As the AI industry recovers from the shock of China’s DeepSeek’s unexpected triumph, experts have concluded that the industry may need to rethink how it trains models. DeepMind researchers have announced an upgrade to distributed training, The Register reports.
DeepSeek, which recently unveiled cutting-edge AI models, has caused some panic in the US, claiming that it can train models at a much lower cost than, say, OpenAI (which is disputed), and using a relatively small number of NVIDIA accelerators. While the company’s claims are disputed by many experts, it has forced the industry to consider how effective it is to spend tens of billions of dollars on increasingly large-scale models when comparable results can be achieved at a fraction of the cost, using fewer power-hungry data centers.
Google subsidiary DeepMind has published the results of a study that describes a method for distributing training of AI models with billions of parameters using clusters that are far from each other while maintaining the required level of training quality. In the paper “Streaming DiLoCo with overlapping communication,” the researchers expand on the ideas of DiLoCo (Distributed Low-Communication Training). This will allow models to be trained on “islands” of relatively poorly connected devices.

Image source: Igor Omilaev/unsplash.com
Today, training large language models may require tens of thousands of accelerators and efficient interconnect with high bandwidth and low latency. At the same time, network costs grow rapidly with the number of accelerators. Therefore, instead of one large cluster, hyperscalers create “islands” with significantly higher network communication speed and connectivity within them than between them.
DeepMind suggests using distributed clusters with relatively rare synchronization – much less bandwidth will be required, but without compromising the quality of training. Streaming DiLoCo technology is an improved version of the method with scheduled synchronization of parameter subsets and reduction of the volume of data to be exchanged without loss of performance. The new approach, according to the researchers, requires 400 times less network bandwidth.
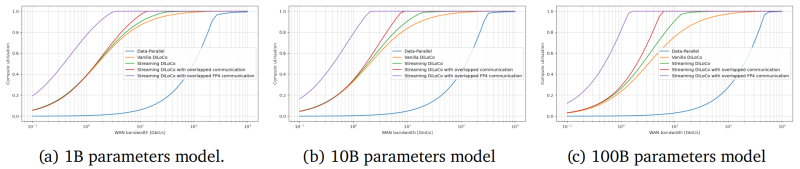
Image Source: Deepmind
The importance and potential of DiLoCo are noted, for example, by Anthropic. The company reports that Streaming DiLoCo is much more efficient than the regular version of DiLoCo, and the benefits grow as the model scales. As a result, it is assumed that model training will eventually be able to be continuously carried out using thousands of systems distributed quite far from each other, which will significantly lower the entry threshold for small AI companies that do not have the resources for large data centers.
Gartner claims that the methods already used by DeepSeek and DeepMind are already becoming the norm. Ultimately, data center resources will be used more and more efficiently. However, DeepMind itself considers Streaming DiLoCo only as the first step towards improving the technology; additional development and testing are required. It is reported that the possibility of combining many data centers into a single virtual megacluster is currently being considered by NVIDIA, some of whose HPC systems already operate according to a similar scheme.