The main difficulty with FLUX.1 [dev] from the point of view of the owner of a budget PC is the inability to fit the corresponding UNet model into the video memory (although in this case, strictly speaking, it is not a UNet, like SD 1.5 and SDXL, but a DiT – diffusion transformer , but the terminology has already been established) in its entirety, unless you resort to completely unmerciful compression/quantization of its weights, which we mentioned in the previous “Workshop”. It would seem that this is the solution: instead of the basic UNet/DiT encoded FP16 or even GGUF Q8_0, we use a much more compact version, use it to find a suitable composition, turning a blind eye to the inevitable flaws in detail, and then we will re-execute the cyclogram with the same hints and a seed, but with a model that is not so tightly compressed. Will it work?
ComfyUI workspace with a basic cyclogram, which we will mainly interact with this time
⇡#Can you draw?
Let us remind you, just in case, that we are reviewing models of the FLUX.1 family for the third time in a row, and all information on them, as well as our standard (at the moment) ComfyUI working environment for deployment on a local PC, has already been provided in previous articles, as well as information on quantization of AI model weights using the GGUF method. For the sake of experiment, let’s download three more models from the GGUF-quantized UNet/DiT repository for FLUX.1, namely:
- Flux1-dev-Q2_K.gguf – approximately 4 GB,
- Flux1-dev-Q4_K_S.gguf – 7 GB,
- Flux1-dev-Q5_K_S.gguf — 8 GB.
- Flux_dev.safetensors – 23 GB (this is the base FP16 version of FLUX.1 [dev], originally submitted by Black Forest Labs),
- Flux1-dev-fp8.safetensors — 12 Гбайт,
- Flux1-dev-Q8_0.gguf — 13 GB.
FLUX.1’s greatest strengths are its meticulous adherence to long descriptions, photographic realism, and text display. Therefore, we will invite the system to create a living image of one famous literary character using the following hint (the same in this case for CLIP and for T5; a reference cyclogram from the page with examples compiled by ComfyAnonimous itself is used, minimally modified to allow loading GGUF-encoded models) –
— And execute it with the same seed “646124957372314” for all six alternating UNets with different degrees of compression.

Never before has Kisa Vorobyaninov been so close to failure (source: AI generation based on the FLUX.1 model [dev])
The result is discouraging, to be honest. To begin with: the display of relatively long text is indeed excellent in all models, except perhaps for the openly compressed Q_2_K (although the letters there are generally correct), and highlighting in the tooltip the apostrophe required by the rules of French grammar with a backslash helps – this apostrophe is in the word “N’AI” is clearly visible even in those pictures where the diacritic mark above the “E” is lost. Things are also going well with realism, as well as with the overall compositional adherence to the prompt. But here are the details…
First of all, the notorious beard, in this case associated not with the sword (we examined this example last time), but with age. Since the gentleman is designated as “aged” in the tooltip, it is extremely difficult to get rid of the beard and mustache on the image generated by the distilled (and, in addition, it seems strangely chaotically censored) model – even despite the persistent mention of “face is badly shaven (beardless, mustacheless: 1.5 )”. In the Q4_K_S version for this particular seed, 646124957372314, the place of the beard was still taken by five-day-old stubble, which once again emphasizes how reckless it would be to hope to find a successful seed with lighter quantized models, and then with it and with the same hint get a completely similar composition already with a full-fledged UNet/DiT – Q8_0 or FP16.
Another subtle point: pay attention to the hat. Although the hint directly states that it should lie upside down, FLUX.1 does not allow you to get this position, even if you crack it – and we tested this on several dozen generations with different seeds. It’s not just the hats: this model’s upside-down objects are generally difficult to capture, let alone damaged. Broken vases, battle scars on the faces of stern warriors, wounds on the bodies of defeated monsters, even seemingly innocent piercings – almost any requests for images of heavily deformed/modified objects that are well known to the model in their untouched form are fulfilled very poorly. In the community of enthusiasts, ideas have been expressed that perhaps the damaged objects were either completely absent from the FLUX.1 training database, or were deliberately not accompanied by a corresponding text description, so that in the end the set of tokens into which the T5+CLIP bundle parses the mention of an “inverted hat” “, does not indicate anything specific in the latent space. But in any case, as long as the arrays of FLUX.1 training pictures with their detailed descriptions continue to remain closed from the general public, it is impossible to judge this with any complete confidence.
The menu of the ComfyUI add-on manager (by the way, it also perceives itself as an add-on – with serial number 1, of course) allows you to conveniently and quickly update versions of both the working environment itself and already installed add-ons
And now – the most important thing: let’s look at the speeds. The UNet/DiT variants used generated images with a resolution of about 1 Mpix (832×1216 pixels) at a rate of approximately 30 s per iteration for the first three (Q_2_K, Q4_K_S, Q5_K_S) and about 40 s/it. for the remaining three – Q8_0, FP8, FP16. Yes, on our test machine (GTX 1070 8 GB + 24 GB DDR3) it would be difficult to expect a strong difference in performance between the Q8_0 and FP16 variants, but its absence (practically; only within a few units of s/it.) for Q_2_K and Q5_K_S , which differ in volume by almost half, is much more striking. Probably, the need to drive many gigabytes of data back and forth between video memory and slow system RAM during the sequential loading of first T5 and then UNet models negates the advantage provided by the fact that variants with more serious compression fit entirely into video RAM. One way or another, the sacrifice of picture quality when using Q_2_K compared even to Q4_K_S, not to mention Q8_0, does not seem very justified. In other words, it is possible to use a super-compressed and faster model, but you should not hope that later, having found a successful combination of a hint and a seed with its help, you will get a completely similar result in composition, only with improved quality, occupying a larger UNet volume. This means that rapid prototyping only due to compactification of the main FLUX.1 [dev] model will not work. At least with a guarantee.
⇡#Breadth and heights
What are the better options? The first thing that comes to mind is to take advantage of the versatility proudly noted by the creators of FLUX.1 in terms of supporting a very wide range of image resolutions, from 0.1 to 2.5 megapixels. It is intuitively clear that a small image should be generated much faster than a large one. And, perhaps, if among the pictures with a resolution of 0.1 megapixels (conventionally approximately 300 × 300 pixels) quickly baked by the model, you come across a composition that is successful – but, of course, not replete with details – it will be possible, while maintaining the same hints and seeds, to switch to , say, 2 megapixels – and get approximately the same image, but with a resolution of almost 1400 × 1400?
Let’s check. And let’s start by changing the “Empty Latent Image” node, which sets the canvas dimensions in the ComfyAnonimous reference cyclogram, to a more convenient one when working with FLUX.1 – allowing you to set these dimensions more practically than manually calculating the number of pixels on each side. To do this, in turn, you will need to enrich ComfyUI with the next addition, and at the same time we will remind you how to install these same additions into the working environment.
Information about the additions required to run the cyclogram given at the very beginning in the information window of the ComfyUI manager
At the time of writing this Workshop, the current version of ComfyUI is 2.0.7. We have discussed more than once how to install it as an independent package (simply by unpacking it into the working directory from a ZIP file, without the usual Windows installation procedure with setting environment variables in the registry). For the sake of convenience, we will supplement this working environment with an installation manager – ComfyUI-Manager in the current version 2.48.1. Instructions for deploying it are provided on the project’s home page on GitHub and are extremely transparent. In particular, for our case – when ComfyUI itself is installed as an independent package (portable version) – it is required:
- Install git (those who installed AUTOMATIC1111 with us have already done this at one time),
- Load the installation script scripts/install-manager-for-portable-version.bat into the directory where ComfyUI is already deployed (it should be next to the standard startup script for the working environment – run_nvidia_gpu.bat),
- Double-click on the file of this script and wait for the process to complete.
Following this, after starting the working environment – just using the same run_nvidia_gpu.bat – a “Manager” button will appear at the bottom of the main menu of the ComfyUI web interface. It is through this that we will install the necessary add-ons, and at the same time update both them and the working environment as a whole – this is much more convenient than manually.
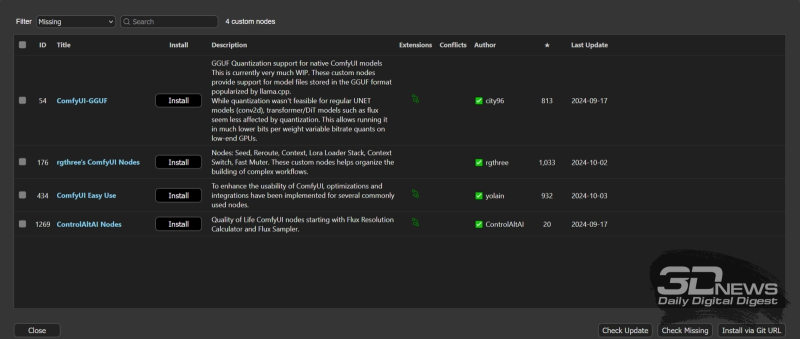
In fact, we’ll immediately supply everything you need at first. Having opened the ComfyUI manager menu, click on the “Custom Nodes Manager” button at the very top of the middle column of the controls available there – and in the window that appears with a list of available extensions, we will find through the search window, select and install the following sequentially (links to the corresponding project pages on GitHub are provided directly in the interface, which allows you to once again make sure that the correct add-on is selected):
- ComfyUI-GGUF – without it it is impossible to load quantized versions of models, and those who worked with us on rapid prototyping with [schnell] should already have it,
- Rgthree-comfy – contains many service nodes that are convenient for our upcoming work,
- ComfyUI-Easy-Use are also convenient service nodes, but with their own specifics,
- ControlAltAI is another set of useful service nodes aimed specifically at FLUX models.
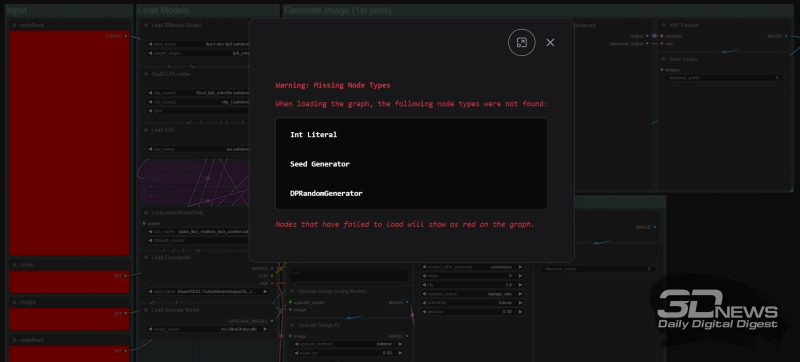
This is approximately how the ComfyUI manager informs about the presence of extensions that have not yet been installed in the cyclogram loaded into the working environment
Actually, you won’t need to manually enter the names of all these nodes into the search window if you download a collection of images from the link provided near the end of this “Workshop”, which we will now begin to obtain. Saved in PNG format with integrated JSON, these files, when dragged into the ComfyUI workspace, will reproduce the cyclograms built into them there. If some of the user’s nodes are not currently deployed, the corresponding rectangular blocks will be marked in red on the cyclogram, and the manager’s add-on will issue a corresponding warning. By then opening the menu of the same manager and clicking on the “Install Missing Custom Nodes” button, it will not be difficult to sequentially install all the necessary extensions. It is also recommended – from the same menu – to regularly, at least once a week, execute the “Update All” command: this will keep both the working environment itself and all the additions for it up to date.
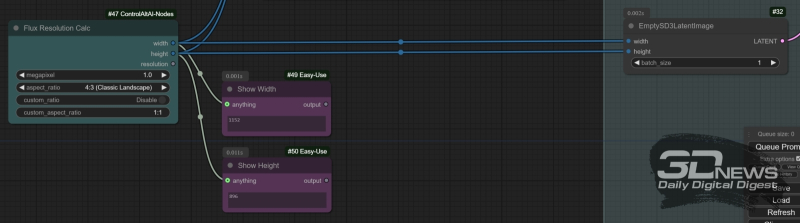
The “Flux Resolution Calc” node from the ControlAltAI add-on allows you not to think about the exact number of pixels on each side of the selected canvas: just set the ratio of these same sides and the overall resolution of the image in megapixels. In turn, the “Show Anything” nodes, in this case used to control the exact values of the width and height of the canvas, will display in their windows the values calculated by this “calculator”
To check whether at least the general composition of the image generated by FLUX.1 [dev] is preserved when increasing only the resolution of the canvas (its area in megapixels) while maintaining other parameters – hints and seeds, we modify the original cyclogram taken from the page with examples of ComfyAnonimous, about which has already been mentioned more than once. There, the canvas size is set by the “EmptySD3LatentImage” node. Why “SD3” – meaning SD3M, of course – because that not very successful Stability AI development model, just like the FLUX.1 family, is focused on supporting canvases in a wide range of resolutions, up to 2. 5 megapixels If you use the standard latent image generator for SDXL/SD 1.5, the limit of which is 1 megapixel, you may encounter unwanted problems at high resolutions.
However, “EmptySD3LatentImage” involves manually setting the canvas width and height. Let’s make our life easier: we convert the input fields of these two values into inputs for connecting external nodes – to do this, right-click on the rectangle representing it and in the menu that appears, select the option “Convert Widget to Input”, in the next level menu – “Convert width to input” and then do the same with the canvas height. But just to set specific width and height values, we’ll use the “Flux Resolution Calc” node from the newly installed ControlAltAI add-on – for it to appear on the ComfyUI workspace, just double-click with the left mouse button on any free area of it and start typing the keyword “resolution”. The node allows you to set the canvas resolution in the range from 0.1 to 2.5 megapixels, and also choose from a wide range of aspect ratios, or set your own manually. To control the exact values of the length and width of the future image, the “Show Any” nodes from the “Easy Use” package are useful: just place two of them close to “Flux Resolution Calc” and connect the “width” and “height” outputs of the latter to them. The same outputs will go to the corresponding inputs of the “Model Sampling Flux” and “EmptySD3LatentImage” nodes.

All three images shown have the same aspect ratio (4:3), seeds and hints. On the top left is an image with a resolution of 0.1 Mpix (368 × 272), below it is 0.5 Mpix (816 × 608), on the right is 1.0 Mpix (1152 × 896) (source: AI generation based on the FLUX model .1 [dev])
Now everything is simple: enter text prompts in the appropriate fields, select the UNet/DiT GGUF version with Q8_0 quantization as the model, fix the seed value (in the “Random Noise” node, change the value of the “control_after_generate” parameter from “randomized” to “fixed”) , select any aspect ratio you like in “Flux Resolution Calc” – and launch sequential generation with the same parameters, but with consistently variable resolution, starting from 0.1 megapixels. As practice shows, although in general the compositions and color schemes of the pictures turn out to be similar, the difference even in large details is too great to be neglected. In other words, you won’t be able to save time by baking 0.1-megapixel images at high speed and waiting for a particularly successful one to appear, and then send an image with the same seed, but with a higher resolution, for generation. It’s a pity; It was definitely worth a try though.
⇡#Knight’s move
It must be said that the use of a reduced resolution, of course, provides time savings: if a 0.5-megapixel picture is generated on our test machine at a speed of 17-19 s/it., then a 1-megapixel image is generated at 36-38 s/it. Considering that the steps for generating images with FLUX.1 [dev] are usually required at least 20 (and, by the way, the difference between 20, 25 and 30 is not too large and is not always in favor of longer generations – another evidence of the distilled nature this model), the difference is quite noticeable. But here’s the problem: if the picture implies the presence of significant small details – letters combined into meaningful words; hands of human hands that would not resemble disheveled brooms; finely crafted patterns that do not merge into a chaotic jumble of pixels, then with a decrease in resolution the quality of such little things (which are not little things at all) radically decreases. The model simply does not have enough pixels in this specific area of the image extracted from the latent space to adequately display the subtle elements required from it by the hint.
So, will you still have to leave FLUX.1 [dev] for a free search by seeds without any hope of increasing the speed of prototyping?
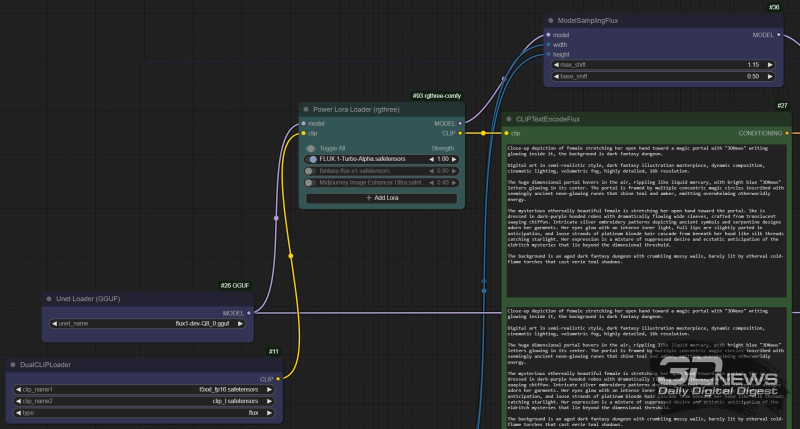
The “Power Lora Loader” node from the rgthree package is inserted into the “model” data stream between the “Unet loader (GGUF)” and “ModelSamplingFlux” nodes, and into the “clip” stream – between “DualCLIPLoader” and “CLIPTextEncodeFlux”
But no! A similar problem for SDXL was at one time partially solved by (pre)training accelerated versions of the corresponding model – through distillation, already familiar to us from FLUX.1. Only, applied to an initially undistilled model, such distillation did not lead to that noticeable decrease in quality that distinguishes FLUX.1 [schnell] from [dev]. For example, SDXL Turbo is able to make do with even one generation step to generate quite tolerable pictures instead of 30-50 for the basic version – thanks to the technology of adversarial diffusion distillation (ADD), and SDXL Lightning in various variations – two, four or eight. Actually, FLUX.1 [schnell] is a version of [dev] distilled in a similar ADD way, but this procedure, as is easy to see, led to an all too noticeable drop in the subjective aesthetic quality of [schnell]-generations, especially in terms of displaying human skin, smooth color gradients and text.

Pictures obtained with completely identical basic parameters, but the first – with FLUX.1-Turbo-Alpha and in 8 steps, and the second and third – without LoRA and in 20 and 30 steps, respectively; top row – with a resolution of 0.5 megapixels, bottom – 1.0 megapixels (source: AI generation based on the FLUX.1 model [dev])
The above example shows, first of all, that for FLUX.1 [dev] there really is no fundamental difference between 20 and 30 generation steps – moreover, small significant details (hands, glowing runes on a magic circle) are likely to lose quality as the number of steps increases what they buy. The FLUX.1-Turbo-Alpha.safetensors accelerator, in turn, slightly coarsens small details, and even treats large ones (face, hood, hair) somewhat freely – but at the same time maintains the overall aesthetics and composition of the image (for each selected canvas resolution) , and in general it provides quite a decent result, especially in terms of text reproduction. The time savings for each generation are significant: after all, 8 steps of about half a minute each (in the case of a 1-megapixel canvas), and not 20, and especially not 30.
Thus, for rapid prototyping with FLUX.1 [dev], it seems logical to use a LoRA accelerator (in our case – FLUX.1-Turbo-Alpha.safetensors) with a reduction in the number of generation steps to 8, as well as the choice of 1.0 Mpix in as a basic resolution – and if small details are not so important, then 0.5 megapixels will do. Then baking each picture in free search mode will take a maximum of 4-5 minutes, which is quite acceptable. More precisely, it is acceptable if it is possible to feed the generative model such a hint that it would be optimally interpreted – and almost guaranteed to generate a result that suits the operator, if not the first, then the third, fifth, or at worst tenth time (whereas in the case of SD 1.5/SDXL, with all the wealth of checkpoints/additions available for them today and the high speed of inference, a free search for a successful visual implementation of a text prompt can take hours, if not days). Is this even real?
In principle, yes, and now we will finally explain what kind of text (and why exactly it) was placed in the windows of the “CLIPTextEncodeFlux” node in order to obtain the pictures shown so far in the examples with a figure in a gas cape standing in front of the portal. The original concept of the image, formulated in English in natural language (with a view to its subsequent interpretation for CLIP by the T5 model – we talked about this feature of FLUX.1 in detail last time), was as follows:
Simple, concise, easy to remember; but for CLIP this will certainly be too much, and for T5 – too little. Let’s give free rein to our imagination and turn the telegraphically neat description of the intended picture into a more detailed one, focusing on details that are important for the final image – a more detailed description of the portal itself, the figure standing in front of it, her clothes and surroundings:

On the left is an image with the expanded hint just given, seed 1002970411169969 and resolution 0.5 megapixels; on the right – everything is the same, but the resolution is 1.0 megapixels (source: AI generation based on the FLUX.1 model [dev])
In principle, this is already a sufficiently lengthy text so that FLUX.1, eager for long descriptions, can create picturesque paintings based on it. But is it not possible to offer the model even more detailed instructions in order to increase the likelihood of producing a known acceptable (to begin with, well-readable text) image to the maximum?
⇡#Depth of detail
The pair of images shown just above, generated by our expanded tooltip, clearly indicates that, although the LoRA-accelerated FLUX.1 [dev] captured the general composition correctly in this case, it has obvious problems with displaying even such a short text. Perhaps the fact is that this text should be located in the middle, or even background, and therefore obviously cannot take up much space on the canvas – therefore, in particular, a 0.5-megapixel attempt to reproduce it looks much worse than a 1-megapixel option. But it’s not just that.
Models of the FLUX.1 family simply adore extensive, well-detailed hints – you should be guided by 150 words, even better, 200. Not everyone, especially if English is not their native language, is able to artistically and at the same time substantively describe the idea of a future digital device hovering in their head the masterpiece is so complete. It’s okay – smart chatbots will come to the rescue, and if you don’t have direct access to ChatGPT or Claude, you can always use generative models freely available on the Internet. For example, Junia.ai, which is positioned as “AI Prompt Writer & ChatGPT Prompt Generator”. Everything is simple there: we enter the original version of our hint into the window on the website – this is the same one, just manually expanded from the original short sentence – and after clicking on the “Generate” button we get (for example, since each time the wording in the generated hint will be slightly others) the following:

Again the same generation parameters, including the seed, again on the left is a picture with a resolution of 0.5 Mpix, and on the right – 1.0 Mpix, but this time an enriched Junia.ai hint was used (source: AI generation based on the FLUX.1 model [dev ])
Already under 180 words, it’s already quite good – and it’s immediately noticeable, by the way, that this generative service is optimized specifically for compiling hints for AI drawing: on its own initiative, it added to the text instructions on the style of the image, its resolution, detail, etc. Everything seems great, and if you place this text in both input windows of the “CLIPTextEncodeFlux” node, the result should be more adequate to the task.
It turns out to be the case, although there is definitely still room for improvement, especially in terms of the text: let’s say, given the given starting point, it simply refuses to be displayed. And here again you cannot do without the direct participation of a live operator on the other side of the screen – smart bots clearly cannot cope alone. In the community of AI drawing enthusiasts, there is a fairly definite opinion that T5, for all its merits, is not the most talented interpreter, and in order to make his work easier, a long hint (written independently or using generative models that convert text to text) should be organized in a certain way. Namely:
- In the first paragraph, give a general description of the intended picture – its composition, relative position and key features of the main elements, and only with the necessary minimum of adjectives, focusing on nouns,
- In the second paragraph, record the visual style of the image – it should be photorealistic or copy some kind of pictorial style; what is the supposed resolution of the picture, what is its color palette, etc.,
- Then devote one paragraph to a maximally detailed description, rich in adjectives and verbs, of each of the key objects of the composition,
- And finally, the last paragraph should be devoted to the background of the future image, if it is compositionally significant.
Having worked in this way on the text proposed by Junia.ai, we constructed this:

Expanded and rethought (paragraph by paragraph) hint, seed 1002970411169969, resolutions: left – 1.5 Mpix (1408 × 1088 pixels, 155 s/it.), in the center – 2.0 Mpix (1632 × 1216 pixels, 374 s/it. .), right – 2.5 megapixels (1824×1376 pixels, 814 s/it.) (source: AI generation based on the FLUX.1 model [dev])
Digital art style, cinematic lighting, volumetric fog, highly detailed, 8k resolution, dark fantasy artwork.
The background is an aged dark fantasy dungeon with crumbling mossy walls, barely lit by ethereal cold-flame torches that cast eerie blue shadows.
In fact, we previously presented the pictures obtained precisely with this hint and seed 1002970411169969 as illustrations with resolutions of 0.1, 0.5 and 1.0 megapixels. By the way, it is noticeable that when the number of pixels increases above 1.5 megapixels, although the elaboration in individual details improves (textures of fabric, stone, etc.), the letters again begin to work out worse for the model. Apparently, 1.0 megapixels is the best balanced resolution from the point of view of the balance between the quality of displaying average-sized letters, hands and other little things that are not little things at all. We will dwell on it later.
⇡#But that’s not all
The question remains: what to do with the distribution of the received text paragraphs across a pair of input windows of the “CLIPTextEncodeFlux” node? In the previous examples, both the “clip_l” window and the “t5xxl” window simply copied this entire long hint in its entirety, all five of its paragraphs, although readers of our last “Workshop” should remember that there is a right to life and a different approach when Only a general description of the picture is supplied to the input of the text converter into CLIP tokens, and a more extensive description is supplied to the input of the “interpreter” T5. Perhaps, in this case, it makes sense to limit yourself to only the first one or two paragraphs in the upper window, and enter either all of them in full, or only those remaining from the general description, in the lower one?

Various versions of combinations of five paragraphs from our full hint in the text input windows for CLIP and T5; see explanations in the text (source: AI generation based on the FLUX.1 model [dev])
We conducted a fairly straightforward experiment: first, leaving all five paragraphs of the prepared hint text in the lower window of the “CLIPTextEncodeFlux” node, we entered either the first two together, or only the first, or only the second into the upper window; then the first two paragraphs were removed from the window for T5, leaving only the third to fifth, and in the window for CLIP the previous cycle was repeated – the first two paragraphs, only the first, only the second. The results are obvious: the very first option is better than others in terms of composition and quality of details (primarily text) – when the CLIP model is fed the first two paragraphs, outlining the general construction and artistic solution of the intended picture, and for T5 these paragraphs are duplicated, supplemented by three more with more detailed instructions on how and what should be depicted. With all other combinations of paragraphs, either the figure of the mysterious stranger at the portal suffers (the neck is excessively stretched), or the text, or the mysterious runes in the magic circles, or all of this together.

On the left are identical tooltips in both windows of the “CLIPTextEncodeFlux” node; on the right – for CLIP only the first two paragraphs, for T5 – all five (source: AI generation based on the FLUX.1 model [dev])
However, it would still be reckless to deprive CLIP of the opportunity to work on the full text independently, and not just with the help of T5. In the example we give, there is a difference between pictures with complete duplication of text prompts and with only the first two paragraphs left in the CLIP field. Yes, it is barely noticeable – it manifests itself only in subtle details such as the facial expression of the figure at the portal, the elaborateness of the embroidery on her cape and the greater/less similarity of the amber ornament on the outside of the magic circle with a mysterious alphabetic script, and not just with abstract patterns. If you limit the work of generating an image that suits the operator with a resolution of 1 megapixel, there may be no point in copying the same text into both “CLIPTextEncodeFlux” windows – even if the upper one contains only the most general instructions to the AI artist and only the second contains a complete hint. But taking into account the fact that the picture can (and often needs to be!) enlarged, not only without losing quality in detail, but with its increase, it is better to stick with complete duplication.
Since we have already seen that enlarging the FLUX.1 [dev] generation by simply increasing the canvas resolution while maintaining all other parameters does not work – in the sense, it violates the original composition – let’s turn to a tool that has been well known since the days of SD 1.5. Namely, to the image-to-image transformation, during which the original image becomes the basis of the canvas for a larger one, so that the enlarged image is generated not on a rectangle obtained from a random seed, chaotically filled with colored spots, but, in fact, on a stretched and only slightly noisy original image. All the necessary nodes for this are already available in the extensions we installed for ComfyUI, and the corresponding cyclogram is presented in the set of pictures accompanying this “Workshop” (a link to them is given closer to the end of the text) called Dev_upscaled_B_00014_.png.
General view of the cyclogram for a twofold (for each of the measurements) enlargement of the 1-megapixel image we received using the same FLUX.1 model [dev]
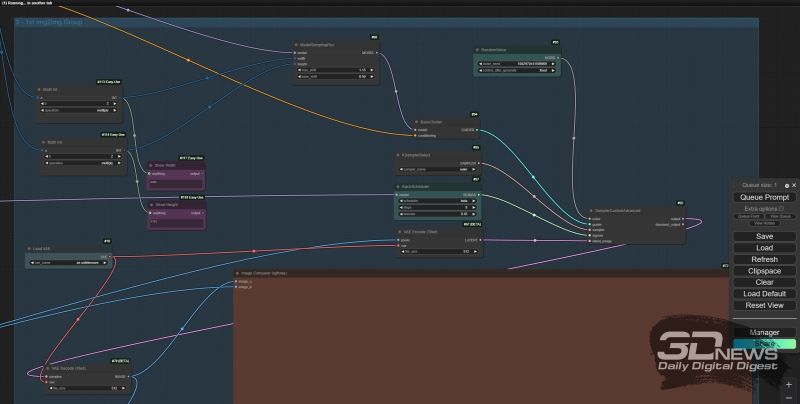
Organization of the block of nodes “1st Img2Img Group”: the “denoise” parameter (in this case – 0.45) of the “BasicScheduler” node is responsible for the strength of the influence of the new generation on the result of the previous one.
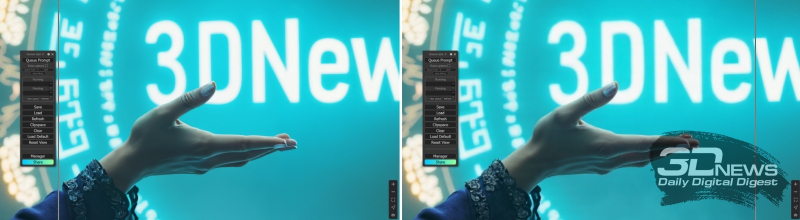
Actually, with this exception – that instead of a latent image directly from “EmptySD3LatentImage”, the input of the main FLUX.1 processor node, “SampleCustomAdvanced”, is supplied through “VAE Encode (Tiled)”, an image stretched by an external upscaler intended for enlargement – the “1st” block Img2Img Group” is almost completely identical to the original cyclogram with the use of which the considered We just have images with five paragraphs of text as a hint. From a practical point of view, the “Image Comparer (rgthree)” node from the corresponding add-on is of interest: it allows, by simply moving the mouse left and right, to visually compare two images supplied to its inputs. And, as you can see, the quality really improves with such magnification.
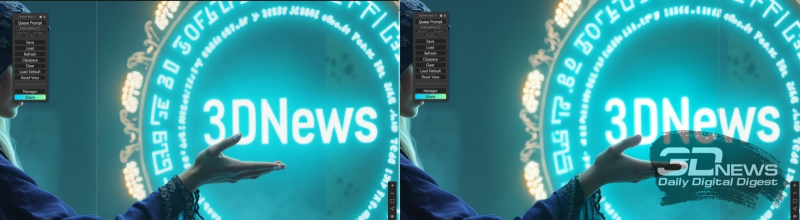
A visual demonstration of the operation of the “Image Comparer (rgthree)” node: on the left – the vertical slider line is shifted to the left; the field of the picture to the right of it, including the hand and the magic portal, corresponds to the result of scaling with increased quality; on the right – the slider has been moved to the other side, and now it is clearly visible that the image simply enlarged using “Upscale Image By” is clearly inferior in detail to the final one
Further on our test computer, scaling the image in the same way – by loading the image now saved in the file Dev_upscaled_B_00014_.png into the “Load Image” node on the same diagram and simply repeating the process – is problematic: to retain in memory and simultaneously process the image distributed twice in both dimensions The picture will not be enough even for the total amount of RAM and video RAM at its disposal. Well-developed tiled upscale for SD 1.5/SDXL based on ControlNet for FLUX models is still in its infancy, although reasonably working examples of the use of such a technique are already known. However, no one bothers to apply tiled upscale to the resulting image with an SDXL checkpoint, for example, which at the same time will eliminate the problem of human skin looking overly unnaturalistic, especially at such high resolutions.
General view of the cyclogram for the next twofold (for each of the dimensions) image enlargement – but with the SDXL Turbo checkpoint
To do this, you will need to install another extension, UltimateSDUpscale, through the ComfyUI manager, and use an extremely simple cyclogram, which is integrated into the UltimateSDUpscale_00002_.png file from our archive with examples. As a result, an image with a resolution of 4 megapixels (2304 × 1792) will result in an even more improved quality 16 megapixel (4608 × 3584).
And the “Image Comparer (rgthree)” node works again, only after UltimateSDUpscale: on the left – output of the final scaling with FLUX.1 [dev]; on the right is a twofold (for each of the dimensions, i.e. fourfold in area) magnification with the checkpoint DreamShaper XL Turbo v. 2.1
Finally, if this is not enough, enthusiasts have the powerful Make Tile SEGS Upscale tool from the ComfyUI-Impact-Pack package, which also needs to be installed into the working environment through the manager. Using it, however, you will have to have a fair amount of patience – on our test computer, the procedure for obtaining a picture with a resolution of 9216 × 7168 pixels, the file MakeTileSEGS_upscale_00017_.png with a size of 54 MB, took more than six hours, but if you want to print the resulting picture in the form of an A3 poster , for example, this is just the right size.

For technical reasons, on this page we can place a picture with a maximum horizontal size of only 1600 pixels, whereas in the original there are 9216 (source: AI generation based on the FLUX.1 model [dev])
All files mentioned throughout this “Workshop” can be downloaded in a single archive (be careful: 104 MB!) from the cloud. And here we stop studying the FLUX.1 family of models – and begin to take a close look at Stable Diffusion 3.5: the community of AI drawing enthusiasts has very high hopes for it. Perhaps this undistilled model will manage to become the main working tool for fans of generative computer graphics, finally displacing the well-deserved SDXL from this pedestal? Wait and see.