OpenAI has introduced a new language model, o1, that has the ability to reason and solve problems logically. Unlike previous models, o1 is able to imitate the human thought process, breaking down complex problems into simpler steps, analyzing different approaches and correcting its own mistakes.
Image source: OpenAI
The o1 Large Language Model (LLM) has demonstrated outstanding performance in tests and competitions, comparable to human experts. In programming, o1 was ranked 49th at the 2024 International Olympiad in Informatics (IOI) and beat 89% of people on the Codeforces platform. In mathematics, o1 was ranked among the top 500 students in the United States at the American Mathematical Olympiad (AIME) qualifying stage, demonstrating the ability to solve problems designed for the most gifted students, OpenAI reports on its website.
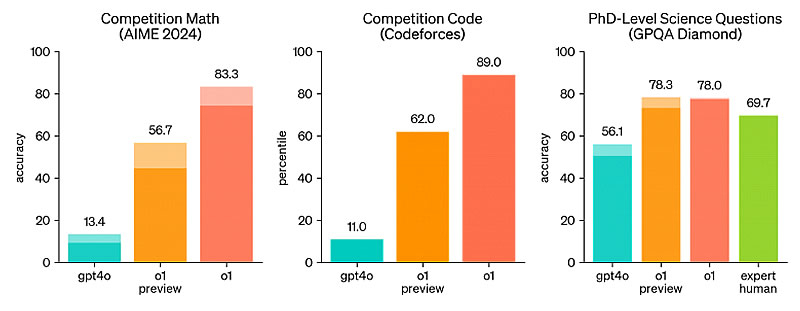
Image source: OpenAI
In the natural sciences, the model outperformed doctors and candidates of science in the complex GPQA diamond test, which assesses knowledge in the fields of chemistry, physics and biology. “This does not mean that o1 is smarter than any candidate of science,” the developers explain. “This suggests that the model is capable of solving some problems at the level of highly qualified specialists.”
The o1 model has also demonstrated superiority over previous models in various intelligence and problem-solving tests, including the MMMU and MMLU. According to OpenAI, the new model significantly outperforms its predecessor, GPT-4o, on most reasoning tasks. “Our testing has shown that o1 consistently improves results with increasing amounts of intervention learning and time spent on reflection,” the company notes. In particular, in the AIME tests, the o1 model solved an average of 83% of problems, while the GPT-4o result was 13%.
Model o1 hallucinates significantly less than GPT-4o. However, it is slower and more expensive. In addition, o1 loses to GPT-4o in encyclopedic knowledge and cannot process web pages, files and images. In addition, the new model can manipulate data, adjusting the solution to the result.
The secret of success lies in a fundamentally new learning algorithm – the “chain of thoughts”. The model can improve this chain by learning using the reinforcement learning method, thanks to which it recognizes and corrects its mistakes, breaks complex steps into simpler ones, and tries different approaches to solving problems. This methodology greatly improves the model’s reasoning ability, which “like a human can think for a long time before answering a complex question.”
OpenAI has already released a preliminary version of the o1-preview model, available for use in ChatGPT and for developers via the API. The company admits there is still a lot of work to be done to make the o1 as easy to use as current models. The safety and ethicality of the new model is also emphasized, as its reasoning can be controlled, preventing potentially undesirable behavior. And before releasing o1-preview for public use, OpenAI conducted security tests.
The cost of using o1-preview is $15 for 1 million input tokens and $60 for 1 million output tokens. In comparison, GPT-4o offers a price of $5 per 1 million input tokens and $15 per million output tokens.