The latest version of the large language model, Gemini 1.5 Pro, has suddenly shot to the top of the rankings on the Chatbot Arena platform, beating traditional leaders in the field of generative artificial intelligence – OpenAI GPT-4o and Anthropic Claude-3 in tests.

Image source: blog.google
The previously champion OpenAI GPT-4o neural network lost its leadership on August 1, when Google quietly released an experimental build of its latest model – it quickly attracted an AI-interested community on social networks, which considered victory in the benchmark a testament to quality. OpenAI ChatGPT has become almost synonymous with generative AI since its launch back in the GPT-3 era. To date, OpenAI GPT-4o and Anthropic Claude-3 are considered established leaders, which over the past year have had almost no competitors in tests.
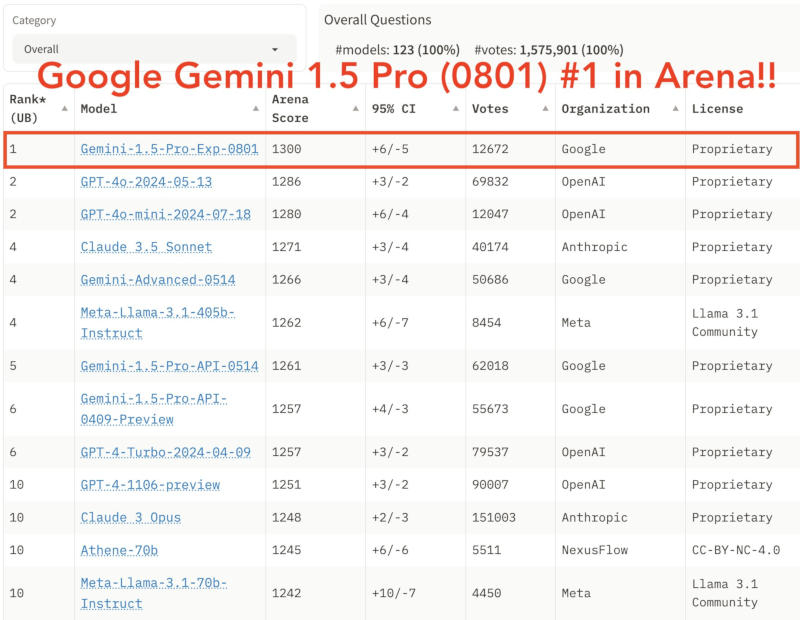
Image source: x.com/lmsysorg
One of the most popular tests is LMSYS Chatbot Arena. It offers models various tasks and assigns them scores. The current version of GPT-4o was able to score 1286 points, and Claude-3 – 1271 points. The previous Google Gemini 1.5 Pro had a score of 1261, but the Gemini 1.5 Pro 0801 released on August 1 suddenly scored a whopping 1300 points. This may indicate that Google’s new neural network is more capable than its competitors, but benchmarks don’t always accurately reflect what an AI model can and can’t do.
Today’s chatbot market is mature enough to offer the consumer multiple options and allow them to decide for themselves which AI is best suited. It is not yet clear whether the experimental Gemini 1.5 Pro will become the default version in the future. It remains publicly available, but with experimental status may be closed or radically edited for security or other reasons.