AMD boasts that the Ryzen AI Max+ 395 is up to 12x faster at AI than its direct competitor from Intel


AMD’s latest flagship mobile processor, the Ryzen AI Max+ 395 Strix Halo family, delivers up to 12x better performance on a variety of large AI language models than Intel’s Lunar Lake chips, AMD announced in its official blog, sharing the relevant charts.

Image source: AMD
With 16 Zen 5 compute cores, 40 RDNA 3.5 graphics units, and an XDNA 2 NPU with 50 TOPS (trillion operations per second), the Ryzen AI Max+ 395 delivers up to 12.2x faster performance in certain LLM scenarios than the Intel Core Ultra 258V. It’s worth remembering that Intel’s Lunar Lake chip only has four P-cores and four E-cores, which is half as many as the Ryzen AI Max+ 395 in total. However, the performance difference between the platforms is much more than double.
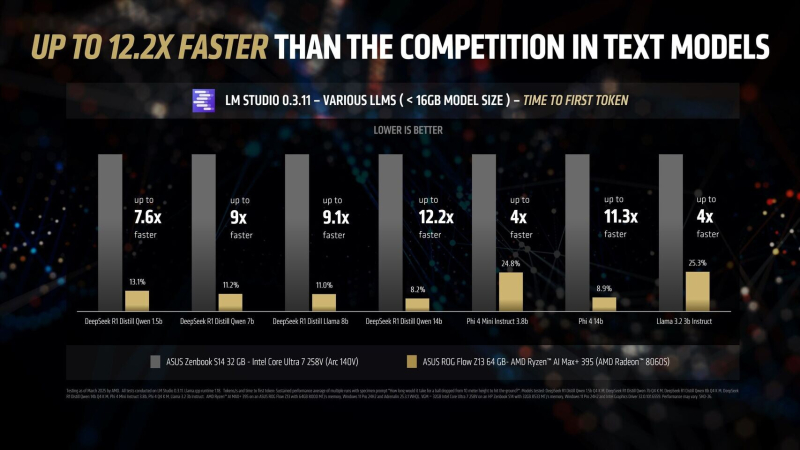
The advantage of the Ryzen AI Max+ 395 chip becomes even more noticeable as the complexity of the language models increases. The biggest difference in performance between the platforms is visible when working with LLM with 14 billion parameters, which requires more RAM. Recall that Lunar Lake is a hybrid processor equipped with up to 32 GB of on-board RAM.
In LM Studio tests using an Asus ROG Flow Z13 with 64GB of unified memory, the Ryzen AI Max+ 395’s integrated Radeon 8060S graphics delivered 2.2x the token throughput of Intel’s Arc 140V graphics across a variety of AI models. In Time-to-First-Token tests (a language model performance metric that measures how long it takes from sending a request to generating the first token in a response), the AMD chip delivered a 4x lead over its competitor in models like Llama 3.2 3B Instruct, and increased the lead to 9.1x in models that support 7–8 billion parameters, such as the DeepSeek R1 Distill.
The AMD processor particularly excelled in multimodal vision tasks, processing complex visual inputs up to 7x faster on IBM Granite Vision 3.2 3B and 6x faster on Google Gemma 3 12B compared to the Intel chip. AMD’s support for Variable Graphics Memory technology allows up to 96GB of memory to be allocated as VRAM from systems with up to 128GB of unified memory, enabling the deployment of advanced language models such as Google Gemma 3 27B Vision.
The AMD processor’s performance advantages over its competitor are also visible in practical AI applications, such as medical image analysis and coding assistance with high-precision 6-bit quantization in the DeepSeek R1 Distill Qwen 32B.

Recent Posts
“What do you see: craters or bulges?” – Japanese probe Resilience photographs the south pole of the Moon
The Japanese private probe Resilience has taken a high-quality photo of the Moon's south pole…
A database containing data from 184 million accounts of Apple, Google, Microsoft and other services was just lying on the Internet
Cybersecurity researcher Jeremiah Fowler discovered a publicly available database with more than 184 million logins…
Doom: The Dark Ages Is Rightfully the King. Review
Played on PC In 2016, the Doom series returned to our screens, and did so…
Apple’s 25% tariffs will affect Samsung smartphones, Trump explains
US President Donald Trump this week said he would impose a 25% tariff on iPhones…
Thermaltake Shows Off IX700 PC Case with Immersion Cooling
Thermaltake unveiled a prototype of the IX700 system unit with an immersion cooling system at…
Warhammer 40,000: Boltgun 2 Will Be Released in 2026, and You Won’t Have to Wait for a Free Printed Shooter Based on the First Part
At the Warhammer Skulls 2025 presentation, developers from the British studio Auroch Digital announced a…