At the very beginning of August, the previously unknown startup Black Forest Labs, or simply BFL, presented another locally executable model for generating static images based on text prompts – FLUX.1. More precisely, we are talking here about a whole family of models, which includes:
- Version FLUX.1 [pro] – for commercial use, and exclusively online, via the API (the weights of this version are not made available for public use);
- FLUX.1 [dev], somewhat reduced in capabilities, available for research and non-commercial purposes (not everything is transparent with the license, but the generation results can be freely used);
- And a completely lightweight, fully accessible FLUX.1 [schnell] (Oh ja, du verstehst es richtig!), which runs several times faster than the dev version on the same hardware, but is also subjectively inferior in quality the resulting images. To be fair, we note that it does not lag behind by the same several times: even schnell-generations on average are obviously more attractive than those generated by SD3M and those produced by the basic SDXL without add-ons (i.e., without the use of pre-trained checkpoints, as well as LoRA tools, ControlNet, IP Adapter, etc.).
Both according to the statements of the developers, and according to the enthusiastic responses of the community of enthusiasts who cannot get enough of playing with FLUX.1 since the beginning of August, the ability, even in the schnell version, to literally adhere to the instructions given in the prompt (what is called prompt adherence) and, even more so, to draw human brushes The new product is comparable only to the leading commercial products in this regard – the latest versions of Midjourney and Dall-E – and is completely superior to the creations of Stable Diffusion, including the SD3M we recently reviewed as a first approximation.

Sometimes grass is just grass, not fraught with the slightest danger for the girls depicted on it (source: AI generation based on the FLUX.1 model)
⇡#Talents and understatements
The BFL team (someone is probably going old school right now with the reference to the “ultimate weapon” – BFG from the legendary Doom) includes, in particular, people such as Andreas Blattmann, Dominik Lorenz, Patrick Esser ( Patrick Esser and Robin Rombach. The same four are present in the list of authors of a key scientific publication for the current stage in the development of artistic generative AI – High-Resolution Image Synthesis with Latent Diffusion Models, published in April 2022. In fact, all of them took part in the development of generative models based on the principles of latent diffusion ( Stable Diffusion) for the Stability AI company (and even earlier – in the CompVis and RunwayML projects) and at different times left it – in order, obviously, to implement their own approach to such tasks, not constrained by the aspirations and plans of external management.
BFL’s rather sparse official website describes the startup’s mission as “developing and advancing state-of-the-art generative deep learning models for media such as images and video, and empowering creativity, efficiency, and diversity.” Note that there are no mentions of “safety” here, which were simply teeming with the not-so-long-ago announcement of Stable Diffusion 3. Indeed, with the display of (clothed) girls on the grass, the public versions of FLUX.1 are doing well. Not surprisingly, the new chatbot Grok-2, the creation of Elon Musk-owned startup xAI, relies on the BFL development model to create images based on user requests, although the choice in the current online image generation market, especially commercial ones, is already excessively broad: Musk’s company could afford any partnership.
From a practical point of view, FLUX.1 has already gone to the people, as they say. Not even a couple of weeks have passed since the opening of access to this model (including the pro version) on the popular image generation site Civitai, and already almost 90% of all images that receive the maximum number of reactions there per day are generated by it. Despite the fact that creating one picture with FLUX.1 [dev] “in the basic configuration” (20 steps, no add-ons like LoRA) costs 30 “bz-z-z” (buzz, local currency that you can buy for real money, you can earn money by collecting reactions of other users to your successful creations), and with FLUX.1 [pro] – even 65 bz-z-z. Whereas one SDXL generation (even with an impressive list of auxiliary LoRAs and a large, 35-50, number of steps) rarely costs more than 7-12 bz-z-z. In addition, dev and schnell versions are available for download on user PCs from both Civitai and Hugging Face – I don’t want to create! Yes, they are a bit heavy – about 23 GB each. Not excluding, by the way, the high-speed FLUX.1 [schnell]: it takes up the same amount of memory space as the dev version, it’s just optimized so as to produce a decent result in all respects in not about 20 iteration steps (steps ), as in the case of dev, but for only 4. And although at first glance such an impressive file size may seem like a clear disadvantage to owners of video cards with less than 24 GB of RAM, in practice this is a question that can be resolved, and what exactly should be done To solve it, we will soon look into it in detail.
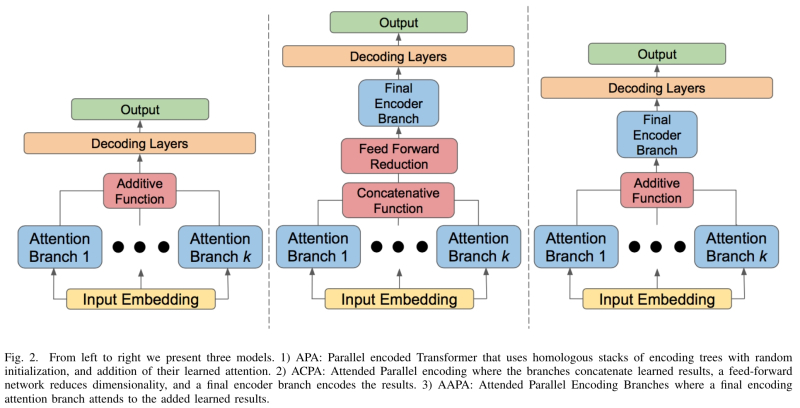
Three options for implementing parallel attention layers in transformer architecture for generative models (source: University of Colorado Colorado Springs)
Another thing is that with the theory of FLUX.1, not everything is transparent. To begin with, the model itself is described rather sparsely by its creators, although the releases of the cornerstone checkpoints Stable Diffusion were regularly accompanied by at least brief review articles that shed light both on the architectural features of the new products and on the intricacies of the operator’s interaction with them: display what objects and scenes they can do better, what to pay attention to when composing hints, etc. With regard to FLUX.1, all that is known so far is that the models of this series are built on the basis of a hybrid architecture that combines transformation and diffusion methods, and that they are capable scale up to 12 billion parameters – it must be assumed that the specified limit value is implemented by the “closed” version (available only through the API on sites that are entrusted to host it) pro version. A special training method using flow matching helps to achieve the demonstrated impressive results, due to which the system’s training in generative modeling is accelerated, as well as the integration into its composition of positional embedding with rotation matrices (rotary positional embedding, RoPE) and layers of parallel attention ( parallel attention layers, PAL).
It is thanks to the successful implementation of RoPE that, apparently, the FLUX.1 models are so good at generating coherent, i.e. connected images with high detail – this is when, for example, a person stands against the background of a horse and the legs of both, taking into account mutual overlaps are rendered in full accordance with how they would look in reality, without turning into a homogeneous, indistinct mess. PALs, in turn, are responsible for the mutual consistency of individual elements in the image: say, if the system is asked to depict watering flowers from a watering can, the water in the generated picture will flow exactly from the spout (unless the tooltip explicitly states otherwise, of course); to hold the watering can, the person caring for the flowers, even if he is outside the frame, will hold the handle, the position of his hand on this handle will be quite definite (thumb on one side, four others on the other), etc. The developers themselves claim that in comparison with Midjourney v6.0, DALL·E 3 (HD) and SD3-Ultra, their creation – especially in the pro version – turns out to be superior or at least almost identical in almost all respects. From subjective, like the quality of the final picture and its “aesthetics” (whatever that is meant by), to quite mathematically calculable ones, like the accuracy of the image’s correspondence to what was formulated in the original hint, as well as the speed and energy efficiency of each individual generation.
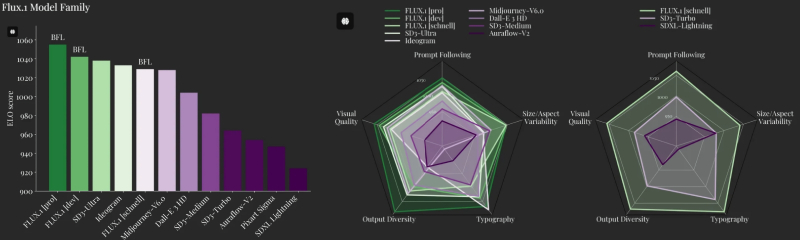
Left: Comparison of the FLUX.1 family of models with the best competitive analogues according to the combined ELO Score rating. In the center: five-parameter comparison of the same models in subjective tests (visual quality, following a hint, variability in canvas sizes and aspect ratios, reproduction of typography, variety of output). Right: the same five-parameter comparison, but separately for the schnell version and the SD3 Turbo and SDXL Lightning, which are similar in speed/resource consumption (source: BFL)
Another important uncertainty that AI drawing enthusiasts were immediately concerned about was the vague licensing of the FLUX.1 [dev] middleware. Everything is clear with the schnell version: it is distributed under the Apache 2.0 license, which implies, in particular, its free commercial use. There are also no questions regarding pro: its weights are not publicly available, so no one from the outside can claim its commercial use – only for the pictures it generates. Let us note for clarity that the results of the generation of any AI model (at least in the United States, whose jurisdiction is subject to BFL) are officially recognized as not protected by copyright, even if the seed for the resulting image was a text, voice, or other prompt composed by a person. In other words, an image created by any of the FLUX.1 varieties (whether for money, or for free on a third-party site, or on your own PC) does not belong to anyone – and it can be freely used to illustrate commercial materials, for example. But the non-commercial license for FLUX.1 [dev] is written in a somewhat confusing language, which seems to allow the use of this model for research purposes (for training enthusiasts with the same LoRA or text inversions based on it) – but at the same time prohibits its use with for the purpose of obtaining benefits, i.e., to create such hybrid/derivative models, which would then be made available for use for a fee. One way or another, since we will not make any modifications to the FLUX models within our “Workshop”, we will generate pictures using them and post them here, and whereanything you want is completely free for research/illustrative purposes.
⇡#And there were conversations…
We will assume that regular readers of our “Workshop” already have installations of the AUTOMATIC1111 and ComfyUI working environments deployed on their computers. At the time of writing this article, only ComfyUI and Forge (a related project to AUTOMATIC1111, but developed independently) could boast of full support for FLUX, so we will not multiply the entities and choose to experiment with FLUX – the name of the model, by the way, was clearly chosen to detract from “Stable Diffusion” , since it is translated as “continuous movement, flickering, vanity,” that is, a complete lack of stability – the already familiar ComfyUI working environment. Although the Forge interface, which is less action-packed in terms of its application to the new series of models from BFL, especially those modified in terms of checkpoint compression, has received the most positive reviews.
The reference cyclogram for working with the checkpoint flux1-dev-fp8.safetensors is quite laconic
As noted in the last issue of the Workshop, for experiments with new models it makes sense to install separate independent versions of the working environment – fortunately, it is available in a standalone version, which simply involves unpacking from the downloaded archive into the selected directory, without a “normal” installation with registering paths and environment variables in the Windows registry. At the same time, this helps to maintain separate versions of Python and additional packages that come with each independent version of ComfyUI, which protects previous, fully functional installations from accidental damage. Therefore, you just need to download the latest stable version (0.1.2 at the time of writing this article), namely the file called ComfyUI_windows_portable_nvidia.7z, from the official page of this working environment on GitHub, and unpack it to your favorite directory. In our case, let’s call it ComfyUI_012 – just with a direct indication of the version number. Let us remind you, just in case, that this option is only for execution on NVIDIA graphics adapters or directly on an AMD or Intel CPU (which, of course, will be much slower): owners of AMD video cards are offered a crutch in the form of the rocm and pytorch packages, which can be installed via pip download manager.
The next step, as before, is loading the actual executable models. The author of the working environment that is relevant to us this time, ComfyAnonimous, has a fairly detailed guide on downloading various versions of FLUX.1 [dev] and FLUX.1 [schnell] and their corresponding reference cyclograms – by the way, the latest, “accelerated” version of the model we will not actively use it for reasons that will be explained a little later. Since our test system has a GTX 1070 graphics adapter with only 8 GB of video memory, let’s scroll to the end of the manual page – there is a section “Simple to use FP8 Checkpoint version”. It contains a link to a repository maintained by Comfy.Org (the team of AI drawing enthusiasts that gathered around ComfyAnonimous after his departure from Stability AI), where you can download the file flux1-dev-fp8.safetensors – a truncated version of the set of weights for the FLUX.1 model [ dev]. The point is that the originally published BFL weights are in 16-bit floating point format, FP16; and converting them (with coarsening, of course) into FP8 allows you to halve the amount of memory occupied by the model – at the cost, of course, of some deterioration in the results of its work. It is argued that 8-bit encoding is approximately equivalent to 16-bit in terms of faithfully following a given hint and constructing coherent images – but copes worse with small details. One way or another, owners of 8 GB video cards cannot afford to be too picky, so let’s download the specified file and place it in the ComfyUI/models/checkpoints/ directory, standard for placing checkpoints.
«Excuse me,” asks the attentive reader who has decided to follow our guide to the letter, “what’s the point, having an 8 GB video card, to pump out even a stripped-down model if it still takes up 17.2 GB?” — and this is precisely the size of the file flux1-dev-fp8.safetensors proposed by Comfy.Org. The point, however, is that ComfyUI (as, by the way, for some time now also in Forge) has implemented the ability to “glue” the computer’s RAM with video memory – seamlessly for programs executed in these working environments, but, of course, with the provision of less high performance than if the model fit entirely into video RAM. Nevertheless, our test system currently has 24 GB of RAM installed, so the total available volume with video memory is 32 GB – this, strictly speaking, is enough for the FP16 version of FLUX that is not truncated in accuracy (which we will discuss a little later). let’s make sure). Without a doubt, the transfer of data between two different types of memory through the system bus cannot but affect the processing speed of the model – it will be in the tens (and it would be good if the first tens) of seconds for each iteration.
The cyclogram for FLUX.1 [dev], which is implemented by an ensemble of submodels, looks more complicated, but is also quite logical and consistent
That is why for PCs with video memory less than 16 GB it is recommended to use FLUX.1 [schnell] – there are still 4 iterations per image, and not 20, with approximately the same model size in bytes. However, looking ahead, we note: FLUX is so good that with a well-designed hint, it is quite possible to obtain an aesthetically suitable result, if not directly from the first, then, conditionally, from the third to eighth attempt – that is, the duration of generation of each image (if compared with SDXL or SD3M) is most often compensated by the brevity of a series of such images until the user is satisfied. This is precisely why BFL’s creation is attractive: it allows you to get away from the “semi-blind search” mode familiar to the operators of “Lorry” and “Overseas”, when the PC is running in an endless loop mode (the hint and other generation parameters are stable, only the seed value changes) for an hour, two or more, producing one picture every 1-3 minutes. And from time to time they approach it – but only to check whether an aesthetically outstanding option has suddenly appeared, suitable for further processing using the inpaint tool or an external graphic editor. FLUX, as a rule, produces an image that is already suitable for further use “as is” after a very modest number of attempts. There are, of course, some subtleties here, we will touch on them soon, but the general feeling from the new model is that the final extraction from the latent space of compositionally and aesthetically attractive images, at first glance at which the satisfied operator decides to stop generating according to the current hint, it produces inOverall faster than before (SD 1.5, SDXL, SD3M), not slower. Although each individual picture, to be honest, takes minutes and tens of minutes to generate.
⇡#A wide channel will come in handy
In the material dedicated to SD3M, we have already modified the launch file of the working environment – run_nvidia_gpu.bat – in order to include a call to the external Python module venv (virtual environments; if the system does not have it, you can always install it) and, on the contrary, remove a number of optimizations carried out specifically for the standalone version. In this case, you still have to use these optimizations – they activate, in particular, the “gluing” of RAM with video memory, which will provide the weighty FLUX model with the ability to run on the modest hardware of our test PC. Therefore, again assuming that AUTOMATIC1111 with venv is already deployed on the system, we will create a new launch BAT file called run_with_venv.bat and the following contents:
@Echo off
Echo %cd%
Call activate.bat
Echo venv activated
Echo %cd%
Pause
The “–disable-auto-launch” parameter when starting the working environment blocks the automatic opening of its web interface in the default browser. Why should it be blocked? Yes, because on a constantly used PC, a great many tabs are probably open in the default browser, and it is preferable to use ComfyUI with FLUX in another one that is launched as rarely as possible – or at least, scary to say, in the standard Edge for Windows systems. The fewer open tabs, the less space in RAM the browser takes up, and since the system RAM is glued together in this case with video RAM in order to fit a huge model there, the more modest the list of active programs on a given PC when it generates images, the better. Of course, you can always estimate the amount of free RAM through the “Task Manager”, and if it is large enough, you can still run something urgently needed, but those who initially have limited resources should use computing resources with special caution.

On the left is the reference generation based on the reference cyclogram with the flux1-dev-fp8.safetensors model from the ComfyAnonimous manual; on the right is the result of running the same model with the same parameters on our test PC. The differences are most likely due to differences in the venv/pytorch versions used (source: AI generation based on the FLUX.1 model)
After starting the working environment (the model file, 17.2 GB flux1-dev-fp8.safetensors, must first be loaded – and even before double-clicking on run_with_venv.bat placed in the ComfyUI/models/checkpoints/ directory) in favorites for working with In your browser, preferably one that does not contain any extra tabs, you should open the web interface at 127.0.0.1:8188 and make sure that it is accessible. Then from the already mentioned page (yes, it can be temporarily opened in the next tab and closed after downloading) all that remains is to download the reference cyclogram for this model authored by the same ComfyAnonimous in the form of a png file – and simply drag it with the mouse from the Explorer window » to the ComfyUI work field. All the necessary nodes with the necessary parameters, including a hint, will immediately be displayed there. Clicking on the “Queue prompt” button in the poor interface of the working environment will launch the cyclogram for execution – and the result should be a picture that is generally similar to the original one, containing the reference cyclogram.
Well, everything works, although it takes an incredibly long time: instead of the usual SDXL 6-7 s per iteration (of which in this case 20 were performed – the “steps” parameter in the “KSampler” node) here each iteration takes 60-70 With. More than 20 minutes for one picture – what?!
Looking ahead a little, we point out that in order to fully justify such serious time spent on rendering images based on text prompts, FLUX.1 requires a much more complete disclosure of its potential – several examples of this will be given towards the end of this article. And the first step towards such disclosure is the transition from the single checkpoint flux1-dev-fp8.safetensors, which we just used, to a modular ensemble of submodels that together make up a single FLUX.1 [dev], namely, to separate application:
- Converters of text hints into tokens (and there are two of them!), conventionally called CLIP submodels,
- One UNet submodel (the name is also conditional), which actually extracts the prototype of the future image from the latent space in accordance with these tokens,
- And VAE submodels for converting the finished “latent” image into a pixel format suitable for opening in any suitable graphics editor.
60-70 s per iteration for FLUX.1 [dev] – this is normal for 8 GB of video RAM
On the same ComfyAnonimous page with examples there are the necessary links for downloading all submodels, both for FLUX.1 [dev] and FLUX.1 [schnell]. To begin, you will need to download at least two files from the CLIP submodel repository on Hugging Face: the required clip_l model – the clip_l.safetensors file (246 MB), as well as one of two options for the t5xxl model: the preferred one – t5xxl_fp16.safetensors (9.79 GB ) or twice shrunken (also through conversion from FP16 to FP8) – t5xxl_fp8_e4m3fn.safetensors (4.89 GB). It is recommended to use the 16-bit version, which, of course, will not fit entirely into our 8 GB of video RAM – and therefore its use will further lengthen the generation of images. However, in free search mode, when the working environment is launched into an infinite loop with a random change of seed and unchanged other parameters, you will only need to recode the text into tokens once for each hint – and therefore it makes no sense to sacrifice accuracy in this case. Moreover, the quality of the encoder’s work directly affects the quality of the final image as a whole, from composition to color palette, and not just fine detail, as in the case of the UNet submodel – so it’s worth betting on the almost 10 GB t5xxl_fp16 from the very beginning. safetensors.
⇡#Ears stick out
So, let’s place the two downloaded CLIP encoders in the ComfyUI/models/clip/ directory. Next, you will need to download the UNet model FLUX.1 [dev] – either from the BFL repository itself on Hugging Face, or from the page of the specified model on Civitai. This file (flux-dev.safetensors) in its original 16-bit encoding takes up 23.8 GB, and its FP8 version from an alternative repository (flux1-dev-fp8.safetensors) is 11.9 GB. You should place one of them (or both, if free space on the logical partition allows) – attention! – to the ComfyUI/models/UNet/ directory – exactly /UNet, not /checkpoints; precisely because this is not a fully functional separate checkpoint, but just one submodel from the ensemble. By the way, you should not confuse files with different sizes, but the same names “flux1-dev-fp8.safetensors”, located in the /checkpoints and /UNet folders: in the first there is a full-fledged checkpoint (obtained by ComfyAnonimous, presumably, by merging FP8 variants of CLIP submodels (large) and UNet with the addition of an almost weightless clip_l and the corresponding VAE file), and in the second – that same single UNet submodel. Let’s make a reservation here at the same time that the terminology adopted in this case is at least controversial: the T5XXL encoder model is not CLIP-like, and the FLUX implementation of image formation in latent space through transformers (which we briefly mentioned above) differs from UNet technology – but from a practical point of view this is not very significant.
Now all that remains is to download the VAE submodel from the official BFL repository on Hugging Face – this is a 335 MB file called “ae.sft”, which can either be placed as is in the ComfyUI/models/vae/ directory, or first renamed to “ae.safetensors” , – the current version of ComfyUI will accept both extensions. ComfyAnonimous also has a picture with a reference cyclogram for an ensemble of submodels – let’s drag it from Explorer to the work field and check whether all the names of the submodels in the corresponding nodes match those with which we are going to work. Just in case, it is better to click on the “Refresh” button in the working environment interface to update information about the contents of the directories. In the “Load Diffusion Model” node, for example, flux1-dev-fp8.safetensors (UNet version, not a full-fledged checkpoint!) should be selected, in the “DualCLIPLoader” node – t5xxl_fp16.safetensors and clip_l.safetensors in the required positions, and in node “Load VAE” – ae.safetensors. You don’t need to touch anything else – you can launch ComfyUI for execution.

At the top left is the reference generation from the reference cyclogram with the 16-bit flux-dev.safetensors model from the ComfyAnonimous manual; top right – the result of executing the same cyclogram with the UNet model flux1-dev-fp8.safetensors on our test PC, bottom left – also local generation, but with 16-bit flux-dev.safetensors, bottom right – the same hint, seed, CLIP versions and other generation parameters, but the main submodel is the FP8 version of FLUX.1 [schnell] (source: AI generation based on the FLUX.1 model)
For the FP8 implementation of FLUX.1 [dev] with an ensemble of submodels on our test PC, the average execution speed was 72 s per iteration. Decent, of course, but only slightly more than using the combined FP8 checkpoint with which we started. It is interesting that if instead of flux1-dev-fp8.safetensors in the “Load Diffusion Model” node you select the 16-bit UNet submodel flux-dev.safetensors (assuming that it was possible to pump out almost 24 GB of it without difficulty), the quality in the details is somewhat will improve – just look carefully at the irises of the fox’s eyes in the picture and at the frills of her apron – and the speed of execution will remain essentially the same, 74 s/it. And it’s clear why: the model for forming an image in latent space in both cases does not fit entirely into video memory, which forces the working environment to continuously transfer data between system and video RAM – against this background, the differences between 12 and 24 GB files are almost hidden. Now, if our graphics adapter had at least 12 GB of memory, the picture would be fundamentally different.
Let us briefly mention that FLUX.1 [schnell] on our test system (again, available from the already mentioned repository) also runs with a similar typical speed – 67 s/it. Of course, if you consider that it only takes 4 steps to complete the image, the total generation time is noticeably reduced. But the overall quality, i.e., the subjective aesthetic impact of the picture on the viewer, is, in our opinion, lower in the Schnell version (see the above comparison of generations obtained using different models), therefore, at least at this stage, we We won’t go into detail.
⇡#Have you ordered a quartet?
Another important point: if for SD 1.5 the basic native resolution was 0.25 megapixels (canvas 512 × 512 pixels), for SDXL – 1 megapixel (1024 × 1024), then FLUX was trained, according to the developers, on an extremely wide selection of test images with resolutions from 0.1 to 2.0 megapixels. In other words, without any additional funds – Hires. fix, ADetailer, etc. — the model immediately allows you to generate images on a canvas, say, 1920×1072 pixels (about 2 megapixels). With all the required detail, with the obvious absence of enlargement artifacts, etc. – although, of course, at the cost of even longer processing of each of the 20 basic generation steps. But, to be honest, sometimes it’s worth it: it was thanks to the outstanding abilities of FLUX.1 [dev] that literally on the third attempt we managed to get a completely adequate 2-megapixel picture of an eagle and a panda fighting. Albeit at a speed of 141 s/it., but practically in photo quality and without mutual contamination, which we never managed to achieve without the use of additional tools. And here – please, and even in such a large format!

Accurately separating significantly different objects in a picture without significant properties flowing between them – when a panda has an eagle head, an eagle has black clawed paws, etc. – for the SD 1.5 and SDXL models the task is almost impossible: their CLIP encoders are simply not designed for similar challenges. SD3M has achieved undeniable progress in this regard, as we showed last time, precisely thanks to the involvement of three encoders at once, including T5XXL. But FLUX.1 reaches a height that is truly unattainable in this regard – at least for other freely distributed models that can be run on the most powerful gaming PC.
Let us illustrate this bold thesis with an example of a picture inspired by the famous Krylov fable “Quartet”. Let us remind you that the composition of a classical string quartet includes two violins, a viola and a cello, and most often they depict a clumsy bear with a cello (English cello), a goat with a viola (viola), and a violin is given to a naughty monkey and a donkey. . Let’s say the monkey should play not a full-size instrument (violin), but a “folk”, simpler version (fiddle), and we will compose the following not too lengthy, but replete with details hint:
Hyperrealistic digital painting of four animals standing upright on a flower-strewn lawn: donkey, monkey, bear, and goat. The donkey plays violin, the small monkey plays fiddle, the huge bear plays cello, the goat plays viola
And here you go: after about the fifth time, the system generated from it an image that almost exactly matches the description – which would be strange to expect even from SD3M. Here, even the monkey almost drops his bow, even the bear taps on the cello, like a real jazz bassist on the double bass – that is, this image would be quite suitable as an illustration for the original fable. This picture in its original form (a PNG file with a built-in cyclogram, which you can simply drag and drop onto the ComfyUI workspace for further experimentation), like the other generations presented here based on the FLUX model, can be downloaded for independent study.

The generation parameters are almost standard (as in the ComfyAmonimous reference cyclogram for the dev version), only in the “BasicScheduler” node the “beta” option is selected; model – FLUX.1 [dev] 32 bit, seed – 368019150651752, hint – in the text of the article (source: AI generation based on the FLUX.1 model)
Strictly speaking, this is just the beginning of our acquaintance with FLUX.1 [dev]. This model, recall, has two CLIP encoders of text into tokens – and, as practice shows, setting hints for them separately (mutually agreed upon, but different) provides better results than using the same text for both, as implied by the reference ComfyAnonimous nodes in the examples we looked at. There is also a complete absence of a negative hint – not because the model does not know how to remove certain entities from the picture, and not just add them, but because the CFG parameter in the reference cyclograms is set equal to one – and this is a fundamental point; at higher values, the system literally breaks down. Applying a negative hint to an image extracted from the latent space requires setting CFG at least to position 2 – and therefore there is simply no point in working with an additional node. Yes, there are already ways to get around this limitation and still make FLUX.1 [dev] work with negations, but they are quite non-standard.
Further: among other nodes in the cyclograms there is one that none of the Stable Diffusion models had – it sets a “recommendation”, guidance, with a default value of 3.5. It turns out that lowering this value leads to greater creative freedom for the model due to increased deviation from a given hint, and increasing it, on the contrary, leads to an even more literal adherence to it (but with a decrease in detail). This is a kind of analogue of the previous CFG parameter, the meaning of changing which was approximately the same, but which now, taking into account the seriously redesigned architecture of the model, plays a noticeably smaller role (and this is precisely why the developers recommend setting it strictly to “1”). In addition, there is another new “ModelSamplingFlux” node: the parameters specified in it are of particular importance when working with non-standard canvases – with previous models there was no need for such adjustment.
There are many more subtleties with the use (not to mention training) of LoRA for FLUX.1, with ControlNet models specifically for it, with cascade generations – when, for example, the first run is made with a high guidance value in order to accurately record the basic ones specified in the hint elements of the picture, and the second (in the mode not text to image, but image to image) takes the output of the first as a basis and, with a low value of guidance, enriches it with all sorts of extraordinary details… And this is not to mention the more effective methods for compacting the original image than FP8 model file, which still allow you to fit a fully functional UNet (which in fact, as already mentioned, is not quite a UNet) into 8, 6 and even 4 GB of video RAM. And we will certainly talk about this – and not only about this!
Related materials:
- The startup Black Forest Labs introduced the AI image generator FLUX.1 – it does an excellent job of drawing human hands.
- Google has overdone its AI image editor Reimagine – it produces too realistic results.
- The Procreate graphics editor will not receive generative AI, since this technology is “based on theft.”
- Stability AI introduced Stable Fast 3D, an AI tool for quickly creating 3D images.
- Adobe has added more AI features to Illustrator and Photoshop.