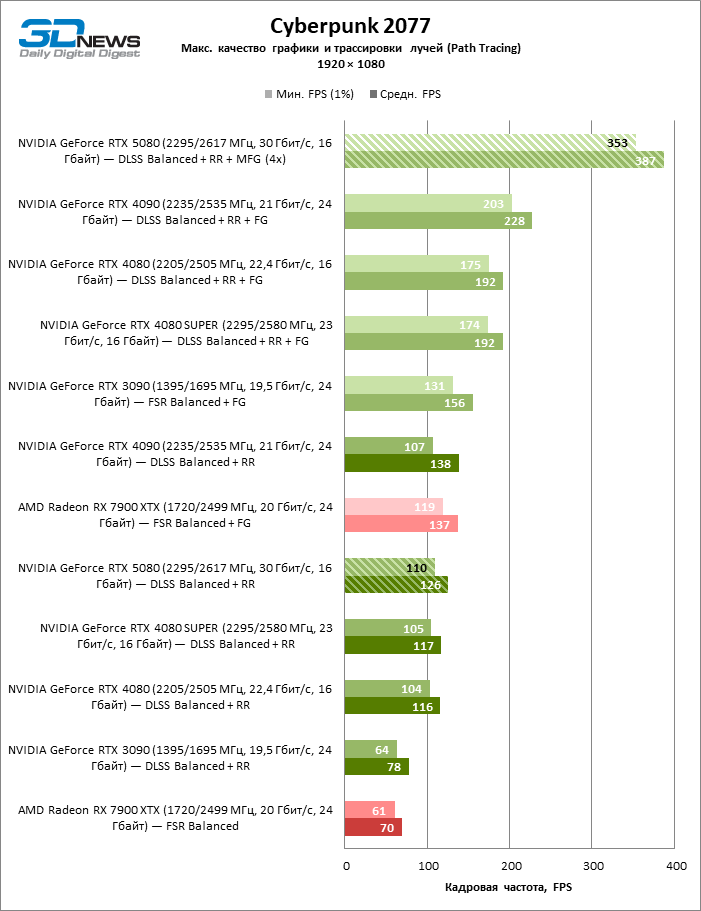
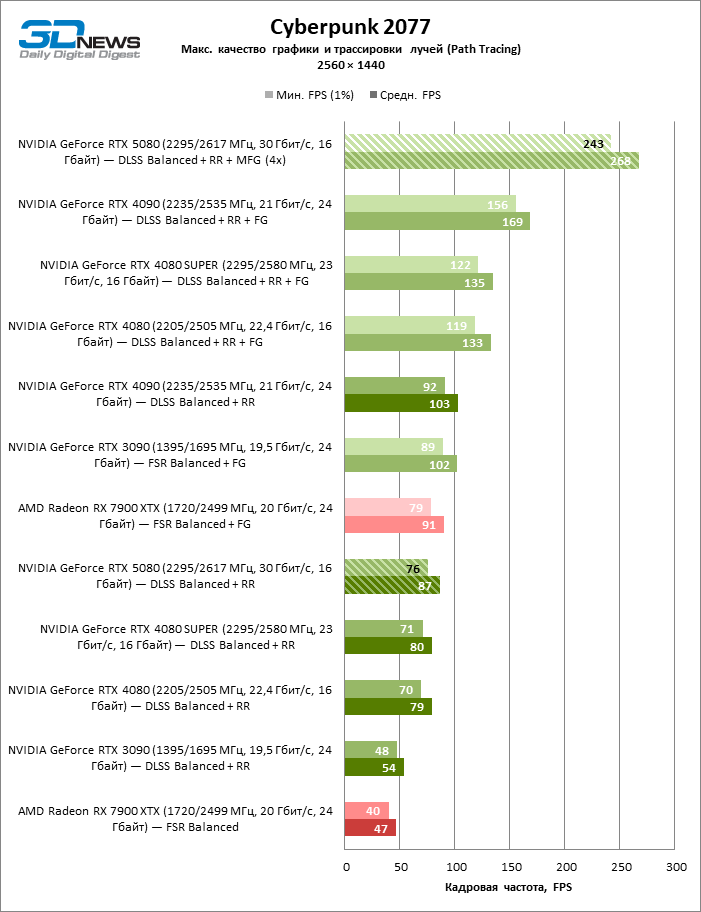
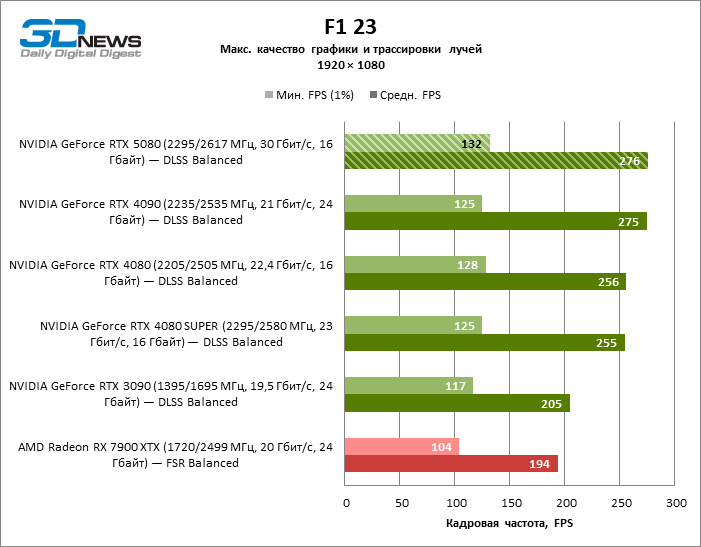
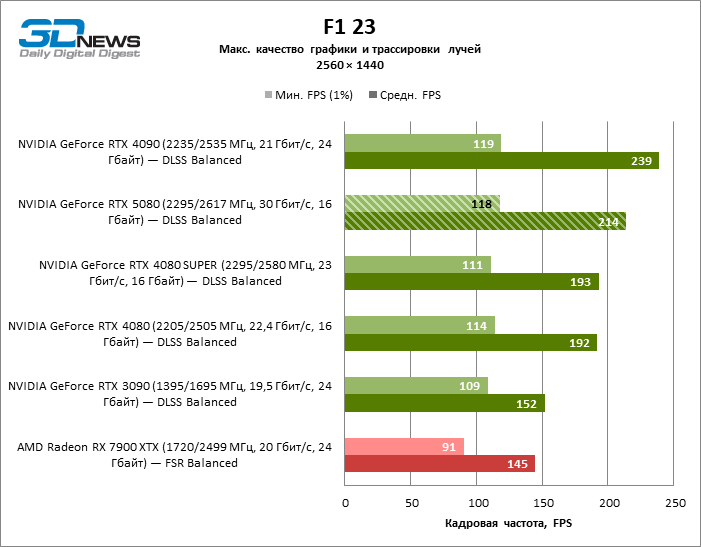
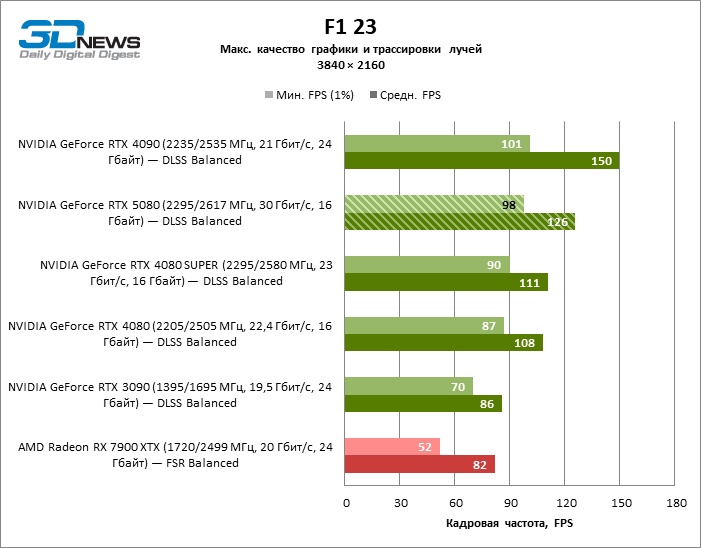
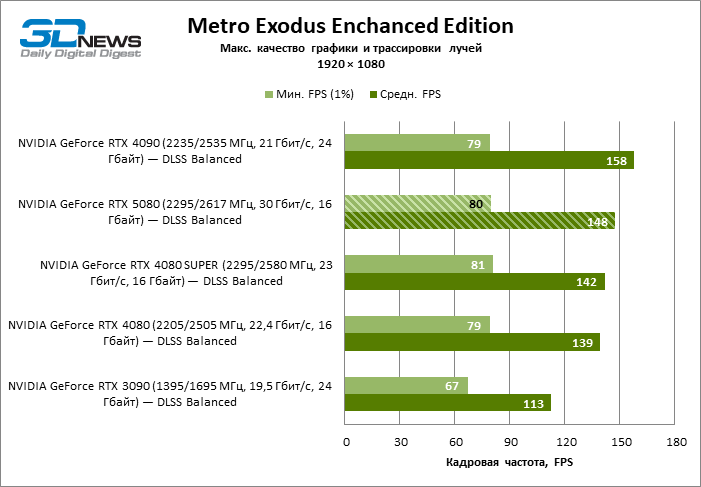
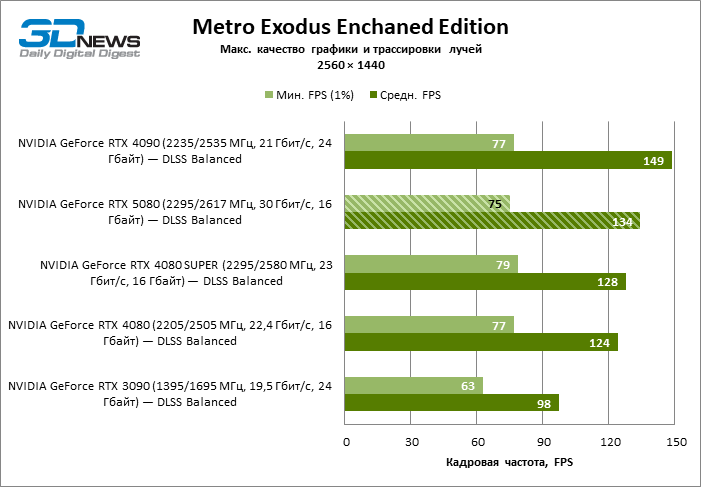
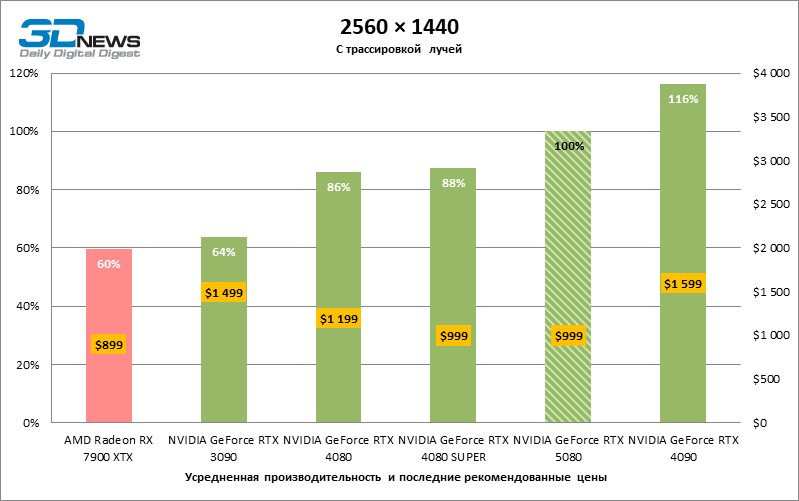
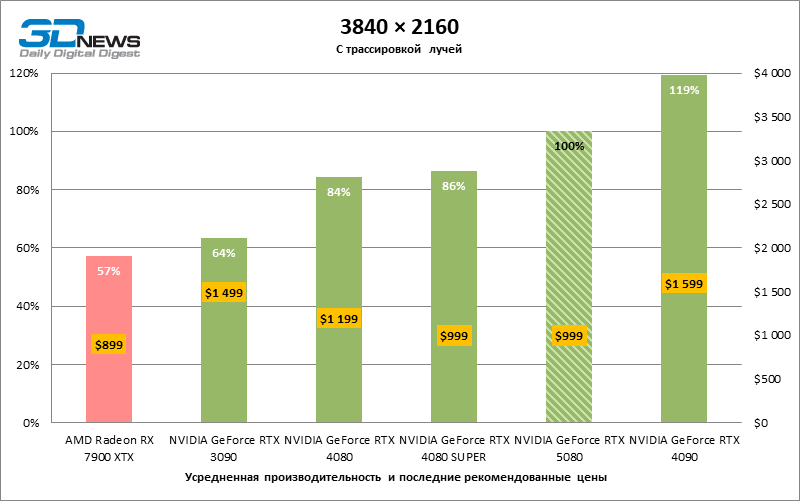
In the light of Blackwell’s innovation, aimed at the speed of rays trace, it is reasonable to expect that the GeForce RTX 5080 will best manifest itself in the benchmarks with RT, and this is partly the case. Completely traceed games work with a frame of at least 57 FPS when resolving 1080p, and hybrid rendering allowed RTX 5080 to close to 60 FPS on 4K-screen without scaling and generating frames.
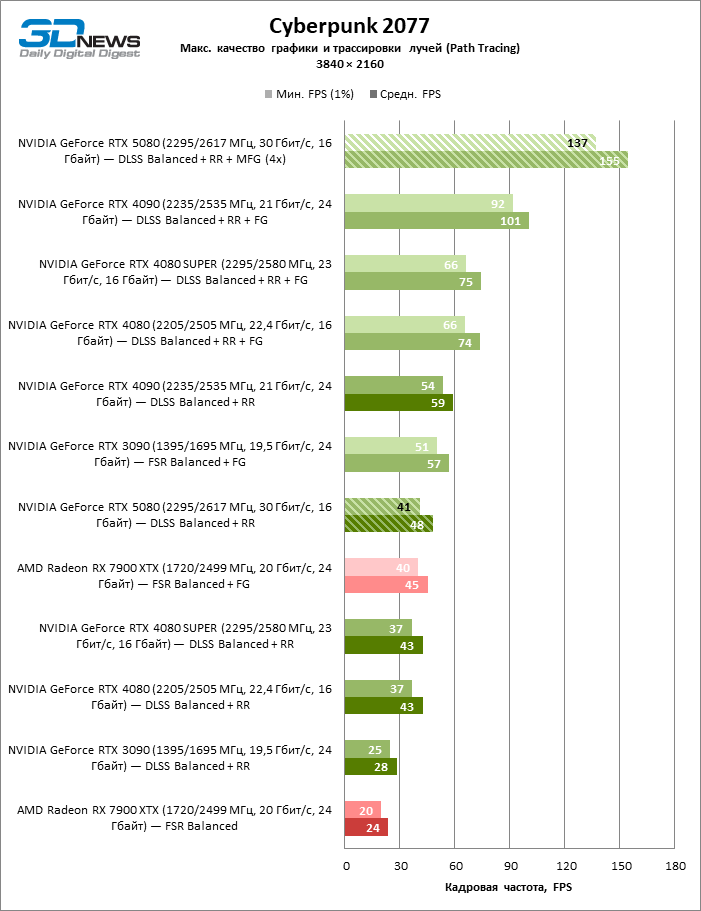
Reitreizing saved the GeForce RTX 5080 from annoying competition from the Radeon RX 7900 XTX: the averaged advantage of the “green” video card is 64–75 %, and in tests with trace of tracks even more. The distance between the GeForce RTX 5080 and RTX 3090 also increased to 53–57 % FPS. Alas, within the framework of neighboring GPU generations, the difference between the new 80th model and two versions of the previous increased, but is still disappointing 14-19 and 13–16 % of the personnel frequency. The GeForce RTX 4090, on the contrary, defended the leadership position with a margin from RTX 5080 by 12-19 %.
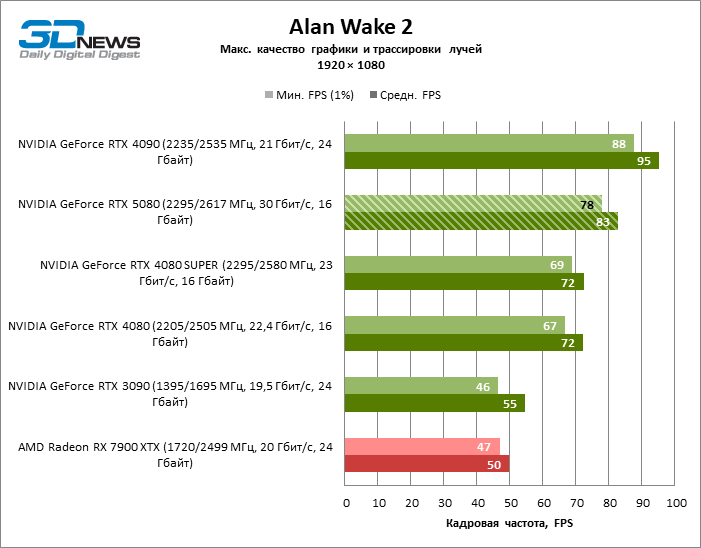
⇡#Gaming tests with ray tracing and frame scaling
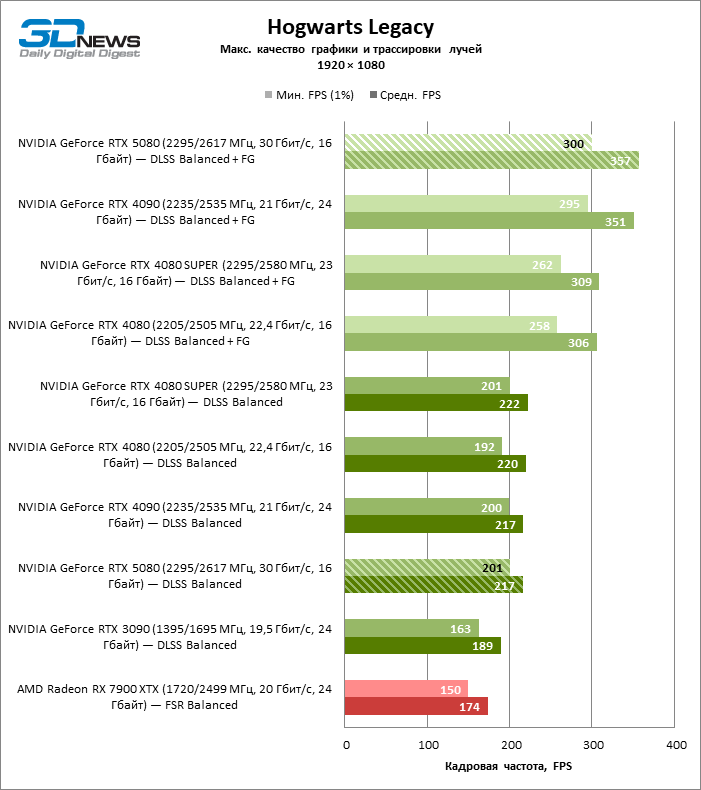
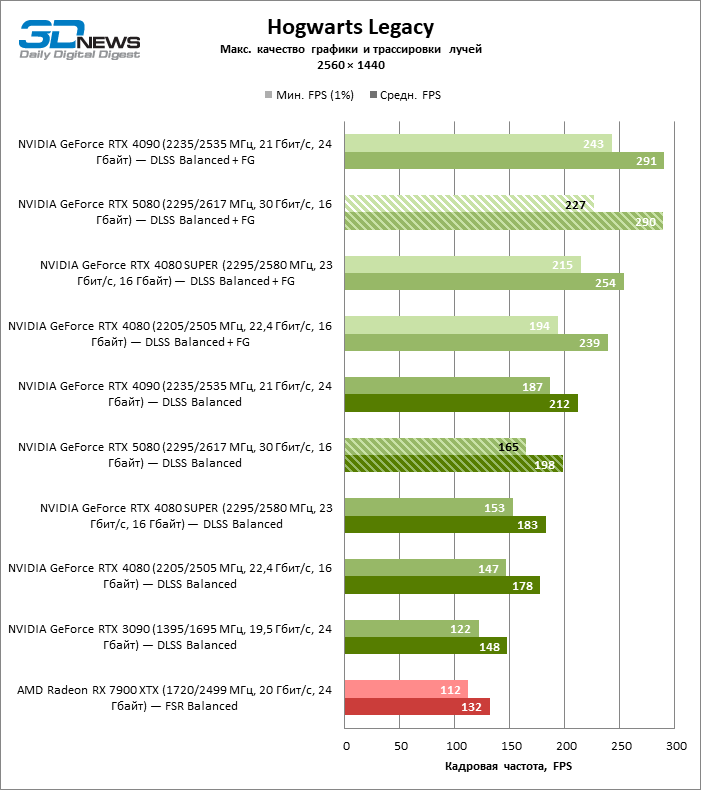
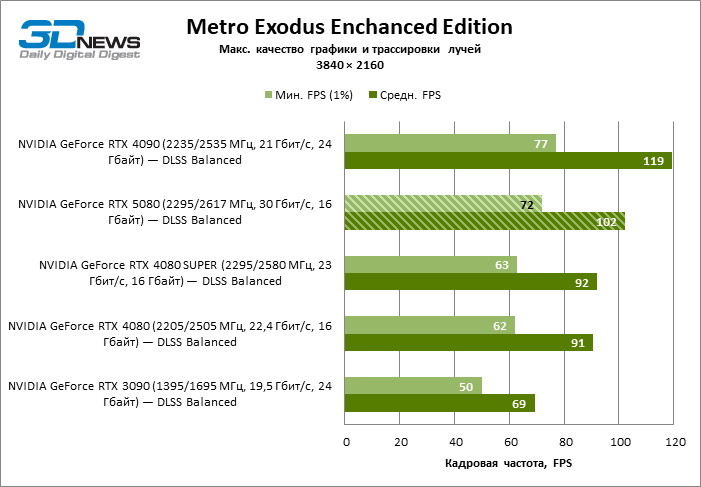
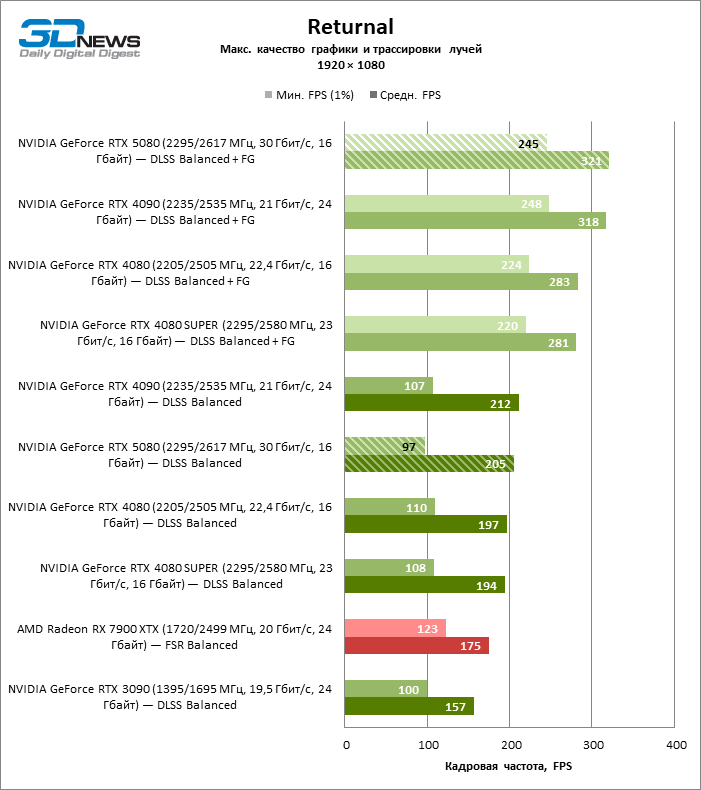
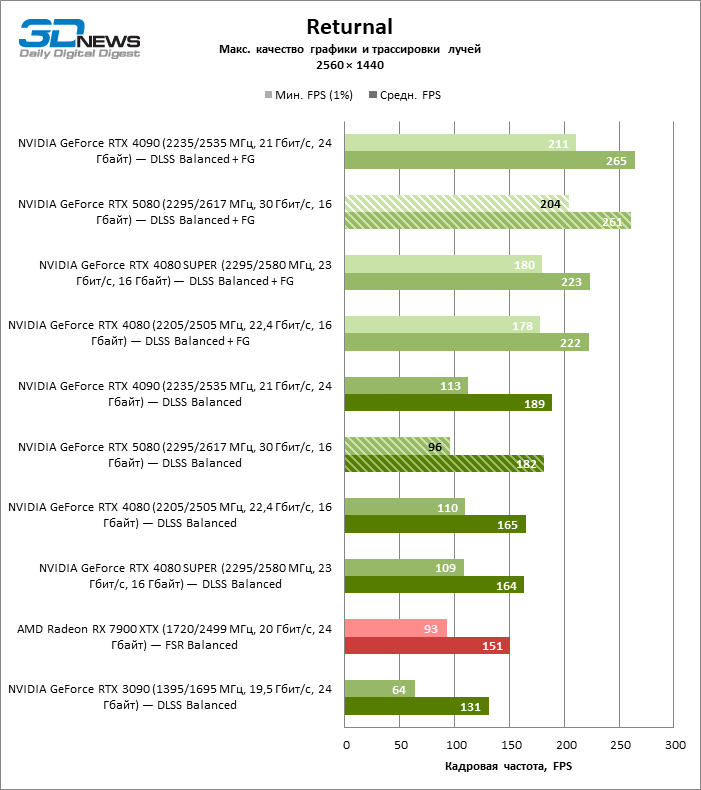
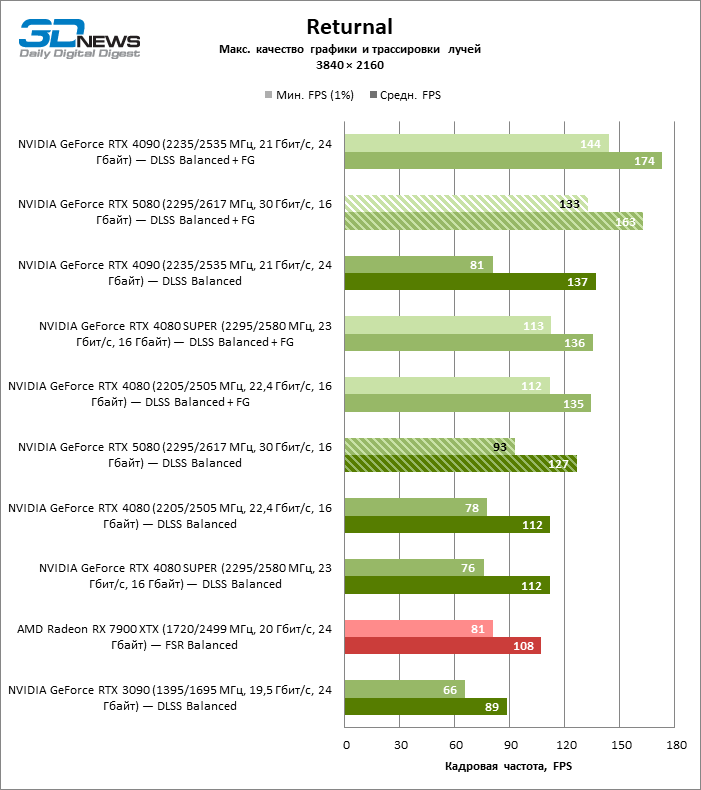
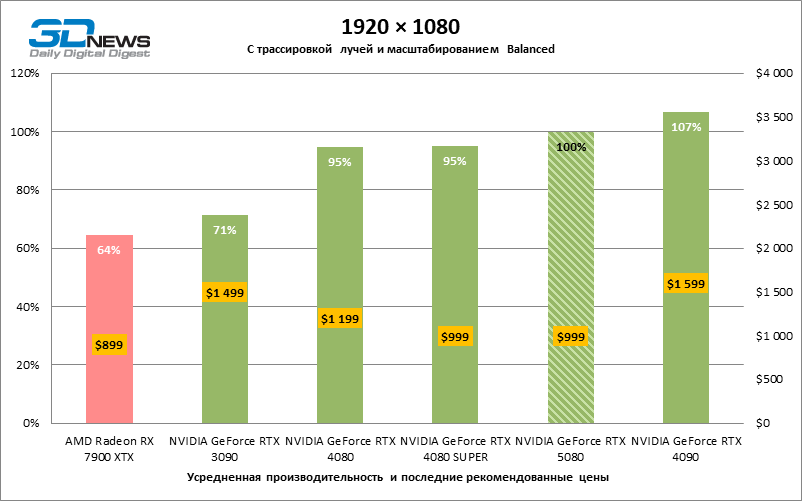
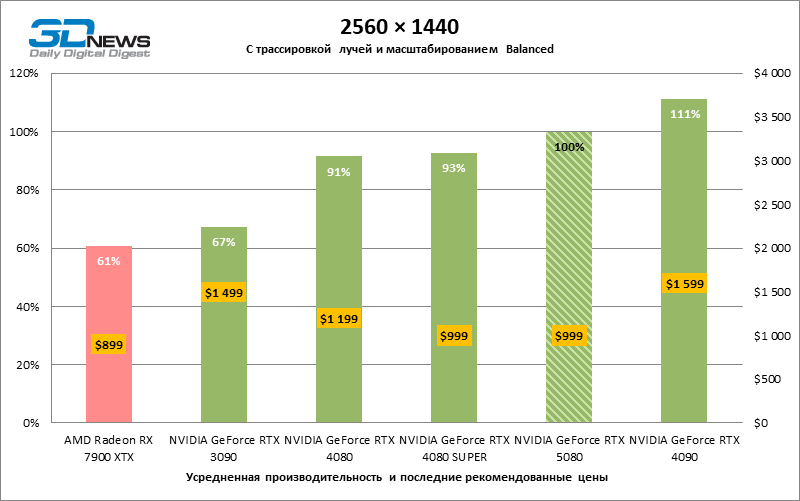
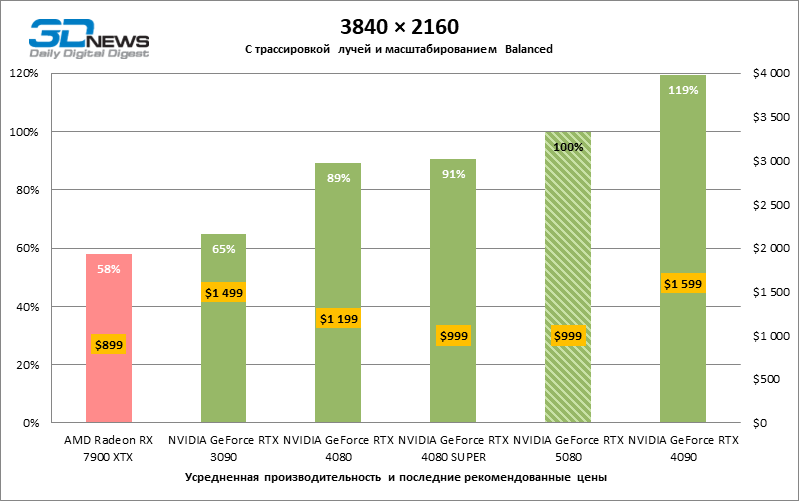
The scaling of shots with a moderate coefficient (Balanced) brought the GeForce RTX 5080 to a level above 100 FPS in games with hybrid rendering on 4K screen and more than 60 FPS-in fully traceed benchmarks with a resolution of 1440P. All NVIDIA accelerators have performed tests using DLSS RAY Reconstruction if this function is supported by the game.
Under the updated load, the rival video cards again became close to each other. The GeForce RTX 5080 is still ahead of the GeForce RTX 3090 and Radeon RX 7900 XTX for huge values of 40–54 and 55–72 % FPS. But the advantage of the novelty over the GeForce RTX 4080 and RTX 4080 Super decreased to the modest 6–12 and 5-10 % FPS, respectively. However, the GeForce RTX 4090 in these gaming conditions most realistic for powerful video cards exceeds RTX 5080 by only 7-19 %.

⇡#Overclocked gaming tests
Due to the way the Blackwell chips control the clock frequency, the formal increase of 500 MHz (and 457 MHz according to monitoring) does not speak everything about the work of the GPU “under the hood”. Be that as it may, for a video card, without an inexhaustible capacity of Palit Gamerock, it accelerates remarkably: in rasterized games on the 4K screen, the Framretite increased by an average of 11 %, which closely brought the GeForce RTX 5080 to the version of the GeForce RTX 4090 with near-repellent frequencies.
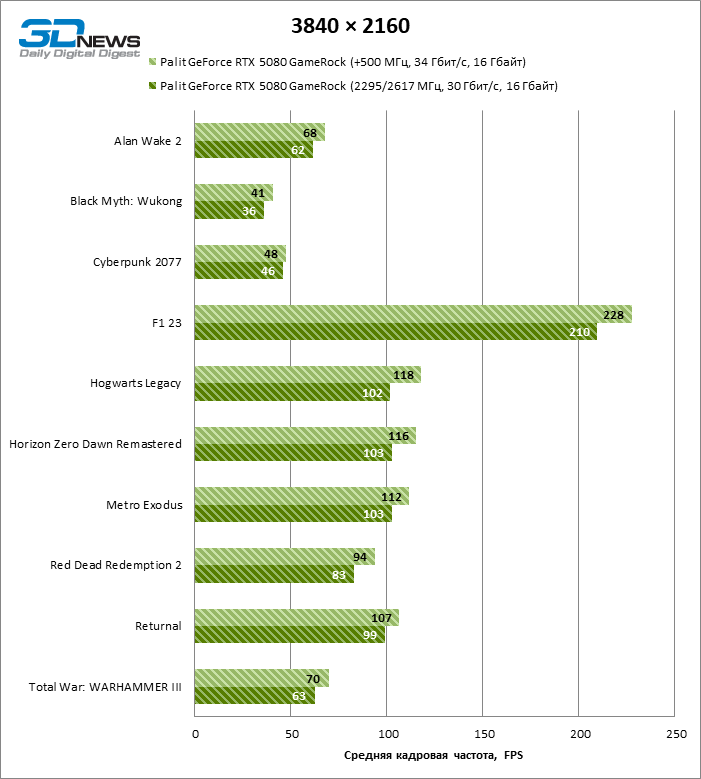
⇡#Tests in production applications
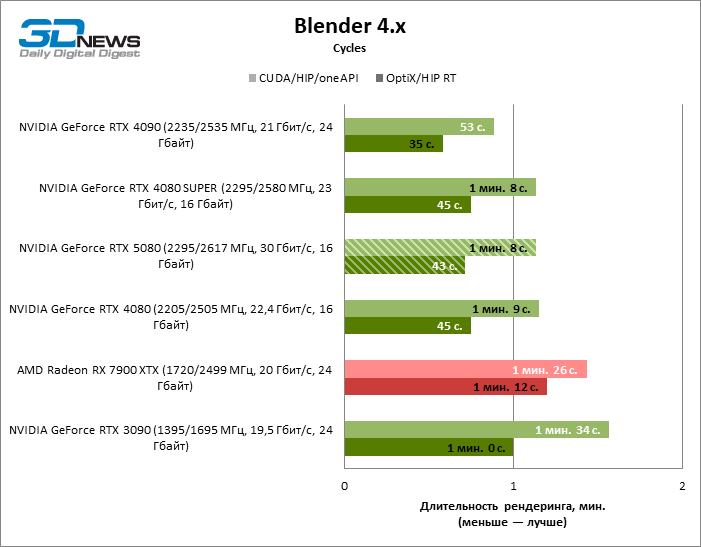
Blender rendering is a measure of raw GPU productivity in materially dramatic calculations, and in this regard, the GeForce RTX 5080 took only a formal step forward from RTX 4080 Super. As a result, the novelty has a tiny advantage over the old 80 models when using hardware reiterating, but by and large there is practically no significant difference between three accelerators. Well, the GeForce RTX 4090 remains an unconditional leader in the tasks of this kind.
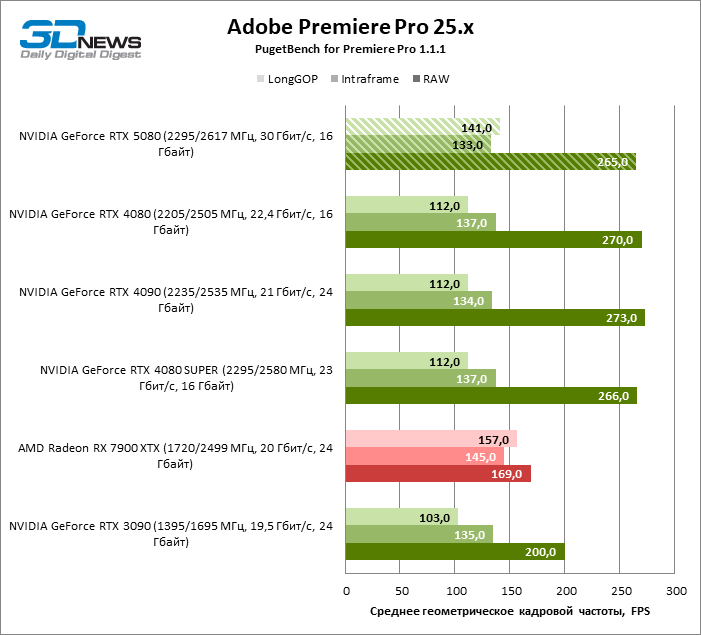
But the Benchmark Coding/Decoding in Premiere Pro put the GeForce RTX 5080 in the first place among test participants due to the high speed of working with H.264 and HEVC formats. However, it should be noted that it would get the Radeon RX 7900 XTX, if not for the low result in RAW tests.
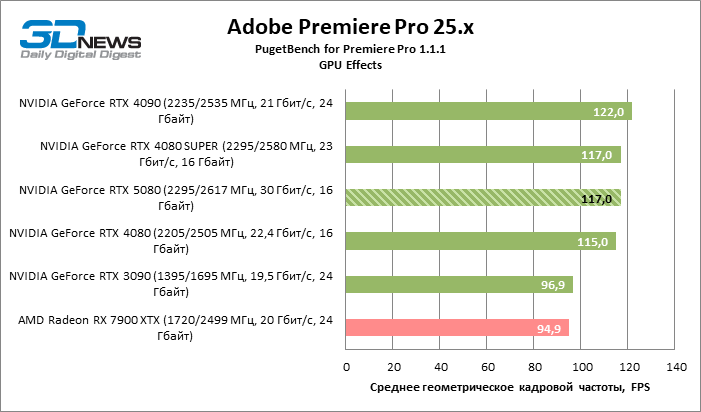
Senior NVIDIA models form a dense group on the performance graph of GPU effects in Premiere Pro, and the GeForce RTX 5080 reached the same results as RTX 4080 Super.
The test using various video formats in Davinci Resolve brought another GEFORCE RTX 5080 victory with a small margin from the previous champion – Radeon RX 7900 XTX.
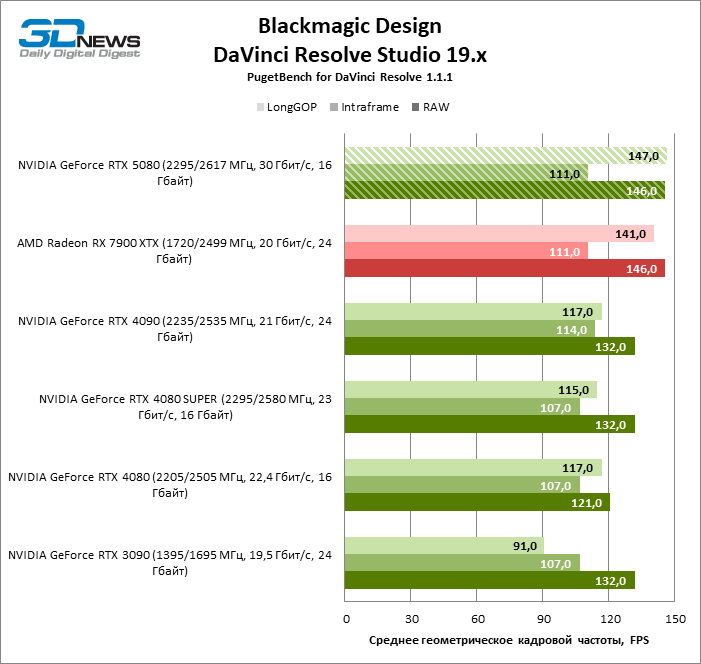
The novelty also went around the Radeon RX 7900 XTX rendering rate in the Davinci Resolve Render effects and only the GeForce RTX 4090 is inferior, but the “red” flagship did not give up the Fusion Benchmark.
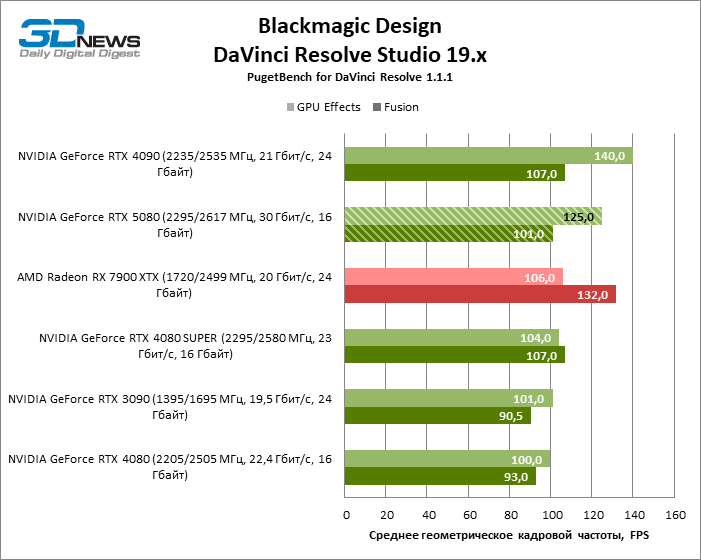
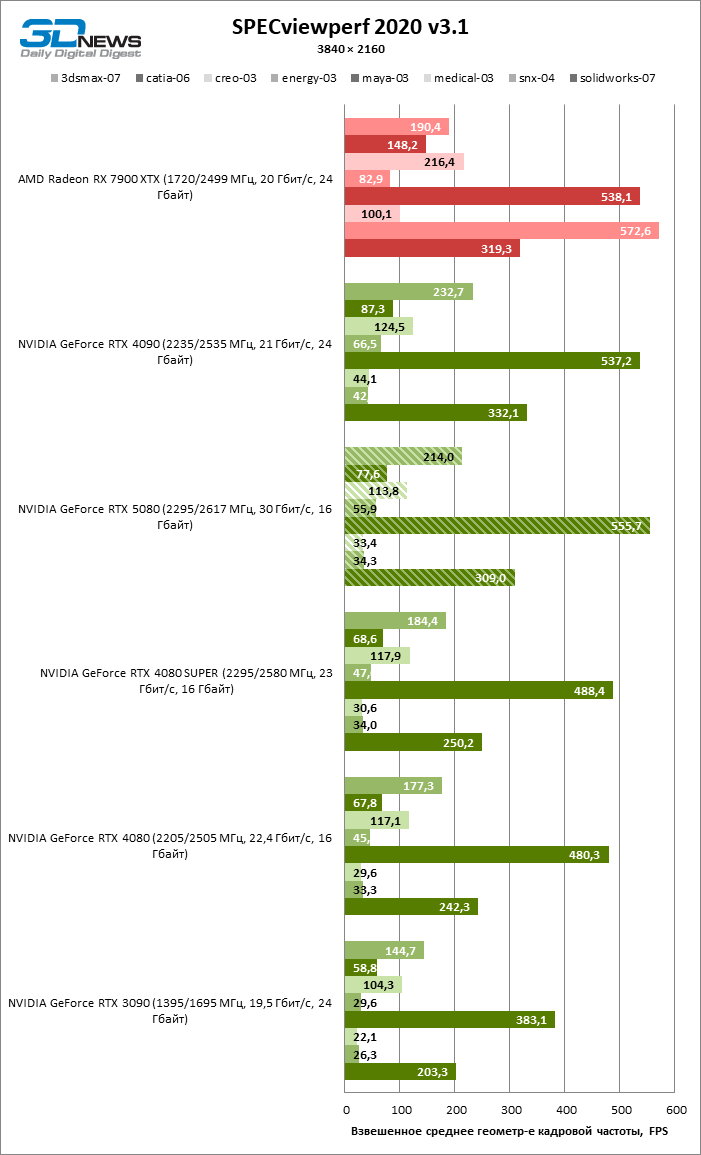
Finally, the GeForce RTX 5080 demonstrated the same performance profile in CAD applications as video cards of the 40th series. According to the average assessment, the RTX 5080 takes a position between the RTX 4080 Super and RTX 4090, but all the “green” accelerators are not compared with the Radeon RX 7900 XTX.
⇡#Video encoding / decoding
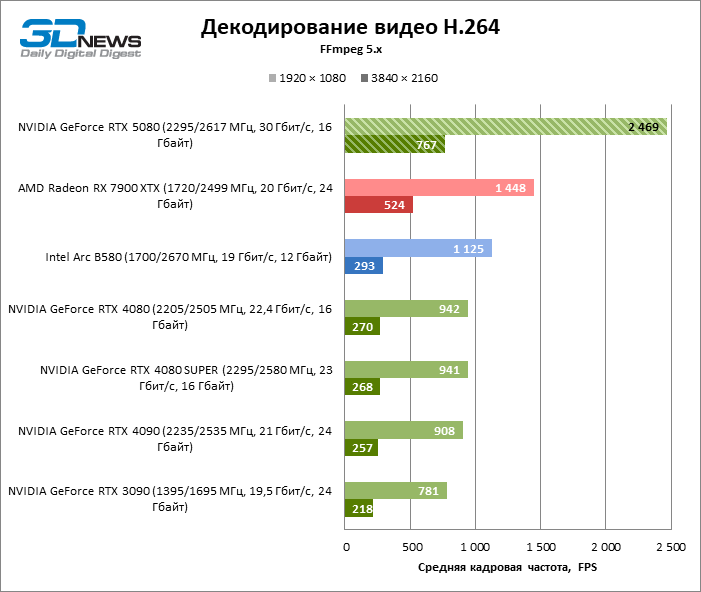
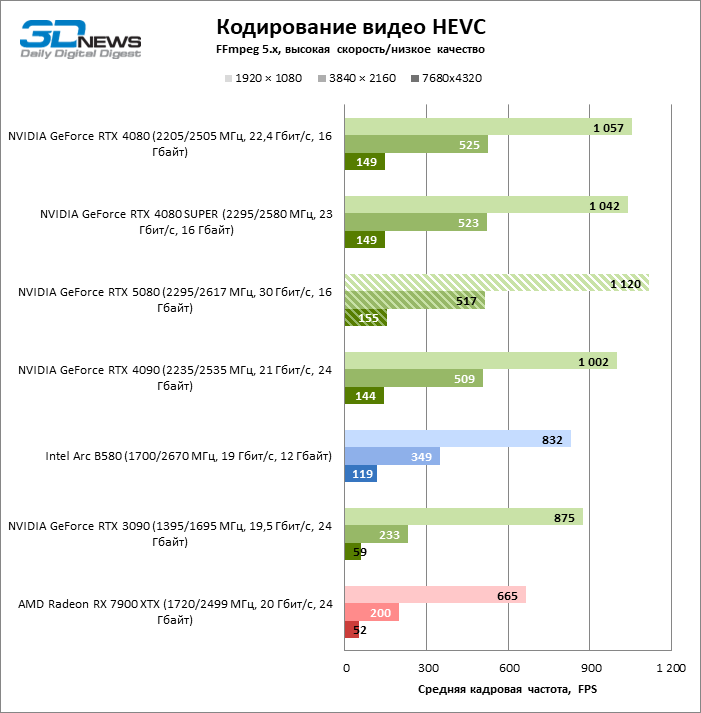
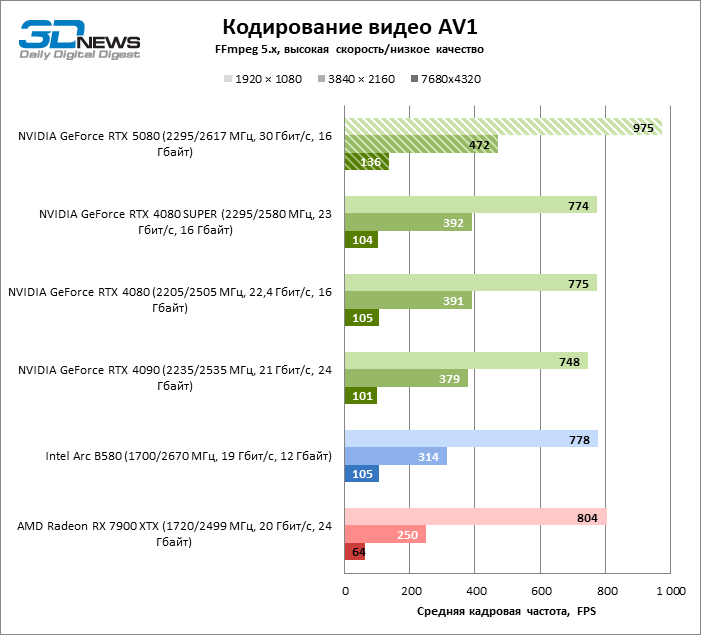
The NVDEC hardware decoder, which had not complained about the performance before, received a small increase in the speed of working with HEVC, VP9 and AV1. And most importantly, H.264 personnel frequency has more than doubled. Now NVIDIA leads in all decoding tests with the exception of AV1 with a resolution of 1080p and VP9, where the first place is occupied by Intelly QuickSync on the ARC B580 board.
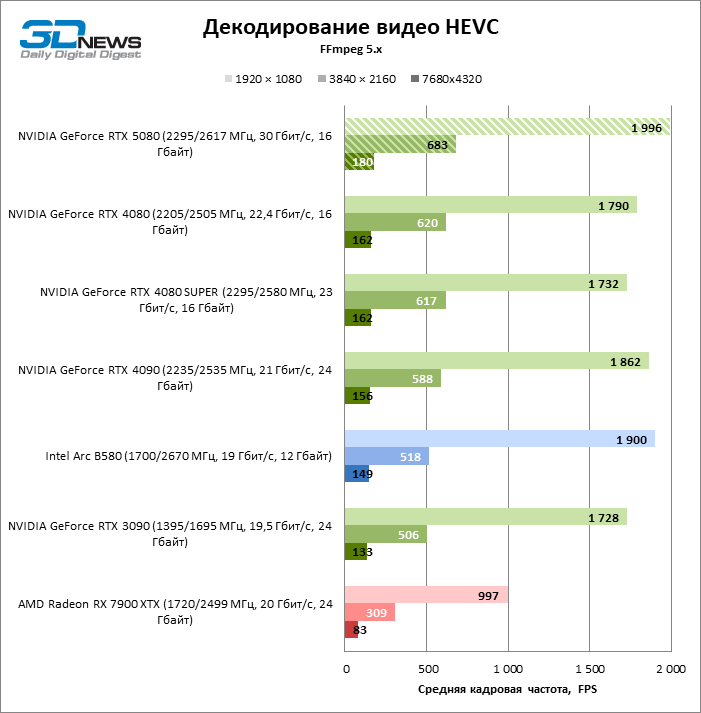
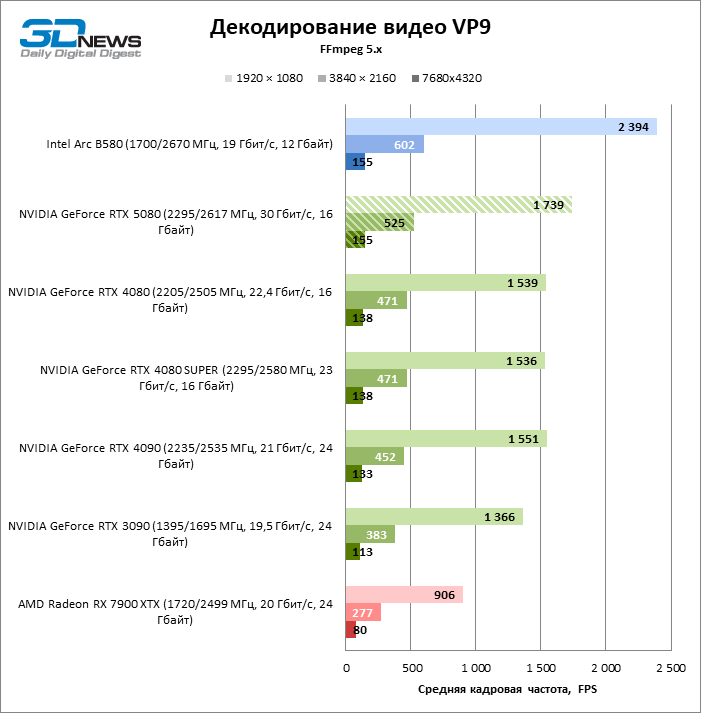
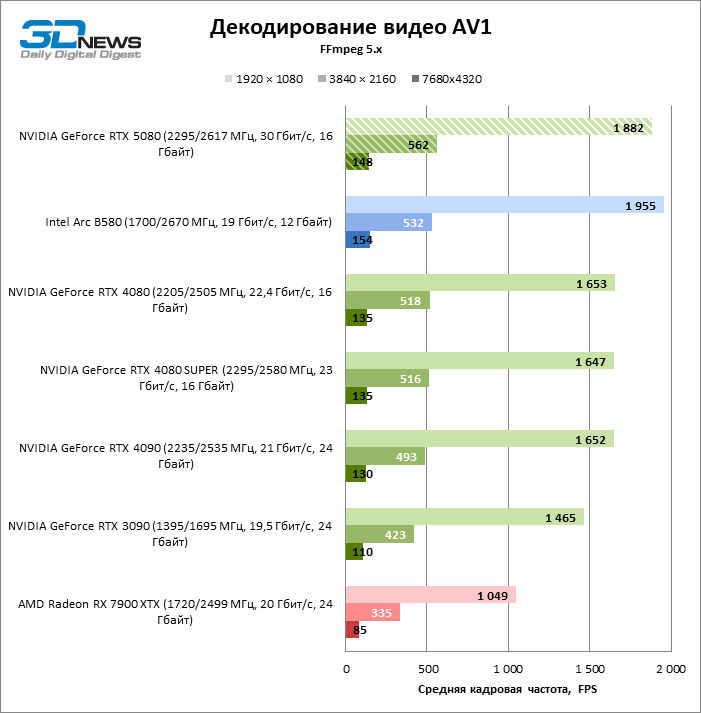
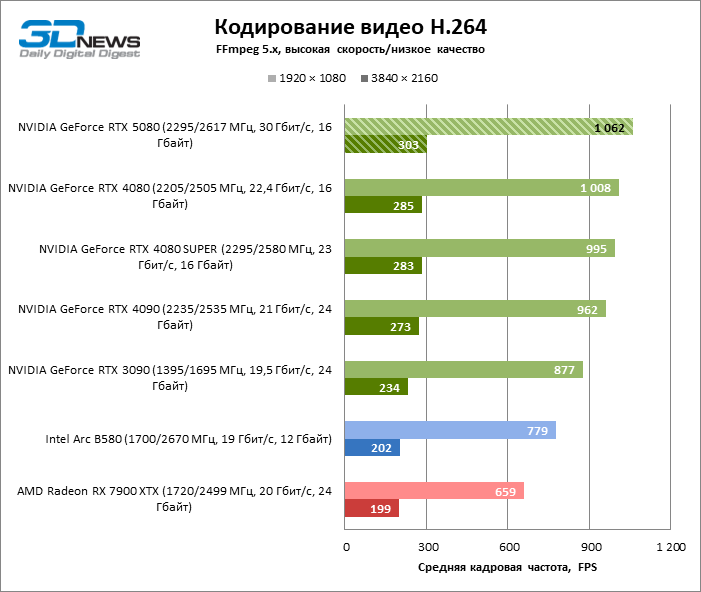
As for hardware coding, the GeForce RTX 5080 was not able to demonstrate a significant advantage over senior models of the 40th series in the H.264 and HEVC benchmarks, but the export rate in AV1 increased markedly (especially with 8K resolution). In this group of tasks, RTX 5080 unconditionally ahead of the solution of Intel and AMD.
⇡#Performance per watt
Despite all the improvements of the Blackwell chips, designed to increase energy efficiency in the conditions of the previous photolithographic norm, the comparison of the GeForce RTX 5080 with the RTX 4080 Super in the average personnel frequency (both in rastied and trace -trace -based games) on the power of the power budget did not end in favor of the novelty. And at the basic version of the RTX 4080, it wins only 1-2 %. It is also curious that the Radeon RX 7900 XTX turned out to be the complete equivalent of the GeForce RTX 5080 in specific speed in rastrovization, although it is predictably inferior to it 39 % FPS in games with hybrid rendering or tracing of tracks.
⇡#Summary results of gaming tests without ray tracing
⇡#Summary results of gaming tests with ray tracing
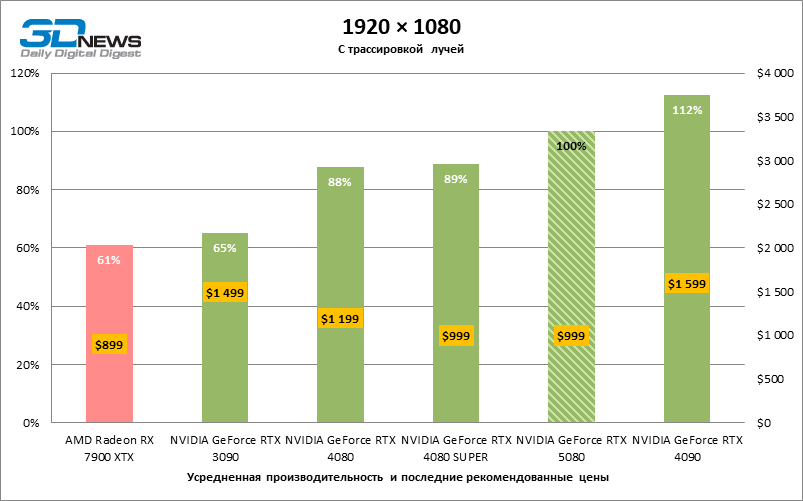
⇡#Summary results of gaming tests with ray tracing and frame scaling
⇡#Conclusions
The emergence of the GPU of the new architecture is always a large and exciting event, especially now, when chipmakers are still mastering the trace of rays and neural networks in game rendering. However, the pure performance of video cards can no longer increase in the same pace. NVIDIA engineers have done a lot to extract 5 Nm from photolithography, and the functional innovations of the Blackwell logic – first of all, the new version of DLSS and neural shaders – became another step away from the rendering paradigm of rude force. Moreover, the generation of multiple personnel with the help of DLSS 4 can be used now even in those games that do not offer this function of native.
The problem is that MFG really provides multiple “free” growth in personnel frequency, but at best it does not help reduce the delay in the input compared to the basic framework. Therefore, the GPU pure performance is still important, namely its GeForce RTX 5080 is not enough to work out the recommended cost of $ 999. Removing multiple personnel from the Blackwell chip, and we will receive the second edition of the RTX 4080 Super. In the most favorable conditions (games on 4K screen with reitreasing), RTX 5080 managed to move the speed bar to only 16 %. This was not enough even to reach the level of the previous flagship-the GeForce RTX 4090-which is an unprecedented failure for the 80s of NVIDIA models. Another in the face was a close rivalry with the Radeon RX 7900 XTX in rasterized benchmarks. However, why buy such expensive video cards, if not for games with RT?
In defense of the novelty, it can be argued that it has a deliberately better ratio of capabilities and prices compared to the GeForce RTX 4090, which has long come off from its MSRP. However, the graphics cards of the 50th series will probably befall the same shortage. GeForce RTX 5080 is an ideal example of what is happening in the absence of competition, which has left the discrete GPU market and will definitely not return in the current cycle.
But the Palit Gamerock accelerator, which represents the GeForce RTX 5080 in the review, did not give the slightest reason for criticism. Despite the power consumption up to 400 watts, the device works quietly and surprisingly productively accelerates (which is a considerable extent the merit of silicon Blackwell) – if only in the case there was enough space for such a huge video card.