Adobe has officially introduced a new generative neural network, Firefly Video Model, which is designed for working with video and has become part of the Premiere Pro application. Using this tool, users will be able to supplement the footage, as well as create videos based on static images and text prompts.

Image source: Adobe
The Generative Extend function based on the mentioned neural network is becoming available to Premiere Pro users as part of beta testing. It will allow you to extend the video by a few seconds at the beginning, end, or some other segment of the video. This can be useful if during the editing process you need to correct minor defects, such as a shift in the gaze of a person in the frame or unnecessary movements.

Generative Extend can only extend a video by two seconds, so it’s only suitable for making small changes. This tool works in 720p or 1080p resolution at 24 frames per second. The function is also suitable for increasing the duration of audio, but there are limitations. For example, a user can extend a sound effect or ambient noise up to 10 seconds, but this cannot be done with conversation recordings or music tracks.
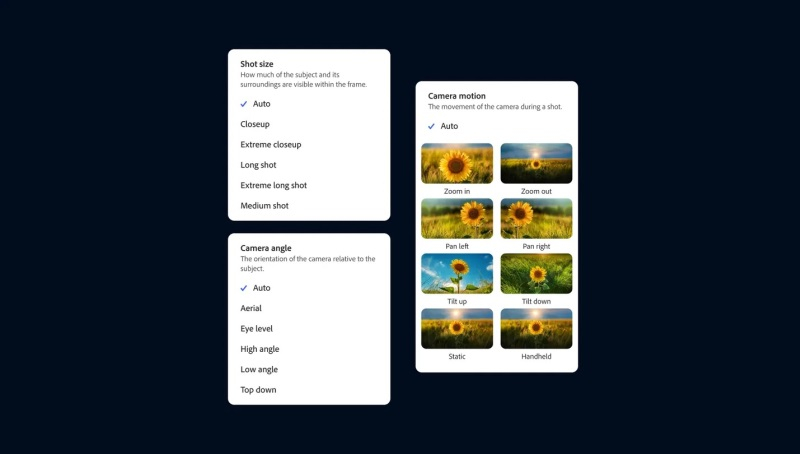
The web version of Firefly has two new video generation tools. We are talking about the Text-to-Video and Image-to-Video functions, which, as the name suggests, allow you to create videos based on text prompts and static images. Both features are currently in limited beta testing and may not be available to all Firefly web users.
Text-to-Video works similarly to other AI video generators, such as OpenAI’s Sora. The user needs to enter a text description of the desired result and start the video generation process. Simulation of different styles is supported, and the generated videos can be further refined using a set of “camera controls” that allow you to simulate things like camera angle, movement and change the shooting distance.
Image-to-Video allows you to add a static image to the text description so that the generated videos more accurately meet the user’s requirements. Adobe suggests using this tool, among other things, for reshooting individual fragments, generating new videos based on individual frames from existing videos. However, published examples make it clear that this tool, at least at this stage, will not allow you to abandon reshoots, since it does not accurately reproduce all objects in the image. Below is an example of the original video and a video generated based on a frame from the original.