Developers from Microsoft Research have presented a multimodal language AI model called Magma, which can process visual and text data to control software interfaces and robotic systems. If the algorithm is tested beyond Microsoft, it could be an important step toward creating a universal multimodal AI that can work in both digital and real space.

A demo of Magma controlling a robotic arm / Image source: Microsoft Research
Microsoft claims that Magma is the first AI model that can not only process multimodal data (e.g. text, images, video) but also perform actions based on it, whether it’s navigating a user interface or manipulating physical objects. The Magma algorithm was developed jointly by developers from Microsoft, KAIST, the University of Maryland, the University of Wisconsin-Madison, and the University of Washington.
There have been previous robotics projects based on large language models (LLM). These include Google’s PALM-E and RT-2 projects or Microsoft’s ChatGPT for Robotics, where AI systems were used to manage software interfaces.

A combination diagram demonstrating Magma’s capabilities / Image source: Microsoft Research
Unlike many existing multimodal algorithms, which require separate models for perception and control, Magma combines these capabilities into a single core AI model. Microsoft positions Magma as a significant step toward creating a unified AI agent—a system that can autonomously develop action plans and execute multi-step tasks on behalf of a human, rather than simply answering questions about what it sees.
«Given the described goal, Magma is able to formulate plans and execute actions to achieve them. By effectively transferring knowledge extracted from freely available visual and language data, Magma combines verbal, spatial, and temporal algorithms to navigate complex tasks and environments,” the Microsoft researchers said in a statement.

Image source: Microsoft Research
Magma’s AI model includes two technical components: Set-of-Mark (identifies manipulable objects in an environment by assigning digital labels to interactive elements such as pressable buttons in a user interface or graspable objects in a robot’s workspace) and Trace-of-Mark (allows the algorithm to perform tasks such as navigating user interfaces or controlling robotic arms to grasp and move objects).
One of the project participants said that the name of the algorithm Magma stands for M(ultimodal) Ag(entic) M(odel) at Microsoft (Rese)A(rch). In the description of the algorithm, Microsoft claims that Magma-8B demonstrates competitive results in benchmarks, showing high results in tasks of navigating the user interface and manipulating robots.
Thus, in the VQAv2 benchmark, the Magma algorithm received 80.0 points for visual question answers, which is higher than the result of GPT-4V (77.2 points), but lower than the LLaVA-Next (81.8 points). The POPE algorithm’s score of 87.4 points is currently the absolute best among the AI models that participated in the comparison. It is noted that in the field of robot manipulation, Magma outperforms OpenVLA.
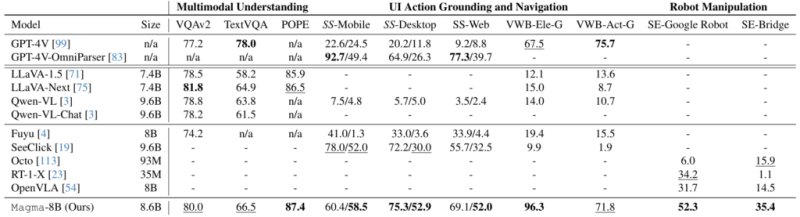
Image source: Microsoft Research
According to its developers, Magma differs from similar machines like GPT-4V in that it goes beyond so-called “verbal intelligence” to include “spatial intelligence,” i.e. the ability to plan and execute actions. By learning from a mix of images, videos, robotic data, and user interface interactions, Magma is essentially a full-fledged multimodal AI agent, rather than just a perceptual model.
Like all AI models, Magma isn’t perfect. Microsoft’s documentation indicates that the algorithm still faces technical limitations when making complex step-by-step decisions that require multiple actions to be performed over time. Microsoft is continuing to work on improving the algorithm. The software giant plans to make Magma’s source code and other documentation available on GitHub so that third-party researchers can use it to implement their own projects.