NVIDIA released the new GB300 and B300 accelerators just six months after the release of the GB200 and B200. And this is not a minor update, as it might seem at first glance – the appearance of (G)B300 will lead to a serious transformation of the industry, especially given the significant improvements in inference of “reflective” models and training, writes SemiAnalysis. At the same time, with the transition to B300, the entire supply chain changes, and someone will benefit from this and someone will lose.
Design of the B300 (formerly known as Blackwell Ultra) compute chip, manufactured using TSMC’s custom 4NP process. Thanks to this, it provides 50% more FLOPS compared to the B200 at the overall product level. Part of the performance gain will come from increased TDP, reaching 1.4 kW and 1.2 kW for the GB300 and B300 HGX respectively (compared to 1.2 kW and 1 kW for the GB200 and B200). The rest of the performance improvements come from architectural improvements and system-level optimizations, such as dynamic power distribution between the CPU and GPU.

Image source: NVIDIA
In addition, the B300 uses HBM3E 12-Hi memory, not 8-Hi, the capacity of which has increased to 288 GB. However, the speed per contact remains the same, so the total memory bandwidth (BMB) is still 8 TB/s. LPCAMM modules will be used as system memory. The difference in performance and economy due to increased HBM volume is much greater than it appears. Memory improvements are critical for OpenAI O3-style large language model (LLM) training and inference, as longer token sequences negatively impact processing speed and latency.
The example of updating H100 to H200 clearly shows how memory affects the performance of the accelerator. Higher bandwidth (H200 – 4.8 TB/s, H100 – 3.35 TB/s) overall improved interactivity in inference by 43%. And the larger memory capacity reduced the amount of data moved and increased the allowable size of KVCache, which tripled the number of tokens generated per second. This has a positive impact on the user experience, which is especially important for increasingly complex and smart models that can generate more revenue per accelerator. The gross margin for leading models is over 70%, while for lagging models in a competitive open source environment it is less than 20%.
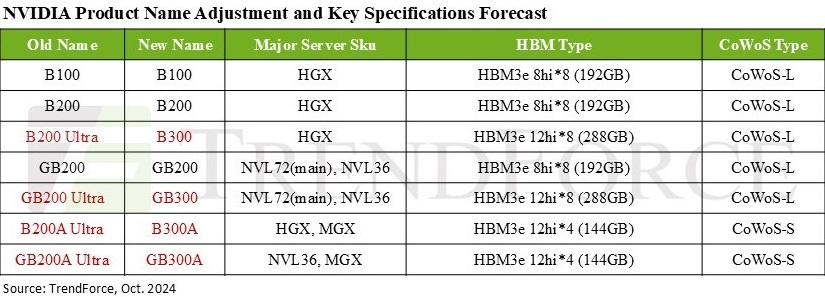
Image source: TrendForce
However, one increase in speed and memory, as AMD does in the Instinct MI300X (192 GB), MI325X and MI355X (256 GB and 288 GB, respectively). And the point is not that the company’s buggy software does not allow the potential of accelerators to be revealed, and especially the communication of accelerators with each other. Only NVIDIA can offer all-to-all dial-up connectivity through NVLink. In the GB200 NVL72, all 72 accelerators can work together on the same task, increasing interactivity by reducing the latency of each chain of thought while increasing their maximum length. In practice, NVL72 is the only way to increase the inference length to more than 100 thousand tokens and is also cost-effective, says SemiAnalysis.