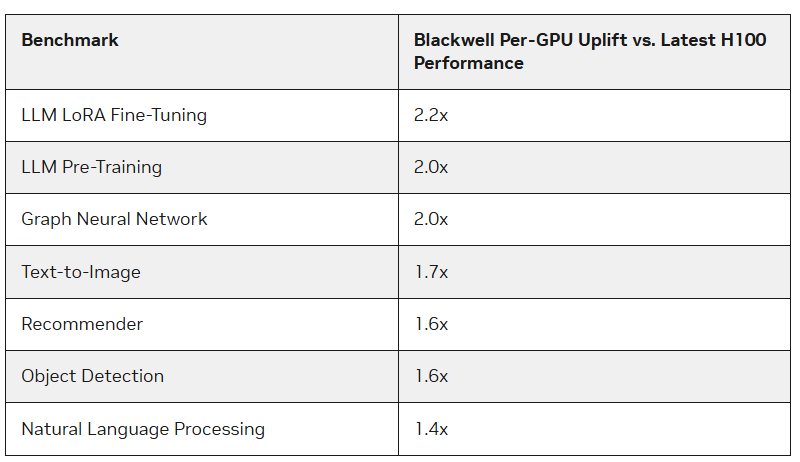
NVIDIA’s Blackwell accelerators outperformed H100 chips in the MLPerf Training 4.1 benchmarks by more than 2.2 times, The Register reported. Blackwell’s higher memory bandwidth also played a role, NVIDIA said. Tests were carried out using NVIDIA’s own Nyx supercomputer based on the DGX B200.
The new accelerators have approximately 2.27 times higher peak performance in FP8, FP16, BF16 and TF32 calculations than the latest generation H100 systems. The B200 showed 2.2 times better performance when tuning the Llama 2 70B model and twice the performance when pre-training the GPT-3 175B model. For recommender systems and image generation, the increase was 64% and 62%, respectively.
The company also noted the benefits of the B200’s HBM3e memory, which enabled the GPT-3 benchmark to run successfully on just 64 Blackwell accelerators without compromising the performance of each GPU, whereas 256 H100 accelerators would have been needed to achieve the same result. However, the company also does not forget about Hopper – in the new round, the company was able to scale the GPT-3 175B test to 11,616 H100 accelerators.

Image source: NVIDIA
The company noted that the NVIDIA Blackwell platform provides a significant performance boost over the Hopper platform, especially when running LLM. At the same time, Hopper generation chips still remain relevant thanks to continuous software optimizations, sometimes increasing performance in some tasks by several times. The intrigue is that this time NVIDIA decided not to show the results of the GB200, although both it and its partners have such systems.
In turn, Google presented the first round of testing results of the 6th generation TPU called Trillium, the availability of which was announced last month, and the second round of results of the 5th generation TPU v5p accelerators. Previously, Google only tested TPU v5e. Compared to the latter option, Trillium provides a 3.8x performance gain on the GPT-3 training task, notes IEEE Spectrum.

If we compare the results with NVIDIA’s indicators, then everything does not look so optimistic. The 6,144 TPU v5p system reached the GPT-3 training benchmark in 11.77 minutes, behind the 11,616 H100 system, which completed the task in approximately 3.44 minutes. With the same number of accelerators, Google’s solutions are almost twice as slow as NVIDIA’s solutions, and the difference between v5p and v6e is less than 10%.
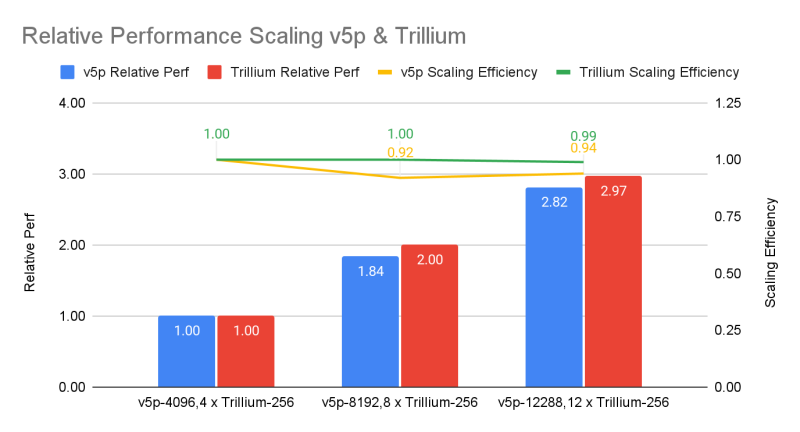
Image source: Google
In the Stable Diffusion test, the 1024 TPU v5p system took second place, finishing in 2.44 minutes, while the same size NVIDIA H100-based system completed the task in 1.37 minutes. In other tests on smaller-scale clusters, the gap remains approximately one and a half times. However, Google focuses on scalability and the best price-performance ratio in comparison with both competitors’ solutions and its own accelerators of previous generations.
Also in the new round of MLPerf, the only result of measuring energy consumption during the benchmark appeared. A system of eight Dell XE9680 servers, each of which included eight NVIDIA H100 accelerators and two Intel Xeon Platinum 8480+ (Sapphire Rapids) processors, consumed 16.38 mJ of energy in the Llama2 70B tuning task, spending 5.05 minutes on the job. — average power was 54.07 kW.