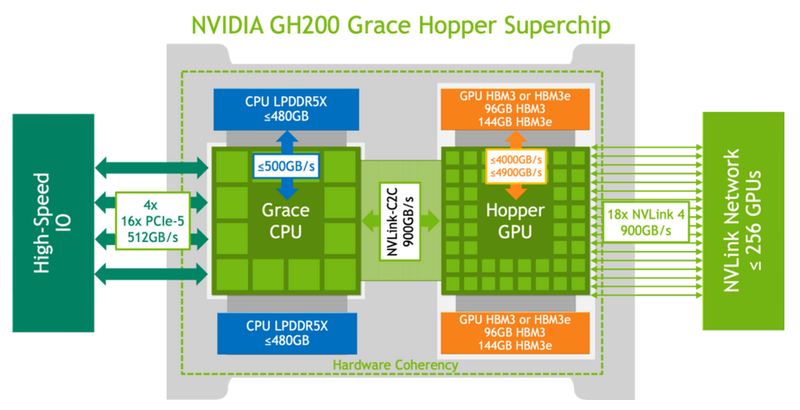
The NVIDIA Grace Hopper hybrid accelerator combines CPU and GPU modules, which are connected via the NVLink C2C interconnect. But, as HPCWire reports, there are some nuances in the structure and operation of the superchip, which were described by Swedish researchers.
They were able to measure the performance of the Grace Hopper memory subsystems and the NVLink interconnect in real-life scenarios in order to compare the results obtained with the characteristics declared by NVIDIA. Let us remind you that the speed of 900 GB/s was initially stated for interconnection, which is seven times higher than the capabilities of PCIe 5.0. The HBM3 memory as part of the GPU part has a bandwidth of up to 4 TB/s, and the version with HBM3e already offers up to 4.9 TB/s. The processor part (Grace) uses LPDDR5x with memory bandwidth up to 512 GB/s.
In the hands of the researchers was the basic version of Grace Hopper with 480 GB LPDDR5X and 96 GB HBM3. The system ran Red Hat Enterprise Linux 9.3 and used CUDA 12.4. In the STREAM benchmark, researchers were able to obtain the following bandwidth indicators: 486 GB/s for the CPU and 3.4 TB/s for the GPU, which is close to the stated characteristics. However, the resulting speed of NVLink-C2C was only 375 GB/s in the host-to-device direction and only 297 GB/s in the reverse direction. The total output is 672 GB/s, which is far from the stated 900 GB/s (75% of the theoretical maximum).
Source: NVIDIA
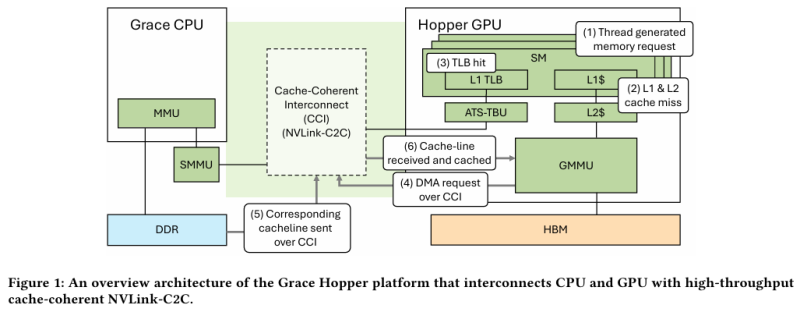
Grace Hopper, by design, offers two types of tables for memory pages: a system-wide one (4 KB or 64 KB pages by default), which covers the CPU and GPU, and an exclusive one for the GPU part (2 MB). In this case, the speed of initialization depends on where the request comes from. If memory initialization occurs on the CPU side, then the data is by default placed in LPDDR5x, to which the GPU part has direct access via NVLink C2C (without migration), and the memory table is visible to both the GPU and CPU.
Source: arxiv.org
If the memory is managed not by the OS, but by CUDA, then initialization can be immediately organized on the GPU side, which is usually much faster, and the data can be placed in HBM. In this case, a single virtual address space is provided, but there are two memory tables, for the CPU and GPU, and the mechanism for exchanging data between them involves page migration. However, despite the presence of NVLink C2C, the ideal situation remains when HBM is enough for GPU loads, and LPDDR5x is enough for CPU loads.
Source: arxiv.org
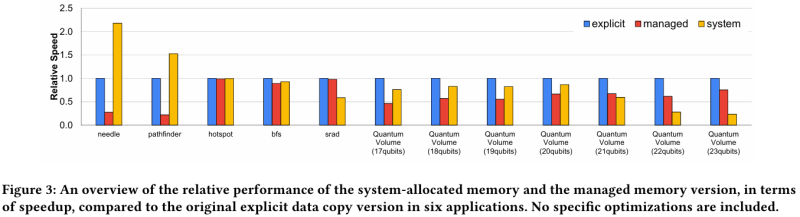
The researchers also addressed the issue of performance when using memory pages of different sizes. 4 KB pages are usually used by the processor part with LPDDR5X, and also in cases where the GPU needs to receive data from the CPU via NVLink-C2C. But as a rule, in HPC workloads it is optimal to use 64 KB pages, which require fewer resources to manage. When memory access is chaotic and inconsistent, 4 KB pages allow for finer control of resources. In some cases, a 2x performance benefit is possible by not moving unused data across 64 KB pages.
The published work notes that further research will be required to gain a deeper understanding of the mechanisms of unified memory in heterogeneous solutions like Grace Hopper.