Pure Storage has announced FlashBlade//EXA, claimed to be the highest performing storage platform available today, designed specifically for the most demanding AI and HPC workloads.
It is noted that standard storage systems are optimized for traditional HPC environments with predictable operations. Such systems are designed with an eye on scaling “pure performance”. However, modern AI workloads are much more complex and multimodal: they involve processing different types of data – text, images and video – simultaneously on tens of thousands of accelerators. Because of this, there is a need to optimize metadata processing along with scaling performance.
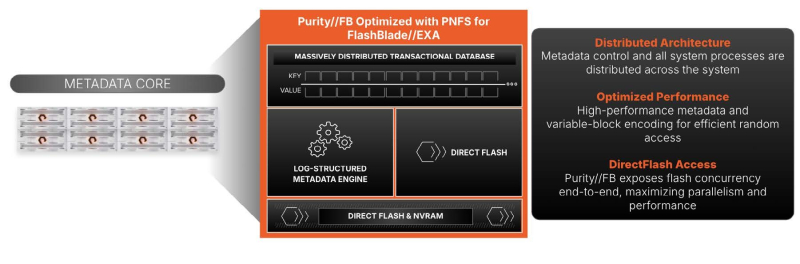
FlashBlade//EXA, according to Pure Storage, eliminates the bottlenecks of traditional storage systems in terms of working with metadata. The new platform’s architecture makes it possible to scale resources for processing regular data and metadata independently of each other. Efficient metadata processing is critical to maintaining high performance, reliability, and efficiency in large-scale AI environments.

Image source: Pure Storage
The Metadata Core metadata segment in FlashBlade//EXA can combine from 1 to 10 5U chassis with ten blade nodes each. Each node contains from one to four proprietary 37.5 TB DFM modules. Another 2U is allocated to a pair of XFM (External Fabric Modules), which provide 16 400 GbE connections. Metadata Core runs the proprietary Purity//FB OS, communicates directly with the GPU cluster (NFSv4.1 over TCP) and manages data flows between the storage nodes and the cluster (NFSv3 over RDMA).
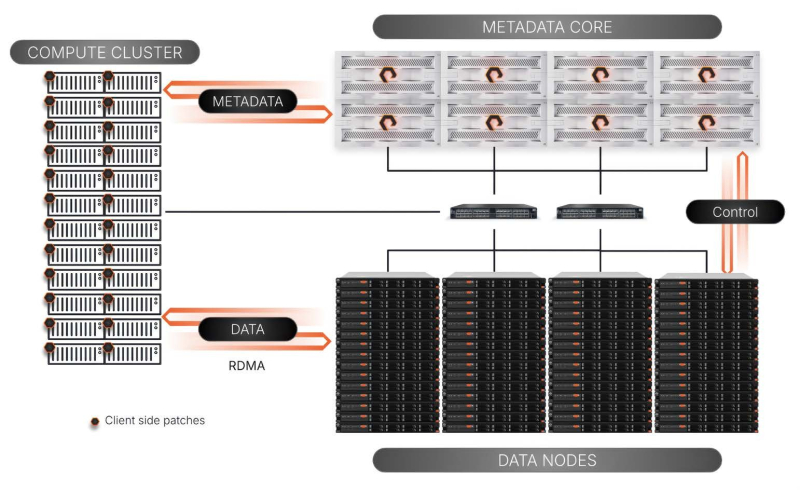
Data Node storage nodes have unlimited scalability. Moreover, these nodes can be the most common x86 servers from any vendor. Each such node must contain a 32-core CPU, 192 GB of RAM, 12 to 16 NVMe SSD (PCIe 4.0/5.0) with a capacity of up to 61.44 TB, and a pair of 400GbE NICs. The platform architecture provides for the use of NVIDIA ConnectX network adapters, Spectrum switches, LinkX components, etc.
FlashBlade//EXA delivers over 10 TB/s of read performance in a single namespace. As a result, organizations can significantly speed up the training of AI models and inference, maximizing the potential of GPU accelerators. This also helps reduce the time and cost of solving resource-intensive tasks. Apparently, this is the solution the company offers to hyperscalers. Pure Storage itself has a test configuration of 300 nodes, which shows performance at the level of 30 TB/s.