Fujitsu announced the availability of middleware designed to optimize the use of AI accelerators. As stated in the press release, this solution makes it possible to increase the efficiency of accelerators, which is especially important in the context of a shortage of computing resources of this type.
The software distinguishes between code that requires a GPU to run and that which can run on the CPU alone, optimizing resource allocation and memory management across different platforms and AI applications. In addition, the software controls the priority of running calculations, giving preference to more efficient processes. Interestingly, allocation does not use the traditional approach of basing resource selection on the entire task.
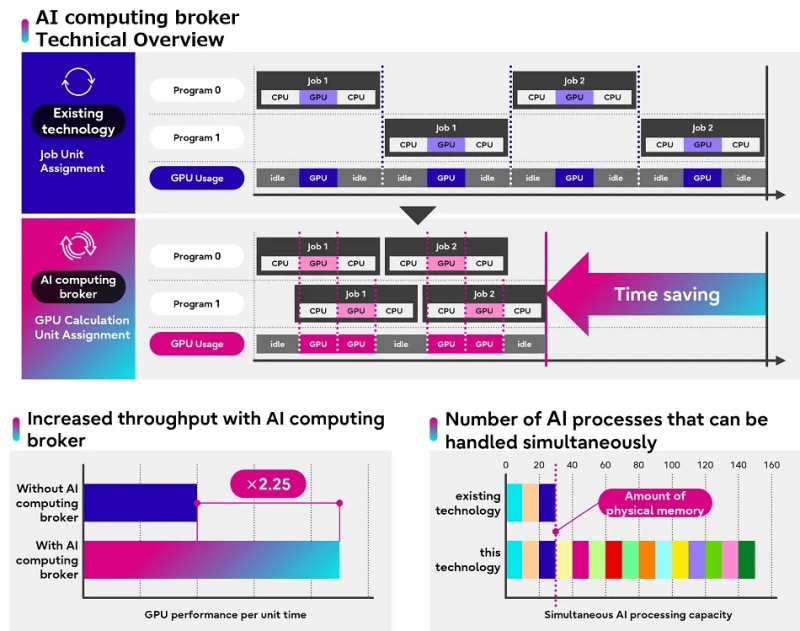
Image source: Fujitsu
The company announced the solution (Adaptive GPU Allocator) in November 2023. Then they talked about the need to use a proprietary framework based on TensorFlow and PyTorch. The current announcement does not explicitly mention this, but it is reported that the product combines the technology of adaptive resource allocation of each individual accelerator with some kind of AI-based optimization. Moreover, the new product allows you to efficiently process even those tasks that do not fit entirely in the accelerator’s memory. During testing, we were even able to process 150 GB of AI data on a GPU with approximately 30 GB of free RAM.
Fujitsu said the solution increased AI computing efficiency by 2.25 times in real-world testing at AWL, Xtreme-D and Morgenrot. And two large customers, Tradom and Sakura Internet, have already begun to implement the new tool. “By addressing the accelerator and energy shortages caused by the growing global demand for AI, Fujitsu aims to contribute to enhancing business productivity and creativity for its customers,” the company said.
However, so far the solution can only speed up the operation of accelerators in one server, but the company is working to ensure that it can serve multiple GPUs installed in several servers. In other words, it will not yet allow you to speed up an entire AI cluster, but it is still a convenient way to “squeeze more” out of a GPU server, noted The Register resource.