Google announced that its latest AI accelerators TPU v6, codenamed Trillium, are available to customers for review as part of the GCP cloud platform. It is claimed that today the new product is Google’s most effective solution in terms of price/performance ratio.
The official presentation of Trillium took place in May of this year. The product is equipped with 32 GB of HBM memory with a bandwidth of 1.6 TB/s, and the ICI inter-chip interconnect provides the ability to transfer data at speeds up to 3.58 Tbit/s (four ports per chip). Third-generation SparseCore blocks are used, designed to speed up work with AI models used in ranking and recommendation systems.

Image source: Google
Google highlights a number of significant advantages of Trillium (TPU v6e) over TPU v5e accelerators:
- More than fourfold increase in performance when training AI models;
- Inference performance increases up to three times;
- Improved energy efficiency by 67%;
- Increase in peak computing performance per chip by 4.7 times;
- Double increase in HBM capacity;
- Doubling the throughput of the ICI inter-chip interconnect.
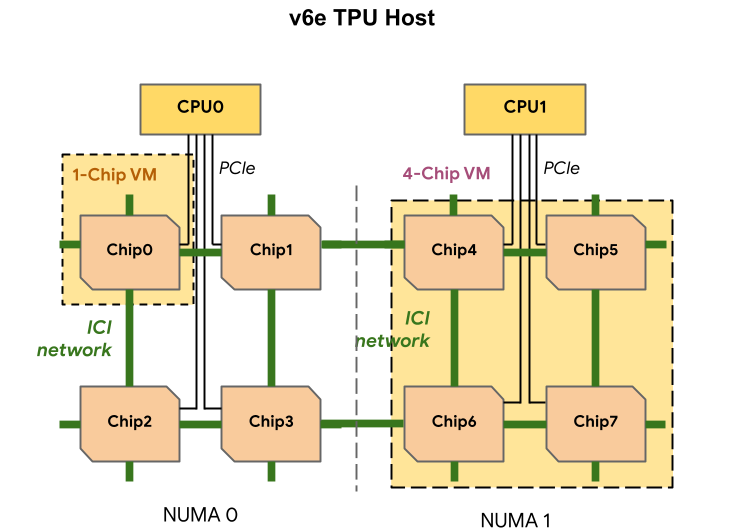
One node includes eight TPU v6e accelerators (in two NUMA domains), two unnamed processors (180 vCPUs in total), 1.44 TB of RAM and four 200G adapters (two per CPU) for communication with the outside world. It is noted that up to 256 Trillium products can be directly connected through ICI, and the aggregated network connection speed of such a cluster (Pod) is 25.6 Tbit/s. Tens of thousands of accelerators can be connected into a large-scale AI cluster thanks to Google’s Jupiter optical switching platform, with a combined throughput of up to 13 Pbps. Trillium is available as part of the AI Hypercomputer integrated AI platform.
Multislice Trillium software is said to provide near-linear performance scaling for AI training workloads. Trillium-based clusters can deliver up to 91 Eflops of AI performance, four times faster than the largest TPU v5p deployments. BF16-performance of a single TPU v6e chip is 918 Tflops, and INT8 – 1836 Tops.
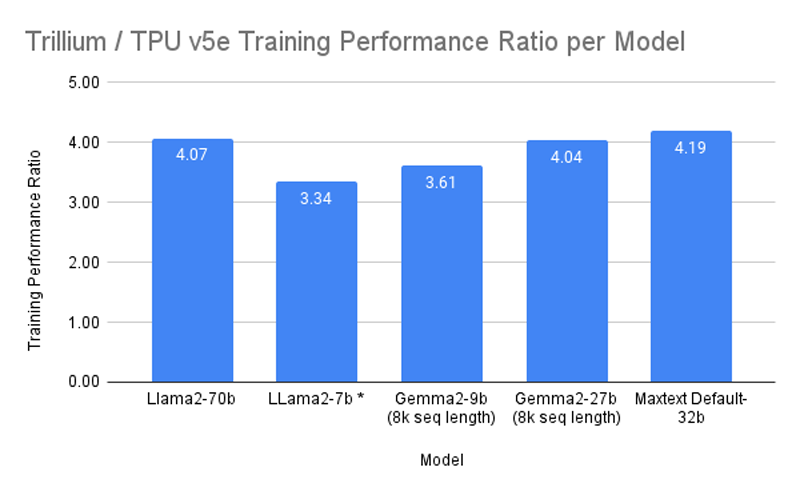
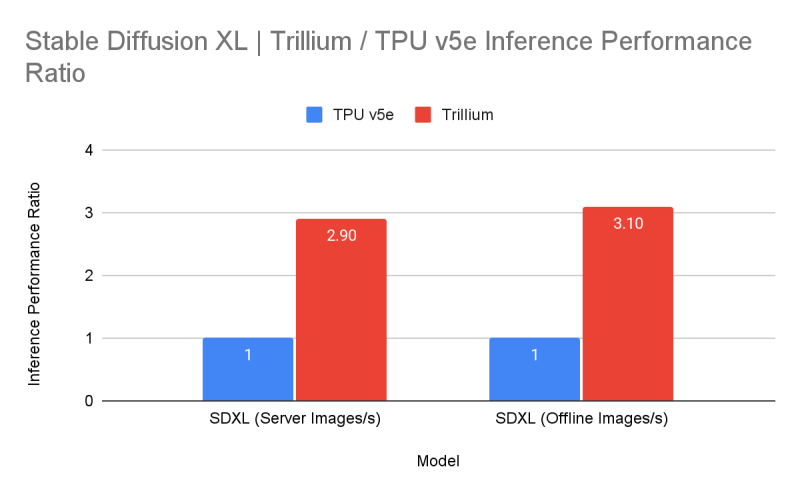
In the Trillium benchmarks, compared to TPU v5e, it showed a more than four-fold increase in performance when training models Gemma 2-27b, MaxText Default-32b and Llama2-70B, as well as a more than three-fold increase for LLama2-7b and Gemma2-9b. In addition, Trillium provides a three-fold increase in inference performance for Stable Diffusion XL (relative to TPU v5e). In terms of price/performance ratio, TPU v6e demonstrates 1.8 times the increase compared to TPU v5e and approximately 2 times the increase compared to TPU v5p. Whether a more productive TPU v6p modification will appear is not specified.