Google has unveiled Gemma 2 2B, a compact yet powerful artificial intelligence language model (LLM) that can compete with industry leaders despite its significantly smaller size. With just 2.6 billion parameters, the new language model delivers performance on par with much larger peers including OpenAI GPT-3.5 and Mistral AI Mixtral 8x7B.

Image source: Google
In the LMSYS Chatbot Arena test, a popular online platform for benchmarking and assessing the quality of artificial intelligence models, Gemma 2 2B scored 1130 points. This result is slightly ahead of the results of GPT-3.5-Turbo-0613 (1117 points) and Mixtral-8x7B (1114 points) – models with ten times more parameters.
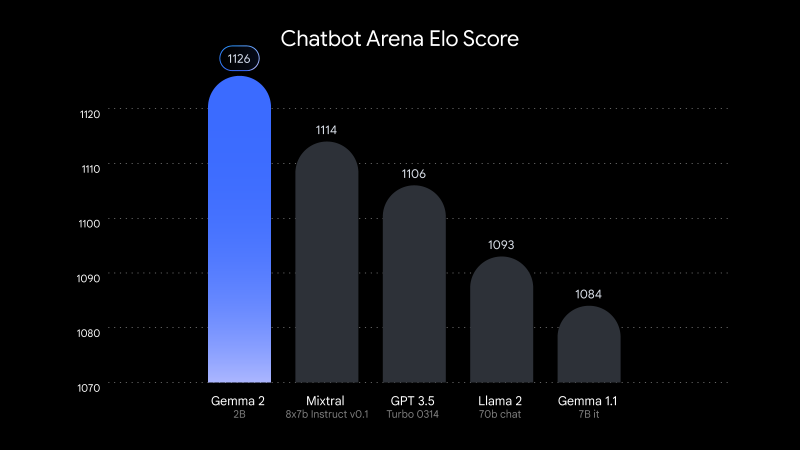
Google says Gemma 2 2B also scored 56.1 on the MMLU (Massive Multitask Language Understanding) test and 36.6 on the MBPP (Mostly Basic Python Programming) test, which is a significant improvement over the previous version.
Gemma 2 2B challenges the conventional wisdom that larger language models inherently perform better than smaller ones. The performance of Gemma 2 2B shows that sophisticated training methods, architectural efficiency, and high-quality datasets can compensate for the lack of parameters. The development of Gemma 2 2B also highlights the growing importance of AI model compression and distillation techniques. The ability to efficiently compile information from larger models into smaller ones opens the door to more affordable AI tools without sacrificing performance.
Google trained Gemma 2 2B on a massive data set of 2 trillion tokens using systems powered by its proprietary TPU v5e AI accelerators. Support for multiple languages expands its potential for use in global applications. The Gemma 2 2B model is open source. Researchers and developers can access the model through the Hugging Face platform. It also supports various frameworks, including PyTorch and TensorFlow.