On the final day of Shipmas, which promised to show, announce, and talk about new AI features for 12 days, OpenAI unveiled a pair of large next-generation language models, o3 and o3-mini, that have the ability to reason.

Image source: OpenAI
OpenAI notes that we are not talking about releasing new language models today. The company explained that the training of these neural networks has not yet been completed and the final result of their training may differ from what it says today. At the same time, OpenAI is accepting submissions from the research community to test these models before releasing them to the public. The company has not yet decided when this will happen.
In September of this year, OpenAI launched the thinking AI model o1 (codenamed Strawberry). The decision to call the new models o3 is due to the fact that in this way the company decided to avoid confusion (or trademark conflicts) with the British telecommunications company O2.
The term “reasoning AI model” has recently become very fashionable in the development of artificial intelligence and machine learning technologies. However, in essence, it only means that in order to solve a given question, the machine breaks down given instructions into smaller tasks. This ultimately allows you to achieve more accurate results from it. “Reasoning” AI models often show the entire decision process and how the AI arrived at a particular answer, rather than simply giving a final answer without explanation.
OpenAI claims its new o3 model exceeds previous performance records across the board. In the ARC-AGI test, which was specifically designed to compare the capabilities of artificial intelligence with human intelligence, the o3 model outperformed the o1 by more than three times, demonstrating a result of 88%.
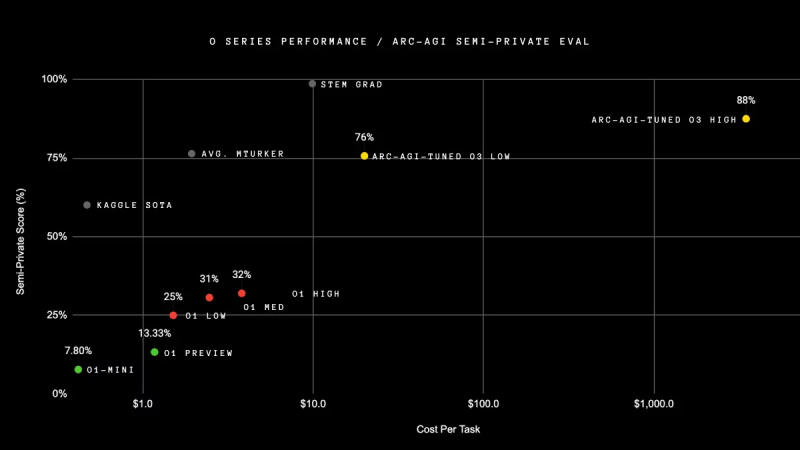
The new model is also 22.8% faster than its predecessor in writing code (SWE-Bench Verified test) and even outperformed OpenAI’s leading scientist in sports programming.
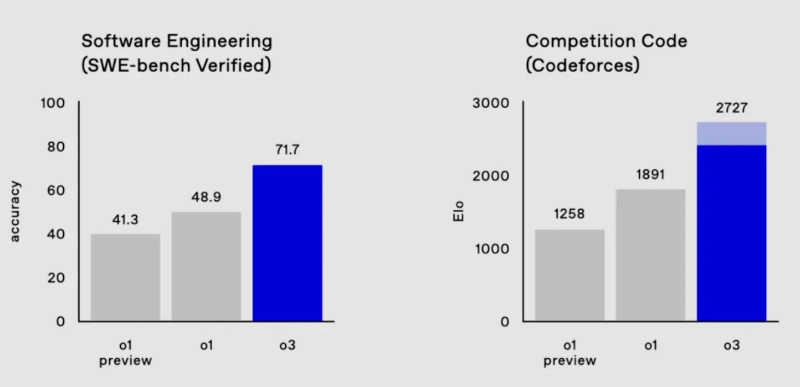
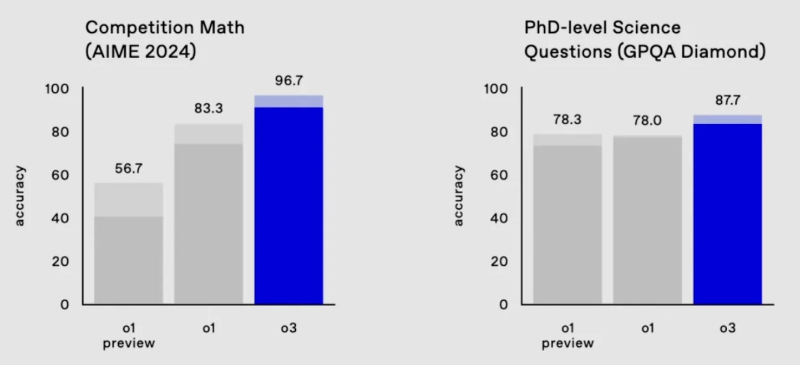
The o3 model almost aced one of the most difficult math tests, AIME 2024, missing only one question, and also scored 87.7% in the GPQA Diamond benchmark – significantly higher than any result of a human expert.
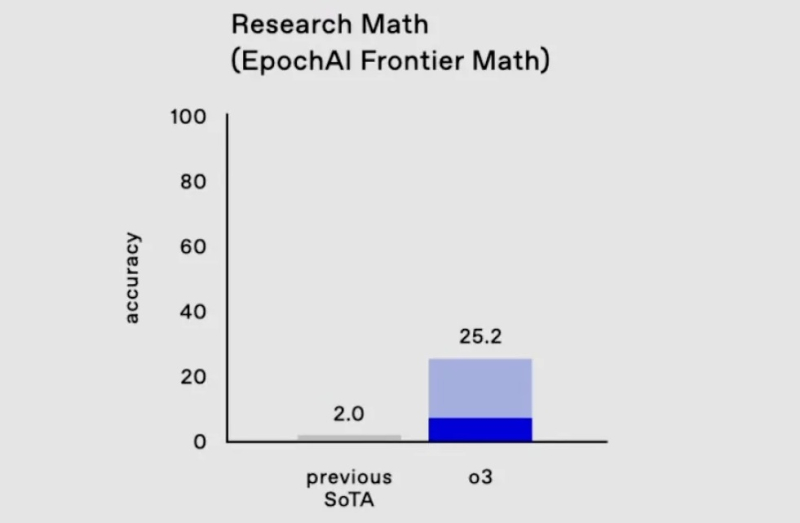
In the most difficult math and logic tests, which usually stump any other AI, o3 solved 25.2 percent of problems – the results of other models do not exceed two percent.
A significant advantage of o3, like o1, is the ability of models to “reason” and effectively check their own facts in order to avoid various kinds of errors and hallucinations. However, developers from OpenAI stated that the fact-checking process before issuing an answer leads to a slight delay – from several seconds to several minutes (depending on the complexity of the question). Additionally, the delay is due to the model determining whether the user’s request complies with OpenAI’s security policy. The company claims that when testing the new security algorithm on the o1, it followed security rules much better than previous models, including GPT-4.
And yet, as TechCrunch journalists note, the main disadvantage of “reasoning” models is that they require much more computing power to operate, so in the end their use is much more expensive than “conventional” solutions.